
So the installer doesn't work yet, but for MySQL everything else should. For those who want to try it out, you can check out a copy of Drupal with the new database code in it from chx's public svn repository: https://4si.devguard.com/svn/public/pdo . A proper patch will be forthcoming as soon as the installer works, which should be Very Soon Now(tm). For a complete list of the new features it offers, see: http://www.garfieldtech.com/blog/drupal7-database-update .
If you want to help with the installer, let chx know so he can give you commit access to it. :-)
This patch will also deprecate about a half-dozen old feature requests for the database layer, as it works a whole bunch of features into one cohesive system. I'll go flag those as duplicate shortly.
| Comment | File | Size | Author |
|---|---|---|---|
| #331 | dbtng.patch | 387.63 KB | chx |
| #325 | dbtng.patch | 385.16 KB | chx |
| #324 | dbtng.patch | 385.18 KB | chx |
| #323 | dbtng.patch | 385.55 KB | chx |
| #320 | dbtng.patch | 385.57 KB | chx |









{kind=link}
Comments
Comment #2
antgiant CreditAttribution: antgiant commentedsubscribing.
Comment #3
hass CreditAttribution: hass commentedsubscribing.
Comment #4
Wim LeersSubscribing.
Comment #5
hswong3i CreditAttribution: hswong3i commentedsubscribing.
Comment #6
chx CreditAttribution: chx commentedFor those following at home: I just installed Drupal with the new layer (and previous tests as long as a week ago showed installed Drupal working). We still need to work on error handling.
Comment #7
AjK CreditAttribution: AjK commentedyes, another "subscribing" (with hopefully more informative followups :)
Comment #8
chx CreditAttribution: chx commentedWe have the system installing and reinstalling, users, node and upload tests are passing. When all tests pass I will submit the patch, not until. It's close, though.
Comment #9
jaydub CreditAttribution: jaydub commentedsubscribing
Comment #10
Susurrus CreditAttribution: Susurrus commented@chx: Where are those tests that are failing, or are you just talking in general that not everything's working? If there's a list of what's wrong, I'd like to pitch in.
Comment #11
Crell CreditAttribution: Crell commented@Susurrus: Right now we're going through module by module in SimpleTest and finding problems. Usually it's because the backward compatibility layer we've included can't handle every edge case, so some queries need to be updated to the new format anyway. I think we're over half way through. The biggest roadblock right now, I think, is figuring out what to do with pager_query(), which right now is all kinds of manual weird ugliness that is frequently dynamically built, badly. The new system has its own "real" query builder, but I'm not yet sure how we're going to handle pager_query(). It may end up being a special case of the query builder.
If you do a checkout of the svn repository mentioned in the first post, you can see the current status of the code. The installer works, so go ahead and run it. Start running SimpleTests, find places that fail, and let us know / convert the queries as needed. Either of us is in IRC on and off throughout the day if you need help. Thanks!
Comment #12
alippai CreditAttribution: alippai commentedI'm new to PDO, but I thought that FETCH_ORI_ABS, FETCH_ORI_REL do the same as the pager_query().
Comment #13
Crell CreditAttribution: Crell commentedNo, that's something else, actually. That's for fetching an arbitrary row from a result set. pager_query() dynamically specifies the LIMIT and ORDER BY portion of the query based on user input.
Comment #14
hswong3i CreditAttribution: hswong3i commentedHope to mention that we still have an alternative choice of PDO implementation from http://drupal.org/node/172541, which based on existing DB API architecture plus totally 5 databases supporting. I think both issues have no conflict and should able to contribute for each other, e.g. this issue target for ORM/active record/PDO, but the other focus on multiple database supporting plus backward compatible. Hope we may have more join development for better implementation.
Comment #15
bdragon CreditAttribution: bdragon commentedsubscribing
Comment #16
chx CreditAttribution: chx commentedSmal, trivial patch, hardly needs any explanation.
Comment #17
Crell CreditAttribution: Crell commentedIt may not need an explanation, but I'll offer one anyway. :-)
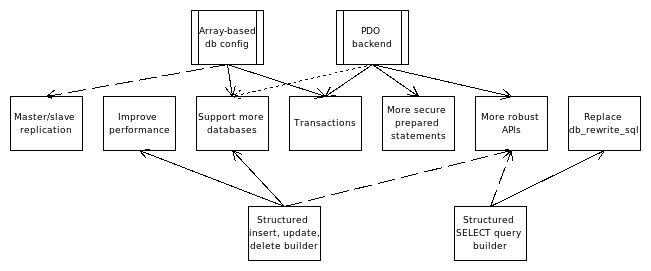
This patch does the following related tasks:
OK, so, why? Well, here's a list of features that this architecture allows:
hook_query_alter(). 'nuff said.Later follow-ups can also offer the following, but we wanted to get the base system in place first.
db_rewrite_sql()in favor ofhook_query_alter()We've already run extensive SimpleTests on this patch, and it is extremely stable. There's a few edge cases being investigated, but all functionality should work as is.
I've tried to provide copious inline documentation. I think the patch is more documentation than code, actually. Architectural and usage-guide docs will be forthcoming, but I didn't want to spend too much time on those until the patch was out and written.
Committers: Although I've been working on this for a while, it would not be anywhere near as powerful or stable without chx's help this past month. Please credit him as co-author.
Review please. :-) (Attached patch has some cosmetic changes.)
Comment #18
chx CreditAttribution: chx commentedAbout stability. This patch passed all existing simpletests plus the pager one I have even written for it -- with two exceptions: one, if locale is not enabled the modules test fail -- but manually doing the same does not fail. As simpletest had module issues recently, I am not worried, Two, blogapi fails in HEAD and I have not yet figured it out why so it fails with this one too. Aside from that all simpletests work.
Comment #19
David StraussThis patch implements my object-based transaction system, so I of course support that. :-) Reviewing this patch will give me something to do on the plane to Drupalcon.
Comment #20
Dries CreditAttribution: Dries commentedBig patch, I'm reviewing it (slowly).
Comment #21
Dries CreditAttribution: Dries commentedJust curious but did we do any performance comparisons? This patch has the advantage that we can exploit database specific optimizations, but at the same time, how much slower did the average select query became? Do we have any early insight in this?
Comment #22
chx CreditAttribution: chx commentedajk did benchmarks a few days before the patch was rolled and he found that there is no slowdown and sometimes there is some speedup. the patch is not really about performance but features. Of course, we took as much care as possible with performance, for eg. not using native prepared statements for mysql because those are not cached by mysql.
Comment #23
AjK CreditAttribution: AjK commentedAs chx's mentions, I've been looking at how it performs for a while now as the question was going to be asked sooner or later. And since HEAD hasn't deviated too far from Drupal 6 now is a good time to publish some results so far. Rather than clog up this issue with lot's of performance/profile related junk I created a more detailed post here:- http://drupal.org/node/229132
If anyone wants more info, drop me a line. I'll continue to profile this patch as it matures but based on the forum post above it's a +1 from a performance angle at the moment at least.
Comment #24
David StraussHere's a few things I came up with on the plane.
Functional problems:
* Functions and variables are CamelCase, which isn't Drupal style.
* Transaction object doesn't handle nested transactions properly. It needs a static counter.
* Doesn't implement LOW_PRIORITY for UPDATEs, even though DELAYED is supported.
Questions:
* Does the inheritance of PDO allow freeing result sets?
Comment #25
chx CreditAttribution: chx commentedAbout CamelCase, we feel that as PHP largely uses CamelCase for its objects while it uses lowercase for functions so we though we will adopt. LOW_PRIORITY would be easy to support but what's the point...? What do we gain by supporting it?
Comment #26
David StraussRegarding LOW_PRIORITY, I just think that we should be consistent in support of non-standard MySQL extensions. If we support DELAYED, I think we should support the other options.
Comment #27
pwolanin CreditAttribution: pwolanin commentedsubscribe
Comment #28
mike booth CreditAttribution: mike booth commentedsubscribing
Comment #29
chx CreditAttribution: chx commentedDELAYED is extremely useful for performance so we are supporting it -- do we really want to debate this in this issue? is this the big issue w/ this? can't we have a followup issue ?
Comment #30
kingto CreditAttribution: kingto commentedhello Strauss,
several days ago, i had sent a letter to your mailbox: shout at thatotherpaper dot com.
i hope that you can reply it.
many thanks.
Comment #31
Crell CreditAttribution: Crell commented@DavidStrauss: How useful is LOW_PRIORITY to Drupal in practice? IMO, we should support SQL features that are of value to Drupal. INSERT DELAYED (or an equivalent functionality in another database) has a very definite benefit for logging, caching, etc. Where would we use LOW_PRIORITY?
Comment #32
BioALIEN CreditAttribution: BioALIEN commentedSubscribing. I agree with only supporting features of benefits. If there's no real use in supporting LOW_PRIORITY lets keep it out. It can always land at a later stage once this gets in.
Comment #33
bjaspan CreditAttribution: bjaspan commentedSubscribe. I've started reviewing this patch. I already have a list of comments; no show-stoppers but some things to fix.
Comment #34
jgoldberg CreditAttribution: jgoldberg commentedOK, I'm really late to this thread. Bear with me. Can someone explain why replication (and the major changes that come with it, like db_select() vs. db_update()) outweighs a solution like memcached, which many would argue is a much simpler solution to scaling than clustering? It doesn't seem like MySQL Clustering is that impressive -- and for obvious, fundamental reasons relating to the challenges of master-master, master-slave db replication, and it costs you a whole lot of new code complexity.
Comment #35
David Strauss@Crell I agree that it's much less useful. I was arguing from API consistency, not pragmatism. I won't be offended if we leave out LOW_PRIORITY support; I just want it to be a conscious decision.
Comment #36
pwolanin CreditAttribution: pwolanin commentedshould this patch include this fix? http://drupal.org/node/220064
Comment #37
bjaspan CreditAttribution: bjaspan commented@36: I don't think so. The bug in #220064 is that a query is broken: it is treating strings and ints as directly comparable, and the latest PostgreSQL is picky enough to complain about it (as opposed to mysql that will sleep with anyone it can recognize). Arguably, the query is broken because our schema is broken. But in no case does our API to execute queries have anything to do with this.
Someone might argue that we should use schema information to automatically cast data types when necessary to make queries like this one work. I'd say no; the solution is not to write broken queries.
Comment #38
pwolanin CreditAttribution: pwolanin commented@bjaspan - if it should not be included, let's move that patch to 6 .x and get it in sooner.
Comment #39
AjK CreditAttribution: AjK commentedRegarding DELAYED, are we ok that it's not supported on InnoDB ?
http://dev.mysql.com/doc/refman/5.0/en/insert-delayed.html
Something somewhere reminds me d.o is using InnoDB tables for something. Not sure if this is/was the case though.
Comment #40
chx CreditAttribution: chx commentedCould we please stop painting the bikeshed? If not, I am perfectly happy to roll a patch without INSERT DELAYED if that's needed to move on but really, instead of painting the bikeshed, let's discuss the atomic plant:
Comment #41
Anonymous (not verified) CreditAttribution: Anonymous commented@AjK: No, I'm not happy with it. If core is depending on MySql extensions then it is just plain wrong. I use InnoDB exclusively because the shear numbers of data requires me to use transactions. Also, note, that if the reason for using INSERT DELAYED is the logging processes then the queued delayed inserts may not make it at all to the DB and therefore make it harder to debug issues.
Comment #42
bjaspan CreditAttribution: bjaspan commentedMy review is still underway and I have some feedback that will require changes (nothing show-stopping), but one immediate issue is that the schema.inc and schema.*.inc files are missing from the patch. Could we have a new patch file including them?
You may find cvsutils (http://www.red-bean.com/cvsutils/) helpful in tricking CVS into including newly created files in a cvs diff. I had to do this for the Schema API patch.
Comment #43
keith.smith CreditAttribution: keith.smith commentedAlso, if at some point in the future this patch is sitting still for a while, I'll volunteer to go through and make (just a few) changes for further compliance with coding standards. From what I've seen so far, there are really very few "nitpicky" changes that need to be made, and the code comments are excellent. The biggest offender I've seen so far is two spaces between most sentences, rather than core's preferred one.
Comment #44
Gerhard Killesreiter CreditAttribution: Gerhard Killesreiter commentedWRT to ajk's question in #39: Yes, drupal.org indeed uses innodb for everything but the search tables (which are myisam). However, I don't think that using insert delayed would be a problem for e.g. watchdog inserts. We should use the archive type which is IMO more suitable for this.
Comment #45
AjK CreditAttribution: AjK commented@chx in #40. Ticks to 1, 2 and 3.
The patch came in at #17 and this is now #45 without a re-roll/etc. I can see DELAYED is supported but it's not actually used by Core. If it's the only stumbling block so far congratulations to Crell and Chx on some fine work.
Remove INSERT DELAYED if it will settle things if you like, call it a natural finish and get it committed. I'm sure Keith would be rather rolling his patch to remove extraneous spaces/lines against HEAD.
We all just need somewhere to park our bikes ;)
Comment #46
AjK CreditAttribution: AjK commentedp.s. assuming we get the missing files bjaspan refers to.
Comment #47
bjaspan CreditAttribution: bjaspan commentedThe patch is not ready to apply in its current state. I set it to CNW for a reason. I plan to finish my initial review and post the results tomorrow at the code sprint.
Comment #48
recidive CreditAttribution: recidive commentedI personaly don't like classes, at least for what developers will actually use (although I think this whole abstraction is completly doable with functions). And I don't see much value in chainable methods (specifically on
db_insert()calls). Some examples:How this differ, from:
is there cases when the following syntax is necessary?
Or is there cases when you want to call
$foo->execute()before setting fields using$foo->fields()? IMO this:db_insert('my_query', 'node')->execute()->fields($fields);doesn't make any sense and it doesn't works as jQuery's chainable methods does, i.e. the order is not important unless you are filtering/traversing DOM elements.And for the
duplicateUpdate($update_fields)method. Is there cases where$insert_fieldswithout the keys is different from$update_fields? If not, sodb_insert()should be capable of knowing where a record already exists, and do run a UPDATE if so. So thedb_insert()should be renamed to something else likedb_save()ordb_write()as it not only does INSERTs but UPDATEs too.Batch UPDATEs seems to be a case for chainable methods in
db_insert()however I don't see any example of this use in the patch.What's the problem with a
$paramsarray with conditions and other properties for doing a select?My opinion is that we need to provide a simple interface for trivial tasks, not enforce users to write complex code for very simple data manipulation stuff.
Comment #49
cburschkaSubscribing.
Interesting pattern question there, especially in light of Drupal's stance on OOP.
Chained methods are neat - jQuery does everything like this. But can we mix patterns like this in Drupal too? Calling member methods on the return value of other functions strikes me as fitting more appropriately into prototype-oriented programming than either functional or object-oriented programming... but I'm not well-versed in patterns.
Comment #50
Anonymous (not verified) CreditAttribution: Anonymous commented@Gerhard: Did you see my response in #41? You state the opposite as I when I give a reason for not using DELAYED for watchdog (well, I called it "logging processes"). If php or mysql aborts the messages are likely not to be captured to the table that have already been written. I don't think we want this even in a production system. I've found many problems looking at the watchdog log of my production system. Production systems usually contain more activity and prove to contain nuances that development and test systems do not by nature have.
@chx: I do not care whether objects are used so +1 for that. I do not care that CamelCase or even mixedCase is used as long as we all agree to modify the Drupal Coding Standard so +1 for that. And I'm not sure about the chainable query builder; recidive made some interesting points. As long as we have improved performance and improved multiple engine support with ease of use I can live with the changes. I'm using Drupal DB API to process 100K rows daily in batch and then processing the changes as nodes daily; some days the node changes could be near the 100K mark as well. All the nodes have a minimum of four terms and pathauto is setup to add path aliases. I need performance most of all.
Comment #51
chx CreditAttribution: chx commentedHere is what InsertQuery::fields says: "This method may be called multiple times. If it is, multiple sets of values will be inserted. The order of fields must be the same each time.". That's useful, isn't it? PDO already uses objects and methods and we would need to provide a wrapper for each -- we thought that's not the best.
Comment #52
recidive CreditAttribution: recidive commentedChanging back to 'code needs work' as in #47.
Comment #53
Crell CreditAttribution: Crell commentedRegarding INSERT DELAYED: Non-InnoDB tables will work fine with DELAYED, they just won't actually delay. There is no performance cost here, just a performance gain. Non-MySQL databases can ignore the DELAYED flag if they don't care or use whatever their native equivalent is, if it has one.
Regarding using OOP: PDO itself is completely OOP. Making the internal API OOP makes the code easier and cleaner, and more flexible. This is a case where using a table saw instead of a screwdriver makes a great deal of sense. Drupal's coding standards will also need to be clarified to ClassName::methodName(), which is the nearly universal standard for OOP, PHP or otherwise.
Regarding the Fluent API: That was used for 2 reasons: Flexibility and terseness. The original version of the API did take the $fields array directly in the constructor. That was factored out in order to allow for multi-insert statements, which does improve performance. (How it does so will vary with the database, but it should always be a win or at least a wash.) Also, jQuery methods do care about order. Think filter(), find(), etc. We're not going quite that complex.
Regarding duplicateUpdate(), we are going to modify it to specify the key fields to make the operation easier (vis, doesn't require hitting schema API) on non-MySQL databases. I may rename the method.
I agree with Barry about it not being the job of the API layer to fix broken queries.
Comment #54
Crell CreditAttribution: Crell commentedBarry's having some wireless issues at the code sprint (as are most people), so below are his comments, passed via sneakernet:
# General
Big patch, long review.
This is a read-only review (I have not yet run any code) and I've only gotten through the files listed below after one hash (e.g. # database.inc).
I do not (yet) love the query builder interface but I do not (yet) hate it either. Some general comments:
* My big concern is that having to construct $fields (and possibly $update, though see below) separately from the query-builder logic spreads the information about the query out in a way that will make it harder to interpret code quickly.
* Passing $fields as ($key => $value) requires that the caller construct the array from data it probably already has in non-array form. Then, the called function (e.g. InsertQuery::fields()) then splits it apart again! This seems wasteful. If it is easier/more natural for callers to pass fields and values as varargs (I think it is), and it is less work for member functions to use the args in that format, then why not just do it that way? e.g.
db_insert($id, $table)->fields('foo', 'bar)->values($foo, $bar)->execute();
* I think Henrique's suggestion of direct auto-executing functions is useful because these simple operations are very common:
* One part I really do hate is anything that forces me to use named parameters. Sure, it's incredibly useful in some situations, but it is unnecessarily verbose for others. But I haven't actually used this API enough yet to have a firm opinion.
includes/schema.inc and includes/schema.*.inc are missing from the patch, so I am highly confident that no one else has reviewed them yet. :-)
Wrap all comments to 76 characters. I can do this easily in emacs if you want.
# default.settings.php
Comments on:
$databases['default']['default'] seems unnecessary given that $databases['extra'] works. Why not $databases['default'] by itself?
# database.inc
## abstract class DatabaseConnection
function transactions() is not a great name; it is ambiguous. We could use transactionsSupport() or hasTransactions() or a variety of more-clear choises.
In fact, abstract function supportsTransactions() is declared later in the file. So function transactions() is probably just obsolete.
Transaction support is not necessarily a property of a database engine; with mysql, it is a property of the table engine type (right?). I do not know how this works with mixed-engine-table queries/databases. This function may need a more expressive interface.
beginTransaction() is specified to "succeed silently" if transaction support is not available. However, if someone writes code that requires transactions for proper behavior (e.g. they assume that rollBack() will work), "silent success" without transactions is the wrong behavior. beginTransaction() should should accept a boolean, $required = FALSE, which when TRUE says it should return an error code indicating that transactions are not available. That way, the module can refuse to work instead of just breaking.
runQuery(): If the $statements cache stored the un-prefixed version of queries (instead of prefixed, as it now does), prepared statements could be retrieved without the overhead of prefixing first.
prefixTables(). This is just copied from database.inc, but the array_key_exists('default', $db_prefix) block has redundant code and could be improved. OTOH, it works.
query(): @return doc is less informative than runQuery(). Why?
## class Database
fetchAllAssoc(): This method overwrites values if keys are duplicated ($data[$key] = $record). We could easily provide a fetchAllAssocMult() that returns all records in an array: $data[$key][] = $record. Could be useful for multi-object loads.
## interface QueryConditionInterface and class DatabaseCondition
condition($field, $operator = NULL, $value = NULL, $num_args = NULL)
"This method can take a variable number of parameters. If called with two parameters, they are taken as $field and $value with $operator having a value of =."
Please, please, please do not create a new interface with crazy semantics like having the second operator be $value if two are provided or $operator if three are provided. Yuck.
Suggestion: condition($field, $value, $operator = NULL). So you'd say condition('created', time(), '<') for "created before right now". For the common case of "=", there is no change. But we avoid a multiply-interpreted set of arguments.
DatabaseCondition::_DatabaseCondition()
If $process_type (e.g. num_args) is 1, it treats $field as something other than a string. This is not documented behavior.
## class Query
parseWhere() turns a data structure into a string. It should be called unparseWhere() or __toString().
UPDATE and DELETE queries can require joins (I've written Drupal modules that use and depend on this) but this functionality does not appear to be supported. It isn't clear why not; the join code is already in class SelectQuery, it could be moved up to Query (it is meaningless only for Insert which could fail if there are any). Or you could derive {Select,Update,Delete}Query :: JoinQuery :: Query.
## class InsertQuery
If each sub-array in $insertValues is key-value, why must it match the order of fields in $insertFields? I guess you want to be able to do INSERT INTO table (iterate over the fields) VALUES (iterate over the values), but you could also just iterate over $insertFields as keys for the $insertValues block, no?
Actually, the doc says "$insertValues itself is an array of arrays. Each sub-array is an array of field names to values to insert." But actually, $this->insertValues[] = array_values($fields). Am I confused or is the doc wrong?
The paradigm of passing ->fields($fields) requires that the caller assemble an array($key => $value) just so that ->fields() can dis-assemble it and re-assemble it again in a slightly different form. The caller's work is unnatural and inconvenient anyway. So why not just pass an array of fields and an array of values (indexed or named)?
Same applies to UpdateQuery.
## class UpdateQuery
InsertQuery and SelectQuery fields() functions add to the list of fields, but UpdateQuery()'s resets the list of fields. This is incongruent.
The duplicateUpdate() interface is not quite right yet. It is cumbersome and inelegant to have to construct two separate $fields and $update arrays since they almost always have nearly the same content (for keys, that is).
In most cases, an "update or insert" query wants to set all the same fields for update that would have been set by insert, using the primary key for the UPDATE WHERE clause. Sometimes (e.g. for timestamps), the update wants to exclude a small set of fields. Less often (I can't think of an example offhand), the update wants to exclude almost all fields, updating only a couple.
I therefore suggest replacing duplicateUpdate() with two functions:
orUpdate($fields = NULL) performs the fallback update, updating only those fields specified in $fields. If $fields is a string, it is converted to a one-element array. If $fields is empty, all fields passed to fields() are updated.
orUpdateExcept($fields = NULL) performs the fallback update, updating all fields passed to fields() except those in $fields. If $fields is a string, is a converted to a one element array; this is useful because often you just want to skip updating a single field (e.g. timestamp).
For example,
would be replaced with
and could also be replaced with the more intuitive
If, however, we decided that when updating a cache entry the 'created' field should remain unchanged, we would write:
With duplicateUpdate() or orUpdate*(), non-mysql database drivers will have to retrieve the schema to determine the primary key(s) in order to generate the appropriate queries. This will take some time. It's great to have this info come automatically from the schema, but since these are for run-time queries we may want to benchmark the difference vs. specifying the keys explicitly to these functions.
## class SelectQuery
Should countQuery() know when just changing to COUNT(*) will not work (e.g. when there is a GROUP BY) and return an error/throw an exception? If/when this supports sub-queries, it could also just be SELECT COUNT(*) (SELECT original query).
fields() takes varargs, incongruent with Insert and Update. Maybe this is inevitable, but above I suggest changing the semantics of fields() for Insert and Update anyway.
Other __constructors take the table to operate on. This one does not, and seems to want a special-case join() call (condition and values ignored) to set the base table. Why not just accept the base table in the constructor? Yes, it would need to accept an optional alias as well.
The "first join sets the base table" makes no sense for leftJoin() and rightJoin(). This is a good reason to set the base table in the constructor.
Should we support full outer joins? Granted, no one ever uses them, but it is easy enough to do.
addJoin() doc does not list $type.
having() docs says: "@param $snippet. A portion of a HAVING clause as a prepared statement." What is "a portion ... of a prepared statement"?
__toString(): appends "$params['type'] .' JOIN '" but $params['type'] already contains "JOIN". So, ummmm, I do not see how any join query can work currently. :-) Like I said, though, this is a read-only review so far.
## db_* and other top-level functions
The comments on db_and() and db_or() are reversed, or I'm confused, in which case they should be clarified to explain the apparent reversal.
db_query() and friends wrapper functions duplicate some query-string-processing code that could be shared.
db_rewrite_sql() is clearly deprecated, but how is node_access going to decide what node queries to modify and which not? You can't just use the fact that node is the primary table; some queries want all nodes regardless of access rules. Can I set $options['node_access'] = TRUE or something if I want the node access rules to apply? Then the node_access module would just look for that option tag.
db_distinct_field(): Does this mean anything? I thought DISTINCT was a query-level property, not a field-level property.
## Schema functions
db_field_names(): This is a Schema data structure operation. It should not be db-specific and does not need to be dispatched. database.inc (or schema.inc) should provide the one implementation.
# database.mysql.inc
## DatabaseConnection_mysql
queryTemporary(): runQuery() runs prefixTables() so why does this function need to also?
escapeTable(): No different than the function it overrides.
execute(): Does not call drupal_alter('query').
__toString(): Remove spaces from ' DELAYED '.
Comment #55
bjaspan CreditAttribution: bjaspan commentedI am going to work on a pgsql driver at code sprint today.
Comment #56
recidive CreditAttribution: recidive commented#17.11. "A Fluent API query builder for SELECT statements that weighs in at only a few hundred lines (not counting comments). It doesn't replace the Views query builder, yet, but I will be working with merlinofchaos at DrupalCon and afterward to beef it up to the point that it does."
Adding join info to schema might help us here. Or maybe we can leave that to 'core fields API' and just provide the interface to generate such queries?
Comment #57
bjaspan CreditAttribution: bjaspan commentedI've discovered a bit of a snafu.
Here is one example scenario. BOOTSTRAP_LATE_PAGE_CACHE calls variable_get('cache') which, if the variables cache entry has expired, calls cache_set('variables'). cache_set() calls db_insert()->duplicateUpdate(). On pgsql (or any database without its magic "INSERT ... ON DUPLICATE UPDATE" feature), duplicateUpdate() requires calling drupal_get_schema() to identify the primary key of the table to generate the WHERE clause for the generated UPDATE query. Problem: drupal_get_schema() is defined in common.inc, not loaded until BOOTSTRAP_FULL, but we're only at BOOTSTRAP_LATE_PAGE_CACHE.
We can move drupal_get_schema() into bootstrap.inc so it is loaded earlier, but drupal_get_schema() calls drupal_alter('schema'). drupal_alter() is also defined in common.inc, and also requires all modules to be loaded anyway, so moving the function to bootstrap.inc does not help. drupal_alter('schema') isn't used or documented or used, so we could just yank it.
I did yank it. However, then the UpdateQuery generated for duplicateUpdate() calls drupal_alter('query'). This fails for the same reason drupal_alter('schema') does; drupal_alter() just cannot run during early bootstrap.
This explains, interestingly enough, why the drupal_alter() call in database.mysql.inc's InsertQuery_mysql::execute() is commented out. The reason this problem shows up with pgsql is because its duplicateUpdate() handler calls the normal UpdateQuery class which has a non-commented out call to drupal_alter().
It's late and at the moment I do not have a proposed solution.
Comment #58
bjaspan CreditAttribution: bjaspan commentedOne other point: Any query that calls a join method that wants to use the schema to determine the join columns will have the same problem.
Comment #59
moshe weitzman CreditAttribution: moshe weitzman commentedWhy not just move drupal_alter()? I know that some modules are not loaded and won't have a chance to alter but thats tough luck. they can get loaded earlier by implementing hook_boot() or marking selves for bootstrap=1 in system table.
Comment #60
bjaspan CreditAttribution: bjaspan commentedI was thinking that while waking up this morning. Perhaps it is the answer. After all, modules already can't alter queries that run before they are loaded---or after they are loaded---so there won't be a big change.
The bottom line is that by defining a database system that uses the schema and creating drupal_alter('query'), we're increasing the amount of code that must/might be loaded at BOOTSTRAP_DATABASE. We always wanted to use the schema information for more intelligent query handling anyway , I just hadn't realized this consequence until now.
Comment #61
Crell CreditAttribution: Crell commentedAs Barry suggested earlier, I am planning to refactor duplicateUpdate() to require less schema interaction. I don't know if that will eliminate the issue, but it seems a good idea for non-MySQL performance anyway. That said, if we are going to make more use of the schema then we'll need it earlier. I don't think there's a good way around that other than leveraging dynamic/conditional code loading. (vis, http://drupal.org/node/221964 or something like it. Maybe more class autoload magic?)
I started on that at the code sprint, but got distracted by crappy wireless and an incredibly stupid bug on my part so not a great deal of progress was made, although there was plenty of discussion.
I am also not entirely convinced that we even need drupal_alter() on insert/update/delete queries. For SELECT, it's there to kill db_rewrite_sql(). But do we actually need it for the others? (It was included for consistency, but if it makes life easier to remove it and there are no good use cases for it, I'm fine with dropping it.)
Comment #62
bjaspan CreditAttribution: bjaspan commentedA very useful use-case for query_alter is the one we discussed at the sprint: treating it as a query listener interface. It allows (e.g.) devel module's query log to operate without a special-purpose hack. It also allows us to kill update_sql() but continue to produce the update query log, including *all* queries, not just the ones performed with update_sql().
If we decide allowing non-select queries to be altered isn't a great idea we could certainly rename it to query_listener or somesuch.
Comment #63
bjaspan CreditAttribution: bjaspan commentedAnother snafu from the pgsql driver:
The old _db_query_callback() hack converted %d to "(int) array_shift($args)". Unfortunately, "(int) ''" (i.e. "(int) empty-string") evalutes to 0. This allowed bugs in which a query uses %d but the $args value corresponding to the %d is an empty string or FALSE. This bug appears in several places in core (node.module and menu.inc so far) and, presumably, lots of places in contrib.
Now that we are replacing %d (and others) with ?, the translation from empty-value to 0 for %d args is not happening. MySQL appears lenient/sloppy enough to accept the empty string as an integer but PostgreSQL rejects it as an invalid string-encoded integer (which it is).
If we want to provide backwards compatibility for db_query(), we are going to have to update the new db_query() to use something like the old callback system, at least to process %d and %f correctly. I'll have to think about %s and %b. I also observe that %% was previously translated into %, we'll have to fix that, too.
I have not yet tried to fix this.
Comment #64
bjaspan CreditAttribution: bjaspan commentedThe alternative, of course, is to make people fix their broken usage of db_query(). The db_query() spec never said you could pass FALSE or empty-string as 0.
Comment #65
Crell CreditAttribution: Crell commented+1 on fixing the original query. There's lots of old hacks that we're killing here, such as NULL folding. If we're going to fix it, let's downright fix it for reals. :-)
I suspect in many cases it's easier to fix the original query than rely on the BC hack. The BC hack is temporary and will not be in the final D7 release, so there's no sense putting much effort into every edge case.
Comment #66
bjaspan CreditAttribution: bjaspan commentedFine with me, though we'll be finding and fixing these bugs for a long time. If we had tests that covered every query that caused every %d argument that can be zero to be zero then we could find them all quickly but, frankly, there is no way we'll have that if we get "100% test coverage."
Here is an example of one such fix, a patch to menu.inc:
Later, $item['_external'] is passed as a %d arg to db_query.
I was thinking of an interesting option this morning. Just as we could write a mock-database driver, we could also write a pedantic-database driver filter that sat in front of a real driver but did all kinds of integrity checking on queries such as making sure the data types of the arguments matched the query fields.
Comment #67
bjaspan CreditAttribution: bjaspan commentedAnother snafu. As previously discussed, the pgsql driver needs to call drupal_get_schema() early in the boot process. Even if we stopped supporting drupal_alter('query'), drupal_get_schema() is still necessary to implement the duplicateUpdate() method.
drupal_get_schema() caches the combined schema of all installed modules. When invoked during bootstrap, it caches the limited set of modules that are loaded at that point. During the install process, it seems to cache the tables defined by system.module and nothing else.
A limited schema cache breaks drupal_write_record() because that function fails if it cannot find the table schema. It will presumably break other things as well.
The solution I've thought of so far is to have drupal_get_schema() refuse to create a cache entry if the boot process is less than BOOTSTRAP_FULL. It can still use the schema cache if it exists (since any cached entry will now be a full schema). This will require slight changes to the bootstrap API since it does not currently make the boot phase available. I'll give it a try and see what happens.
Comment #68
Crell CreditAttribution: Crell commentedHm. I like the idea of a "Dev" driver that does insane-but-slow checks on data types. I hadn't thought of that as an option, but the swappable drivers should make that reasonably easy to do. We can even base it on MySQL, so that developers can write to MySQL like they're used to but with an overbearing ANSI-strict, type-strict configuration. Sorta like E_ALL for the database layer. Mesa like. :-)
Probably a step 2 task, but still good idea.
For queries like the one above, I'd just go ahead and rewrite it to the new format; don't even bother preserving %d if that takes actual effort. You should have svn access now, so go ahead and check such things in.
Comment #69
chx CreditAttribution: chx commentedBarry, Larry stated multiple times that duplicateUpdate won't require schema. That's good. About condition putting the op to the end, omg. Just OMG, are you sure you want to make people understand (and do) RPN logic in Drupal? I love RPN, I am using RPN calculators since 1989 but... Larry also wanted the same order of arguments and I was more than reluctant to do so.
Comment #70
bjaspan CreditAttribution: bjaspan commentedI have installation and logging in as uid 1 working with the pgsql pdo driver though node/add still whitescreens. Obviously there are some bugs left. :-) Calling drupal_get_schema() and/or drupal_alter() inside the database driver during bootstrap is triggering a lot of subtle bugs that have probably existed since the bootstrap code was added.
duplicateUpdate() absolutely requires schema information unless we require that the caller specify the primary key fields (i.e. the fields to move from the INSERT list to the WHERE clause of the UPDATE). It seems kinda odd to require the caller to specify that information since we just went to all the trouble of creating Schema API to provide exactly that kind of information and capability.
Regarding condition(), I think condition($field, $value, $op) makes more sense that condition($field, $op_unless_you_do_not_provide_a_value_in_which_case_value, $value_if_you_provided_an_op). It isn't really RPN logic, it's an optional argument at the end to override a default value, a very common pattern in Drupal. We could hold a survey but I'd have to reserve the right to ignore responses from people who do not know what they are talking about. :-)
I should have some more time to work on this tomorrow.
Comment #71
chx CreditAttribution: chx commentedWell, currently you do specify the keys when writing INSERT, db_affected_rows and a full UPDATE. Also what if you want to work with a non-Drupal database? I am leaning towards mandating a full blown update statement and then MySQL can ignore the keys.
Comment #72
bjaspan CreditAttribution: bjaspan commentedI'm not prepared to express an opinion on "mandating a full blown update statement" but understand that doing so will resolve NONE of the issues I've reported so far unless we also remove drupal_alter('query') and engage in some cleverness with lastInsertId() (which, granted, we may need to do anyway).
I suggest waiting until I'm done before making substantial changes. It should be soon.
Comment #73
Crell CreditAttribution: Crell commentedWhether or not we dip into the schema for the INSERT statement on non-MySQL will probably come down to a performance question. I'm not sure how expensive that operation will be; we did already discuss breaking the cache up per-table, which in this case should help considerably. Let's try it using schema and see what the performance is like. If it's icky, we can adjust the API.
As for the order of parameters in condition(), I'm also in favor of the postfix style in that it's more predictable and the code is cleaner. I defer to Dries on this one, though. Dries? :-)
Comment #74
bjaspan CreditAttribution: bjaspan commentedBy the way, this code is a perfect use case for unit tests. We have a (in theory) clearly defined API that is easily testable and multiple implementations that are supposed to behave the same way. If the database code is buggy or inconsistent in any way, difficult-to-find bugs will result. IMHO, we should not commit this code until we have thorough unit tests for it.
Comment #75
Crell CreditAttribution: Crell commentedSince we don't have a place to put unit tests in core yet, especially for non-modules, how do you propose we do that? chx? (I'm not against it, just want to do it right.)
Comment #76
moshe weitzman CreditAttribution: moshe weitzman commented@Barry - we are at the very beginning of the code cycle for D7. I think it is a bit early to deny patches that omit unit tests. We have not even added a single unit test to core yet. Your motivation is sound, but the timing is off IMO. If someone wants to write tests that terrific.
Comment #77
bjaspan CreditAttribution: bjaspan commented@moshe: Yes, we're at the beginning of the cycle, but I draw the opposite conclusion: This is the perfect time to set the tone that patches require tests. Otherwise, when is the right time? Everyone will say "I'm too busy, I'll write tests later/after code freeze" which means "never." Also, if the tests reveal bugs at that point, it is much harder to change the new APIs, etc. than it is before the patch is committed.
More importantly, as the person most familiar with this code besides crell and chx, I have little confidence that it implements the documented APIs correctly, and I have no confidence that the pgsql driver implements it correctly, because I'm not sure the API docs are even self-consistent. Writing tests will flush that out.
@crell: I do not know if there is a plan for where to put core tests yet. For now we can create a dbtest module and move the tests when they have a correct home.
I'm still hoping to commit the pgsql driver to svn today.
Comment #78
bjaspan CreditAttribution: bjaspan commentedEven if not all patches require tests, this one really should. It will screw up everyone if it is wrong.
Comment #79
catchAll core tests are currently patches to simpletest module for now so they can be brought over in bulk. Somehow I don't think this is applicable for tests for patches which aren't into core yet (although two patches, one in the core queue and one in the simpletest queue seems sane to keep things as centralised as currently possible).
afaik, simpletests aren't required for patches to be committed, but they are required for a code freeze extension. If there's going to be an additional requirement for unit tests on big API-rewrite patches then it'd be good to have this made clear asap. But since we're only a week after testing was officially announced in the first place, it also seems a little early to me.
Comment #80
chx CreditAttribution: chx commentedI was hoping that we can write tests for this one once its in. I can certainly accept that forthcoming big patches need a test -- but then that's part of the process... I just would not like this one held up by the unanswered questions about testing.
Comment #81
magico CreditAttribution: magico commented(subscribing)
Comment #82
bjaspan CreditAttribution: bjaspan commentedWith the attached patch, the pgsql PDO driver correctly handles installation, login as uid 1, posting a node, and posting a comment. There are still known bugs, but I wanted to get something committed. This code is NOT ready to commit, so I'm leaving it as CNW, but reviews are welcome.
If you are following chx's SVN repo, this is revision 357.
## To do items
* I have NOT done any pgsql BLOB handling, bindParam(), etc. stuff. I've noticed that sometimes the 'schema' entry in the cache table gets lost, causing a PDOException. I suspect these are related.
## Recommendations (not yet implemented)
* There should be a central anonymous-placeholder name generator, otherwise we might get conflicts. Consider:
There is not a conflict between SET and WHERE, but there could be. If the placeholders are all just :db_placeholder_NNNN, there will never be a conflict.
* The return value of Query::execute() is not clearly specified and appears to vary by query type. What should InsertQuery::execute() if it performs an UPDATE query instead? Since there is no lastInsertId() to return in this case, the caller cannot rely on the return value being a last insert id (we surely do not want the return value to depend on whether duplicateUpdate() was called).
## Changes to the database layer in this patch
* I fixed the "FALSE/empty-string as %d" problem by making db_query() (and friends) take care of it. I just couldn't deal with fixing queries all over core at this time (there are a lot of them). I did fix a few before changing db_query(), and I left those fixes in.
* Remove abstract protected functions from class DatabaseSchema. Not all schema drivers implement the same internal functions.
* When throwing a PDOException, include the full text of the query and args.
* DatabaseConnection::lastInsertId() requires some special care (surprise!). For mysql, it takes no arguments. For pgsql, it requires the name of a sequence object. Our db_last_insert_id() function takes $table and $field, which identifies the sequence object, but according to the specs you have to pass lastInsertId() an argument or not depending on which driver you are using (not very portable!), so we can't just pass $table and $field to lastInsertId() and let the mysql driver ignore them. In the case of an InsertQuery() object, the object already knows the table and can get the field from the primary key. But in the case of db_last_insert_id(), we have to preserve the information without passing args to lastInsertId(). Therefore, I added a setLastInsertInfo() method to class DatabaseConnection. mysql's does nothing, pgsql's remembers what it needs.
* Add db_driver() method as replacement for $GLOBALS['db_type']. Warning! Many 6.x updates and other code will stop working because this variable is no longer available.
## Core changes in this patch (required for pgsql support)
* Add drupal_get_bootstrap_phase(). drupal_get_schema() needs to not cache the schema of we're not at BOOTSTRAP_FULL.
* Load includes/module.inc in BOOTSTRAP_DATABASE. This is so database queries can call drupal_alter(), drupal_get_schema(), etc. during early bootstrap.
* Move drupal_get_schema() and drupal_alter() to bootstrap.inc. Database queries need these.
* Fixed %d/'' bug in session.inc INSERT and UPDATE query.
* In module_list(), initialize static $list = array(). Otherwise, if module_list(FALSE) is called before module_list(TRUE), NULL is returned instead of an array() and foreach throws an E_WARNING. This happens (e.g.) when a query calls drupal_alter() during early bootstrap.
* In _drupal_bootstrap_full(), rebuild the module_implements hook cache. During bootstrap (perhaps only during install.php), the hook cache is limited to system and filter modules before BOOTSTRAP_FULL and needs to be reset once new modules are loaded.
* Fix two %d/FALSE bugs in menu.inc queries.
* Fix three %d/'' bugs in node.module.
* Cache a fully-build schema during install.php so schema-based queries can work on a brand new site before anyone visits the modules page.
Comment #83
bjaspan CreditAttribution: bjaspan commentedAddenda:
1. When I said, "There are still known bugs, but I wanted to get something committed" I meant "committed to chx's SVN repo.
2. I did not attach I patch to the previous comment. I meant to say "With the SVN commit I'm about to make...". If you want to see the changes I made to Larry+chx's work, use svn diff.
3. To this comment I am attaching a complete patch against HEAD for the most recent version of the PDO changes including my pgsql+related stuff. Note that this is Larry's issue so you should not take this as an authoritative patch, I'm just being helpful, and the code needs work anyway so it is not like this will get committed. Unlike the previous patch, this one actually contains all the files you need to use it. :-)
Comment #84
Dries CreditAttribution: Dries commentedI still have to do a proper review but I decided to hold that off for a while -- Barry's review is excellent and I'm happy to let him drive this for a while.
Here are a couple of thoughts that might help decision making and debates:
* Delayed inserts are useful. Let's keep it.
* Supporting multi-insert statements is useful. On MySQL it can speed up things by a factor 20. Let's keep it -- but let try to document it better. It took me a while to figure this one out.
* For me, writing
db_insert($id, $table)->fields('foo', 'bar')->values($foo, $bar)->execute();is more natural but also more prone to errors. I might likedb_insert($id, $table)->fields('foo' => $foo, 'bar' => $bar)->execute();better as I'd make fewer mistakes. Still undecided about this one.Comment #85
Crell CreditAttribution: Crell commentedI just checked in a "dbtest" module to the svn repository. It contains no code aside from the start of unit tests for the new system. I've written test cases for basic fetches from db_query(). Lots more unit tests to come. We can use them for testing the patch and additional drivers, and then move them to the SimpleTest module or wherever later.
@Dries: I'm trying to minimize the use of variable arg count, as it's ugly and harder to document and debug and makes adding optional parameters that actually are useful impossible. I also want to minimize the number of different ways a single method can be called, for the same reason. :-)
Any input on the condition() method interface?
I'll see what I can do to better document multi-insert once I'm done tweaking the API on that. :-)
Comment #86
bjaspan CreditAttribution: bjaspan commented@dries:
fields('foo' => $foo)is syntactically invalid; you can't use => outside an array.fields(array('foo' => $foo))is how the current interface works. Allowing an inline-array with fields() as above while still supporting duplicateUpdate() is the purpose behind my proposed changes to that interface (which I think Larry agrees with).@crell: re: dbtest, excellent! I'll add some tests when I can.
Comment #87
Crell CreditAttribution: Crell commentedOne question, I suppose, is how we want to handle mixing multi-insert and "ON DUPLICATE UPDATE". I'm not sure off hand how MySQL mixes them; what another database would do, I'm not sure either.
@bjaspan: db_last_insert_id() is vestigial, and should be removed as part of phase 2. The last inserted ID will be returned from db_insert(), or should be. (If it isn't now, that's a bug that I will fix.) I wouldn't spend too much time on it.
Comment #88
chx CreditAttribution: chx commentedMulti inserts on other databases are inserts in a transaction, and if there is a unique key collision, I guess the transaction gets rolled back. This is just a guess. MySQL has tricky handling of this see MySQL handbook on
VALUES(). Definitely a followup patch.Comment #89
bjaspan CreditAttribution: bjaspan commented@crell: What should db_insert()->orUpdate() return if it actually performs an update? The id of the updated row? Should the caller be able to tell whether an insert or update occurred?
db_last_insert_id(), db_query(), etc. may be vestigial but the contrib update to D7 will be a lot slower if we yank them before D7 is released. This will be a decision the community has to make. We shouldn't pre-determine that they have to be yanked by not supporting them now. (And in any case, today's code uses it, so it needs to work for now.)
Comment #90
Crell CreditAttribution: Crell commentedWe've already determined that db_fetch_object() is dying (see the note in the code to that effect); it's there just as part of the temporary BC layer to avoid a 1 MB patch. Same for db_last_insert_id(). Supporting those long-term complicates the API and creates too many ways of doing something, all of which people will need to know. (PDO already offers at least 3 ways to iterate the result set; we don't need more).
As for what db_insert()->orUpdate() returns... excellent question! :-) I'm not sure. I'll need to play with the code a bit more.
Comment #91
Wim Leers@chx:
According to ANSI SQL, that's correct.
Comment #92
bjaspan CreditAttribution: bjaspan commentedRandom musings:
The "abstract" classes in database.inc, such as InsertQuery and UpdateQuery, perform some non-trivial computations on some method arguments. For example, InsertQuery::fields() splits its $fields array into keys and values and loses fidelity of the original data by storing "$fieldname=$placeholder" instead of just $fieldname.
This is a problem for drivers (like pgsql) that need to walk through the field values and do something to them based on the scheme (such as blob handling). Of course, the driver can override the method and store the original data (which is what pgsql currently does) but then it has to choose between calling parent:: which it knows to be all/mostly useless or not calling it and risking losing important functionality that may get added there in the future.
I am thinking that most of the work performed in these abstract classes should not be. The classes should either be pure interfaces or the methods should just store the raw input data as received. execute() or similar can perhaps serialize things into SQL as a "generic" implementation but doing so earlier (e.g. creating the placeholder variables, etc. in fields() or values()) I think is counter-productive. It makes it more confusing, not less, to create a driver.
I'm working on proper blob handling for pgsql. I'm having to override most everything in Query and, I recently realized, DatabaseCondition as well. When I'm done, we'll have a clearer idea of what the abstract classes should do.
Comment #93
recidive CreditAttribution: recidive commentedSome thoughts on code style.
As we are changing the db_*() functions interfaces drastically, wouldn't it make sense to make them static class methods for consistency? So, for example, instead of:
it would be:
The consistencies I'm talking about here are a) it would not mix functional code with class based ones, and b) the line of code would be entirely Camel-cased.
Comment #94
Crell CreditAttribution: Crell commented@bjaspan: You may be right. I was coming at it from a MySQL-centric view, since that's what I know. However, I'm concerned about making the specific driver implementations too complicated. Not all drivers will need field handling, for instance.
I did run into that issue when adding another line to InsertQuery::execute(), actually, since MySQL does override that. Part of me is wondering if we shouldn't have some sort of wrapping method. e.g., InsertQuery::execute() which does stuff and then calls InsertQuery::_execute(), which is then driver-specific. That adds a method call, though, so I'm not sure if that's a great idea. Hum.
@recidive: I considerered just exposing the static methods directly, but decided against it. One, we're not getting rid of db_query*(), so it doesn't make sense for us to not have the other wrappers. Two, Drupal folk are used to functions, and there's nothing inherently wrong with function-factories. Three, db_insert() is shorter to type than Database::insert(). :-)
@all but particularly bjaspan: I just checked in some more unit tests on insert queries. Writing more as we speak. I also tweaked the API a bit to allow for insert queries to be re-used. That is, you can call ->fields() to define the fields, then inside a loop call ->values() some number of times, execute(), then call values() some more and execute() again, etc, all on the same query object. That should make importers really fast. :-)
Writing the tests is really helping me think out the API more. Yay for testing!
Comment #95
bjaspan CreditAttribution: bjaspan commented@crell: I actually find the way you are assembling placeholders, etc. quite confusing as it is. :-) I realize it is a tricky problem since you need to create placeholders separately for fields()/values(), conditions, etc.
Something I may need to do is iterate through the UPDATE SET fields (at least), identify which ones are blobs, and use bindParam on them. I'm not sure but I think this means I need to use bindParam on everything for the query. So that means I also need to be able to iterate through the condition fields and bindParam them, too. It was at this point that I punted.
Yes, yay for testing, for exactly the reason you said. Be sure to test the multi-insert functionality; I'm pretty sure I did not understand your data structure for that at first and got it wrong in the currently committed code.
Comment #96
bjaspan CreditAttribution: bjaspan commentedMy latest understanding of the bootstrap snafus I mentioned:
* The earliest queries Drupal performs are reads from the variable and cache tables. This is before any modules are loaded.
* The cache tables use blobs.
* Databases with special blob handling need access to the schema in order to know that cache tables use blobs.
* The schema structure lives in the cache but that requires access to the cache table to learn that the cache table uses blobs.
* The schema structure also lives in hook_schema(), but no modules are loaded yet.
* Catch-22.
In pgsql's case, we can apparently SELECT from a blob column without knowing it, so we get around the catch-22. For other databases, that trick may not work.
What this means is that if drupal_get_schema() cannot retrieve a schema from the database and no modules are loaded yet, it needs an emergency fallback of loading system.install (perhaps all required-modules .install), calling those hook_schema()s, and returning the results.
Comment #97
Crell CreditAttribution: Crell commentedI also ran into an issue last night with the orUpdate() logic. If we only specify fields, then we can't do things like incremental counters. (ON DUPLICATE UPDATE counter=counter+1) So orUpdate() will have to take a complete field/value array(s). orUpdateExcept() we can probably get away with just the field names, though.
Regarding blobs, two possibilities: 1) Does the cache table really need to use blob, or could it use TEXT? 2) Since Dries wants us to do streaming blobs eventually, which I'm fairly certain would require special handling anyway, perhaps we should just go ahead and do a different syntax for blobs now? (Not a %b, but something in the SELECT query builder.)
Would any of the Oracle/MS SQL/DB2/SQLite folks know how much trouble BLOBs are going to be on those databases?
Comment #98
chx CreditAttribution: chx commentedIn pgsql's case, we can apparently SELECT from a blob column without knowing it, so we get around the catch-22. For other databases, that trick may not work. <= it will work, PDO stringify option is not DB specific to the best of my knowledge.
Comment #99
chx CreditAttribution: chx commentedWell, reading pdo_stmt.c definitely underlines this:
Edit: pdo_stmt.c is, of course, not database specific. And in the further lines we have stream handling too. And this is in fetch_value. All is well.
Comment #100
bjaspan CreditAttribution: bjaspan commented@crell: I can live with orUpdate() taking field/value arrays if, when passed an empty array, it updates all the fields to the values originally specified to db_insert()->fields() (i.e. in the degenerate case, orUpdate() == orUpdateExcept()).
@chx: If PDO can magically handle selecting from blobs on all databases, why can't it magically handle inserting/updating them?
Comment #101
chx CreditAttribution: chx commented@bjaspan, ask Wez, I know not.
Comment #102
Dries CreditAttribution: Dries commentedI've started to look into the tests a bit as that is a good place to learn how the API is intended to be used. Here are some initial comments/thoughts:
-
testRepeatedInsert()andtestMultiInsert()look identical? If not, the difference is probably too subtle and needs to be documented.-
$num_records_before = db_query("SELECT COUNT(*) FROM {test}")->fetchOne();would be unnecessary iftearDown()was called.- Can we rename
fetchCol()tofetchColumn(). Also, shouldn't that befetchRow()?- I'd rename
fetchOne()tofetchField(). I'd prefer to consistently use the proper database terminology; 'one' is undefined and could be a row or a field.- I didn't understand the following yet -- nor the test that was using it:
Might be worth another line of documentation, or a more extensive test.
- It took me a short while to figure out the different between
fetchAssoc()andfetchAllAssoc(). Here too, I'd clearly and consistently specify what is being returned. So maybe just writefetchNextRow()andfetchRowsAssoc()? I think we can and should make the API more self-explanatory.- I don't like the fact that we need to create an empty dbtest.module and a dbtest directory for this. I'd prefer to put the database tests in the system module's directory as "db.test".
- How many of Barry's suggestions have been incorporated already? Do I go ahead and review the code some more, or is it best to hold of for a couple more days/weeks? Let me know.
Comment #103
Dries CreditAttribution: Dries commentedI was also wondering how many of these changes are actually required to PDO-ify Drupal 7. As far as I can tell, PDO-ifying Drupal 7 does not necessarily require such heave API changes. I'm going to think about this some more, and review how many of the improvements listed in http://drupal.org/node/225450#comment-752493 actually require such drastic changes. I'm not necessarily against them, I just want to make sure we're not over-engineering this in light of the (stated) objectives.
Comment #104
hswong3i CreditAttribution: hswong3i commentedIt may be a silly question: what are we going to have with PDO-ify Drupal 7?
It seems our initial motivation are the use of PHP5-specific PDO driver backend, rather that legacy mysql/mysqli/pgsql drivers, in order to giant stability and performance improvement; moreover, promote the use of PHP5 starting from the level of database connection, so we will able to fully utilize those modern PHP5-specific features?
If we are just asking these features as starting point for further more development, the case of PDO-ify Drupal 7 should be much simple.
Comment #105
Crell CreditAttribution: Crell commented@Dries: Just switching to PDO and doing nothing else wouldn't require the query builders, for instance. However, just switching to PDO and doing nothing else doesn't really buy us anything. (See my attempts at a PDO-MySQL backend for Drupal 6 from a year ago.) What using PDO allows us to do is use classes and inheritance for the backend so that we can connect to multiple databases simultaneously; and have decent query builders that can encapsulate type handling; and it requires using an array-based connection syntax anyway (the url syntax wouldn't handle SQLite, for instance) so we may as well do that "right"; and all that other fun stuff. I see no point in going to all the effort of moving to PDO If we don't leverage it, which is why the focus of this effort has shifted from "use PDO" to "make the database layer kick ass". :-)
Also, "repeated insert" execute()s the query after each values() call, but doesn't reset the fields array. The intent there is to mix them; so if you're inserting 10,000 records, you can batch them and insert, say, 20 at a time with multi-insert statements inside a loop. That way you don't run out of memory or end up with a half-meg query string. I'll update the inline docs.
I put the simpletests in a dummy module because right now core has no "tests" directories for any modules. I dodn't want to start adding them unilaterally. If you'd rather we start doing that with this patch, I'm fine with that and will move the tests accordingly. Let me know.
Most of the method names are based on the pattern established by PDO itself. I'll have another look and see if we can simplify them, but we are limited in part by the existing names. fetchColumn(), for instance, is already (stupidly, IMO) used for what we call db_result(). I'm hesitant to start redefining methods like that, and I'm considering renaming DatabaseConnection::query() to something else to avoid overriding PDO::query(), which allows for non-prepared queries.
What I'm focusing on right now (and didn't get much time this weekend to work on, sadly) is the INSERT builder, specifically the "on duplicate update" functionality.
Comment #106
chx CreditAttribution: chx commentedLet me mention that db_rewrite_sql is getting worse and worse release by release and this patch lets us kill it in a subsequent patch.
Comment #107
Crell CreditAttribution: Crell commentedFor those playing our home game, I just checked in the following:
- Added various more INSERT unit tests. If in doubt about how INSERT works, refer to the tests.
- Refactored the INSERT API as discussed above. You can now call orUpdate($fields) to explicitly specify various updates to make or call orUpdateExcept() and specify a list of field names (an array or varargs, I caved here) to have the system update everything except those. We end up using both in core, as it turns out.
- In the process, I moved those methods down to the db-specific driver. Looking at them, I don't see how they'd be at all generic. Barry, all yours for postgres. ;-)
- The "duplicate update" code only runs if there's a single value array specified. The complexity of dealing with how to handle multi-insert updates is more than I want to deal with at this point. Maybe a follow-up patch if someone can figure out a sane way to do it.
- The InsertQuery::fields() method now can take one associative array (fields=>values), two indexed arrays (fields, values), or one indexed array (just fields, have to specify values separately). That should cover just about every case except for the varargs case, which would be a 4th way to call that method. That scares me to even think about. Besides, most places in core I've found it easier to use the associative array format than anything else. It really is quite convenient in practice.
- Renamed fetchOne() to fetchField(), per Dries' comment. Other method renames I need to think about, as there are existing PDO methods that we have to consider. (Remember also that fetch() and fetchAll() take all sorts of wacky bitwise parameters to do all kinds of funky stuff, even if we don't have an explicit method for it.)
- Various documentation cleanup as mentioned above.
Barry, please let me know if anything else is still broken or painful. I need to figure out what we're doing with the select builder next, as from conversations with merlinofchaos that still needs some work. I'm debating if we have to drop the Fluent API there in order to support auto-aliasing. I may open this up to a separate blog discussion; not sure yet.
Comment #108
Chris Johnson CreditAttribution: Chris Johnson commented(subscribing)
Comment #109
theblacklion CreditAttribution: theblacklion commentedsubscribing
Comment #110
Crell CreditAttribution: Crell commentedSo after talking to chx last night, here's the thoughts on what should happen with the SELECT builder:
- Query IDs will go away, for all query types. They're not appropriate here. Instead, hook_query_alter() will operate on the base table (only table in the case of insert/update/delete).
- The base table will move to the select constructor as Barry suggests to better parallel the other factory functions.
- Not all queries will be alterable. There are use cases where you want a builder but don't want it alterable. chx insists that it be "opt out", for security reasons. I find that to be too much magic, and would prefer an easy opt-in. (
->alterable(FALSE)vs.->alterable(TRUE)) I will defer to consensus or Dries on this one. :-)- The Select::fields() method will get broken up so that it's not as "dumb" as it is now. Probably that will be ->field('nid', 'node', 'alias'). Open question: If an alias is not specified, should one be auto-generated of "field_table", or just "field"?
- The core query builder will not completely replace the Views query builder, but it should replace most of it. Views can then wrap it with its own extra Views-specific functionality. The main part it can't replace yet is auto-aliasing for fields and tables. In order to support that, though, we have only 3 options, none of which I particularly like. I'd like feedback from others on this front:
1) Get rid of the Fluent API for fields and tables. That means ->field('nid', 'node') will return an alias as a string, rather than returning the query object. Similarly for join('user'). That breaks the fluent API.
2) Set whether or not to auto-alias in the constructor. That is, db_select('node', $options, TRUE) means field() and join() will return an alias. db_select('node', $options, FALSE) means field() and join() return the query object and you're on your own for aliases.
3) Input/output parameter. That is,
$alias = NULL; ->field('nid', 'node', $alias)will take $alias by reference, use it as is if it's a string or set it to an auto-generated alias if it's NULL, and then return the query object so the fluent chain isn't broken. Input/output arguments scare me, especially in OOP code, but it's the only way I see to have our cake and eat it, too.Before I actually write any code, thoughts on which approach people want to take? I'd rather rewrite as few times as possible. :-)
Dries, we still need a decision from you regarding infix vs. postfix notation for ->condition(). I want to get that settled and move on.
Comment #111
bjaspan CreditAttribution: bjaspan commentedI will be getting back to working on this soon; I have some work time slotted for this issue.
Why remove all query IDs? I agree that they are not sufficient by themselves for identifying queries because, e.g., the replacement for db_rewrite_sql() can't know the query ID for every query it should rewrite. But certainly there are some times code will want to target a specific query from a specific module separate from other queries for the same base table, so the IDs are useful.
As for the db_rewrite_sql() case, basing it purely on base table isn't sufficient either since (e.g.) some node queries should involve all nodes and some should involve those the user has permission on. I was thinking what we need are query tags. So the db_rewrite_sql() replacement would document that it operates on all node queries having the "node-access" tag by doing the appropriate joins, and callers that want that behavior do db_select('node', ...)->tag('node-access')->etc(). "Property" is perhaps more meaningful than "tag" but has more letters in it. :-)
Comment #112
Crell CreditAttribution: Crell commentedWell base table is how db_rewrite_sql() works now, so that would be no less functionality than we have now. Tagging queries... Wow, that results in all sorts of other questions, and possibly security issues. I can see the potential flexibility but... wow. :-)
Comment #113
Dries CreditAttribution: Dries commentedCrell: of all the motivations, the db_rewrite_sql() sounds like the most compelling one to me. Some of the other reasons could also be accomplished without this rewrite (i.e. multiple database support and array-based connection syntax). It would be helpful to explore the db_rewrite_sql() replacement a bit more, for example by trying to implement some actual use cases as part of the tests. Because what would be really bad, IMO, is that we'd have to resolve to a combination of regular expressions and this new database abstraction layer.
Crell: for the condition() stuff -- I'd go with condition($field, $value, $op) for now. It is a little bit awkward but certainly less awkward as the alternative.
Crell: I've just updated my SVN copy and I'll dig the code some more to help answer these questions. I'll be traveling the next two days so it might take me a little while.
Regardless of the "critical eye", this looks really compelling -- especially if we can make it work cleanly.
Comment #114
Anonymous (not verified) CreditAttribution: Anonymous commentedSubscribing
Comment #115
bjaspan CreditAttribution: bjaspan commentedComments on orUpdateExcept(). If you agree with these comments, I'll change the function docs:
* Must we require that it only be called after fields()? It seems logical to think "insert or update $fields" and therefore to write:
The requirement to call fields() first implies that you are performing some computation in fields() that needs the orUpdateExcept() info. Why can't that computation be performed later?
Incidentally, the same requirement is not listed in the orUpdate() docs.
* Looking at your usage, you seem to be passing the primary key fields to orUpdateExcept():
The whole point of orUpdate() and orUpdateExcept() is that the pkey already exists and will be used in an UPDATE WHERE clause. The orUpdate() query builder should never generate UPDATE foo SET pkey = :pkey WHERE pkey = :pkey (it's a no-op), so it should just implicitly remove the pkey from the fields it SETs. Thus I do not see the point in requiring the pkey to be passed to orUpdateExcept().
Note that if the point of requiring the pkey to be passed is to avoid depending on drupal_get_schema(), it won't help because the schema is needed anyway for databases that require special treatment based on column type.
* I'd suggest that calling orUpdate*() on a multi-insert query should result in a thrown exception, not just be ignored.
Comments on orUpdate:
* The docs for $fields arg say "if specified" but the function signature has the arg as required. I thought the plan was that orUpdate(/*no arg*/) would update all the fields to the values provided to fields() (except of course the pkey as discussed above). So it should be optional.
Again, if you agree, I'll make the changes.
Comment #116
bjaspan CreditAttribution: bjaspan commentedOh, and I'll update the tests too since I'll need to for pgsql.
Comment #117
beeradb CreditAttribution: beeradb commentedsubscribing
Comment #118
Crell CreditAttribution: Crell commentedYes, passing the primary key was to avoid hitting schema. I'm still not sure of the performance implications of that. (I've honestly not spent as much time with schema API as I should have.) Having orUpdate() take no parameters and be equivalent to orUpdateExcept(primary keys) would require hitting schema, which is also why I did that.
If we change Schema API to use a cache entry per table rather than one giant array, that should alleviate the performance issue enough that it's an acceptable trade-off, even on MySQL. Of course, that means we need to not use a builder inside cache_get().
The reason for the order of the method calls is that orUpdateExcept() uses the $insertFields and $insertValues arrays in order to build the $updateFields and $updateValues arrays. It really just copies them into the update format, skipping the flagged fields as it goes. It can't do that until after $insertFields and $insertValues[0] are set. In order to allow orUpdate*() to come first, we need to dumbly save the passed values and update data and then parse it twice; once in execute() to get values, and once in __toString() to get the fields. This way, we only make one pass.
I suppose someone could argue that is premature optimization. :-) I'm willing to accept that argument if someone can make a good one, and then switch to late-parsing. I'm just not sure that method-order-convenience is worth it. (We're probably splitting hairs either direction.)
Comment #119
bjaspan CreditAttribution: bjaspan commentedProgress!
The pgsql driver is now properly handling blobs via the bindParam() method and it seems to be mostly working. It passes all the tests Larry has written except for those that are in fact broken tests, in which case it is properly throwing exceptions. :-)
However, the code is very ugly and inefficient. There is a lot of wrangling with fields and values arrays in order to get the data I need when I need it. The next step is to clean it all up and refactor the code in database.inc to be doing only operations that are useful for all database drivers.
I'm pretty pleased to have gotten this far and I have another day of Acquia time left allocated to this task; I'll probably work on it on Monday.
Comment #120
bjaspan CreditAttribution: bjaspan commentedLarry, regarding orUpdate() functionality, consider this query from testInsertOrUpdate():
You are passing 'age=age+1' to orUpdate(). This works for mysql because of special-case code inside InsertQuery_mysql::orUpdate(). Questions/observations:
1. UpdateQuery does not support this notation, so InsertQuery::orUpdate() is actually more flexible than UpdateQuery(). Is this what you meant? It seems a rather incongruent API.
2. The fact that InsertQuery::orUpdate() accepts fields that UpdateQuery::fields() does not means that the former cannot be implemented in terms of the latter which is clearly not sensible for any database except mysql with its ON DUPLICATE UPDATE feature. So, if we support that notation in InsertQuery, we have to support it in UpdateQuery (though the converse is not true).
3. I'm not convinced we need to support this for InsertQuery(). IMHO, orUpdate() and orUpdateExcept() should take *only* a (possibly empty) list of field names, no values. If the insert cannot occur because the primary key exists, then the selected set of fields for that primary key are updated to the *same values* as would have been inserted. I think if you want more complex logic than that, then you should just write an insert query and, if it fails, run an update query (or vice versa). We should not try to build the ultimate generic "insert and/or update" operation.
4. I realize that we need to support 'age=age+1' in UpdateQuery somehow because that is a legitimate operation. However, I'm not a big fan of the notation in which some elements of the fields array are key/value and others are integer keys. One alternative is to specify key/value updates separately from expression updates, e.g.
db_update('id', 'mytab')->fields(array('name' => 'Larry Jr', ...))->expressions(array('age=age+1', ...))->execute();In fact, the argument to expressions() could be array('age' => 'age=age+1'), putting the column being set in the key and the full expression (including the column being set) in the value. This would support a database which had to treat update assignments to certain column types differently (e.g. if they are blobs). I do not know if pgsql is such a database or if one exists.
5. I have a strong suspicion that any query builder we devise is going to be insufficient for some legitimate query that some module needs to perform, so that module will need to fall back on db_query(). Perhaps that is just life; hopefully core and the "important modules" can avoid doing so.
6. On a different topic, your test inserts explicit values into a type 'serial' column. This works on mysql but breaks on pgsql. On pgsql, you can do the insert but if you provide an explicit value the internal sequence on which the serial column is based does not get updated. So if the id sequence starts at 0 and you insert ids 0, 1, 2, and 3, then when you try to insert without specifying an id, pgsql gives you a duplicate-primary-key error because it is trying to insert 0 which already exists (whereas mysql will insert with id 4). Frankly, serial columns are extremely db-dependent, we have to stick to a very lowest common denominator if we want code to be portable, and in many ways I regret that we switched to using them.
7. On another different topic, according to the pgsql documentation, UPDATE and DELETE joins are in fact SQL extensions, though mysql and pgsql both implement them. I'm not sure whether we should support them or not. Perhaps we should research which databases support them; if they all do, we should.
Comment #121
chx CreditAttribution: chx commentedI'm not convinced we need to support this for InsertQuery(). IMHO, orUpdate() and orUpdateExcept() should take *only* a (possibly empty) list of field names, no values
Then let me convince you, check statistics module which inserts a 0, and increments if the record is there. This is a typical case where update gets an expression.
Comment #122
bjaspan CreditAttribution: bjaspan commented@chx: The fact that some code wants to insert a new record or change an existing one with column-relative expressions does not, to me, imply that InsertQuery needs to support that in a "single operation." I see three possible levels of functionality:
1. InsertQuery does *insert*, UpdateQuery does *update*, and that's it. If you want to insert or update, do one and then, if necessary, the other.
2. InsertQuery supports unified "create or save existing object" semantics in which, if we are trying to insert for a primary key that already exists, do an update instead. In this case, we are always inserting or updating rows to the same constant values, we're just not always updating the full set of rows we would insert if the pkey did not already exist (this allows preserving, e.g., a "created time" field).
3. InsertQuery->orUpdate() is conceptually two completely different queries with completely different field specifications, as it is currently written now (and happens to be one query on mysql due to its particular SQL extension syntax).
The mere fact that code exists which could use #3 in order two reduce "if (!db_insert($foo)) { db_update($bar) }" into just "db_insert($foo, $bar)" is not nearly enough reason to introduce the complexity of the feature. If there is some reason that #1 *cannot* be implemented in a db-agnostic way and #2 or #3 can be, that might be a compelling argument for the feature.
In other words, you haven't convinced me yet.
Additionally, if we are going to support "two unrelated insert and update queries" in a single object, it should not be called InsertQuery but InsertOrUpdateQuery or something like that.
Comment #123
bjaspan CreditAttribution: bjaspan commented@crell: All the tests you've written (thanks!) now pass with the pgsql driver. Unfortunately, the tested code is broken even though the tests pass. How is this possible? Consider:
Currently, InsertQuery_pgsql::execute() always returns TRUE, not last id, on success. Clearly that needs to be fixed but this test passes anyway because assertEqual() uses ==, not ===, and 'TRUE == 5' is TRUE. I thought that assertEqual() used ===, but in fact assertIdentical() exists for this purpose. (I well understand the difference between == and ===, I just did not realize which one assertEqual() used).
Unfortunately, converting assertEqual() everywhere in your code to assertIdentical() is not a quick solution. Consider:
fetchField() is returning a string containing the digits for the count, but $num_records_before+1 returns a long. 5 == '5' but 5 !== '5', so assertIdentical() fails here even when the database driver is correct.
Given that we want these tests to be really scrupulous in making sure the results are correct, I'd say we need to use assertIdentical() everywhere and do the type casting ourselves if necessary.
Comment #124
Chris Johnson CreditAttribution: Chris Johnson commentedRegarding
and
Postgres has supported joins during update and delete operations for 5+ years. They may well be extensions to the SQL standard, but Sybase, Oracle and IBM DB2 have supported them for at least a dozen years or more. I would bet Microsoft SQL Server has as well.
Which additional databases need to surveyed to answer this question? I'll be happy to go find out for you.
Comment #125
bjaspan CreditAttribution: bjaspan commented@Chris: The one I know I've heard discussion about that you did not list is SQLite. I just checked and it appears that it does NOT support joins for UPDATE or DELETE. So if we build them into the API, the API either won't support SQLite or the SQLite driver will have to figure out some way to implement them itself (which may or may not be possible).
SQLite does support sub-queries so presumably you can do things like UPDATE foo SET stuff WHERE id IN (SELECT id FROM t1 INNER JOIN t2...). Perhaps it is possible to translate API calls that add joins to UPDATE and DELETE queries into a sub-query approach. However, if that is always possible, then it also means that supporting joins on UPDATE and DELETE queries is unnecessary because the module author can just write the query in terms of a sub-query.
So for now perhaps we should just not support it.
Comment #126
Crell CreditAttribution: Crell commentedHonestly I think SQLite is of more value than Postgres support, so I agree that is a deal-killer for JOINS on Update/Delete. Subqueries should already be supported I believe. If not, that's a bug.
Agreed on assertEquals vs. assertIdentical. And Bah!
Update queries should also support expressions; if they don't, that's a bug. However, we can't break the expression into a key/value like normal key/value pairs because then the code has no way of knowing if we're setting the age field to an expression or to a literal string value. Since I can't see us ever using an expression on a LOB, is it possible to just presume that a numeric key doesn't need a separate bind statement and can simply be inserted into the query string literally? Or can they not be mixed that way?
Regarding insert-or-update, there's a limitation in the MySQL PDO driver that prevents us from setting update statements to return the number of rows matched instead of number affected. That means we *cannot* use the if (!update()) { insert(); } logic we're used to, because setting a variable to the same value it already has will return 0, so the if statement passes, so we try to insert and get an error. That sucks, but I don't know of an alternative. (If there is a good alternative I'm willing to consider punting on orUpdate functionality for now and coming back to it in a subsequent patch, but that issue needs to be worked around one way or another.)
Regarding an exception on multi-insert-or-update, agreed and will update accordingly.
Nothing in the code here prevents someone from writing a complicated UPDATE query directly into db_query(), except for db_query() having no facility for field type marking at this point since it's only needed (AFAIK) for insert/update statements.
Comment #127
bjaspan CreditAttribution: bjaspan commentedre: SQLite vs. Postgres. I've never had any opinion about Postgres importance per se, only that supporting more than db is important to keep us honest and flexible; otherwise, we'll be tied to mysql for life.
re: expressions in update queries. I know we can't make it a normal key value pair without providing some other way to distinguish it from a literal string. However, in #120 I proposed a suggestion: providing a different method to specify update expressions vs update fields, e.g.
This gets us away from the hideous kludge of distinguishing fields vs. expressions in the fields() array with is_numeric($key). What do you think of this idea? I just really dislike having both string and numeric indexes in a single array; also, consider the perverse case of "CREATE TABLE foo (`0` integer)", which is legal at least in mysql. (As an aside, UpdateQuery::fields() should have the same argument options as InsertQuery::fields().)
re: assuming all UPDATE expressions are for "normal" column types. That's the assumption we have to make using the current approach, yes. I do not know if it is a reasonable assumption. For now, let's go with it.
re: insert-or-update. If mysql PDO does not support the if (!update()) { insert(); } logic because it always returns rows affected instead of rows matched, how to other systems that use PDO implement the equivalent functionality? There must be a way. If using mysql PDO means there is no way to write a functioning system without using ON DUPLICATE UPDATE, then IMHO PDO is useless as a multi-database API abstraction and we should not be using it.
Comment #128
bjaspan CreditAttribution: bjaspan commentedre: SQLite vs. Postgres. I've never had any opinion about Postgres importance per se, only that supporting more than one db is important to keep us honest and flexible; otherwise, we'll be tied to mysql for life.
re: expressions in update queries. I know we can't make it a normal key value pair without providing some other way to distinguish it from a literal string. However, in #120 I proposed a suggestion: providing a different method to specify update expressions vs update fields, e.g.
This gets us away from the hideous kludge of distinguishing fields vs. expressions in the fields() array with is_numeric($key). What do you think of this idea? I just really dislike having both string and numeric indexes in a single array; also, consider the perverse case of "CREATE TABLE foo (`0` integer)", which is legal at least in mysql. (As an aside, UpdateQuery::fields() should have the same argument options as InsertQuery::fields().)
re: assuming all UPDATE expressions are for "normal" column types. That's the assumption we have to make using the current approach, yes. I do not know if it is a reasonable assumption. For now, let's go with it.
re: insert-or-update. If mysql PDO does not support the if (!update()) { insert(); } logic because it always returns rows affected instead of rows matched, how to other systems that use PDO implement the equivalent functionality? There must be a way.
Comment #129
bjaspan CreditAttribution: bjaspan commentedI may be in the process of having an epiphany on the insert-or-update topic. Please stand by. :-)
Comment #130
bjaspan CreditAttribution: bjaspan commentedSo it turns out that pgsql PDO also returns rows affected and not rows matched for UPDATE operations. This leads me to conclusion that the answer to the question "How do you implement if (!update()) { insert(); }" is "you don't." The solution is to implement "if (!insert()) { update(); }" instead.
Consider:
* The whole topic of a joined insert/update operation is only meaningful if you have a primary key and provide it to the insert/update query (* see note). Otherwise, you can't construct the WHERE clause of the update without additional information.
* If you try INSERT (pkey, other data) it will either succeed, in which case the pkey did not yet exist so the INSERT is correct, or it will unambiguously fail with a "duplicate key" error.
* If the INSERT fails, the pkey exists, so the UPDATE is called for. You then do not need to know whether the UPDATE affects any rows. You know the row to update exists which is all that matters.
I previously had InsertQuery_pgsql trying the update first then, if it "failed", doing the insert. This didn't work because the update would succeed even if the pkey did not exist yet; it would affect 0 rows, but not result in any errors. I changed InsertQuery_pgsql to do the insert first (inside a try/catch) and do the update if it fails. Presto! Happy code.
I observe that this approach should work perfectly well on a "generic" database so we could, if we wanted, implement orUpdate() functionality in the database.inc generic classes. But since the code won't be ideal for mysql and won't work for pgsql (no blob support), I do not think there is a point.
The pgsql driver currently checked into svn successfully installs Drupal and passes all of the tests Larry has written so far. Note that it is far from done. If you look at how InsertQuery_pgsql and UpdateQuery_pgsql are written, you will see that they need to do a crazy amount of data massaging to get the bindParam() calls right. This requires some re-thinking of how data is massaged in the top-level InsertQuery and UpdateQuery calls, and in the DatabaseCondition class. Also, some other bugfixes and cleanups are needed.
* Note: A sub-case is when the primary key is type 'serial'. I assert that a dual insert/update query in this case makes no sense. If you are "inserting or updating" an id-based object and you have an id, then you know you are updating; otherwise you know you are inserting. As I've previously explain in this issue, it is (rather, it should be specified as) illegal to insert an explicit type 'serial' value under any circumstances because it breaks the way auto-increments are implemented on pgsql. So if someone calls db_insert('node')->fields(array('nid' => 12, ...)), that should just be an error and throw an exception. If they put ->orUpdate() on the end, it should probably still be an exception because they know perfectly well that nid 12 exists (or else where did they get the id from?), but we could for convenience just silently convert it to an update query with no attempt at insert.
Comment #131
bjaspan CreditAttribution: bjaspan commentedQuestion: What should InsertQuery::execute() return?
DatabaseStatement::execute(), derived from PDOStatement, returns "TRUE on success, or FALSE on failure." without defining what success and failure means (I assume "failure" means "threw an exception" in which case FALSE will never actually get returned).
Class Query is our invention. Query::execute() is abstract and its return value is currently not documented.
InsertQuery::execute(), derived from Query, is also not documented but is written to return $this->connection->lastInsertId(). That's somewhat sensible except that not all inserts have a lastInsertId() (not all tables have an auto-increment column). But presumably the caller inserting into such a table knows not to expect a meaningful result. However, InsertQuery also supports orUpdate(). If an insert query may create a new row with a type 'serial' column or update an existing one, what should execute() return?
Actually, this dovetails nicely with my previous comment (I did not realize this when I started this comment).
* If you call db_insert('node')->fields(array(...))->execute(), the return value should be lastInsertId().
* If you call db_insert('node')->fields(array('nid' => 12, ...))->execute(), the return value should be Exception('DON'T DO THAT'). You can't provide an explicit insert value for a type serial field.
* If you call db_insert('node')->fields(array('nid' => 12, ...))->orUpdate()->execute(), the return value should either still be DON'T DO THAT or, if we are providing the convenience behavior I described in which this is converted into an update, the return value should be 12.
Comments?
Comment #132
Crell CreditAttribution: Crell commentedInteresting. I am actually going to propose something a bit radical.
The reason for including orUpdate()-esque functionality at this point is that, for MySQL, we could no longer do the update-or-insert routine. Therefore, we needed to build something that could handle that concept, and punted the database-specific implementation to the driver. However, it looks like that database-specific implementation is a heck of a lot more complicated than anticipated. From what Barry's saying, it looks like the same problem exists for at least Postgres anyway so I am suspicious that it will be a global PDO problem.
Therefore, I propose that we instead switch to insert-or-update as our standard routine and punt on the orUpdate() functionality. Since that's not critical for the base implementation (we can use insert-or-update instead) and it is turning out to be a PITA, let's save it for a follow-up patch and then convert core to use insert-or-update. Then we can set InsertQuery to return lastInsertId() or FALSE (or just let is throw the exception?). The caller can then do its own IF statement. I'm of the mind that "don't babysit broken code" implies A) It's the callers job to know if the return value is at all useful, not ours; and B) It's the caller's job to not try to explicitly set the primary key, not ours.
That should simplify the InsertQuery code considerably, and remove the buggiest parts of it to later. Barry, any objection?
Comment #133
Dries CreditAttribution: Dries commentedCrell: I'm not against dropping support for the update handling, but it does make one wonder. One of the primary motivations of the proposed database abstraction layer (at least to me) is to be friendly towards database specific tricks. If we keep removing features, it becomes less compelling and it begs the question if we need to make such sweeping changes. I still think it is the right thing to do, but I do think it would be good to flush out the details as part of the first patch.
Comment #134
Anonymous (not verified) CreditAttribution: Anonymous commentedRe: Update or Insert
Could we use the MERGE methods discussed at http://en.wikibooks.org/wiki/SQL_dialects_reference/Write_queries/Replac... to supply the functionality? Or perhaps it is just best to let the caller take care of this functionality; I tend to agree with that thought. The information from the reference I gave can then be incorporated into the documentation.
Comment #135
Crell CreditAttribution: Crell commented@Dries: There are many motivations for the new system; allowing database specific optimization is one of them. That doesn't mean we need to implement every optimization, however. Multi-insert and INSERT DELAYED are easy, and offer a big performance boost. Duplicate-update functionality is apparently much more complex than we anticipated. I'm not saying we shouldn't do it, but I'd rather skip it and come back to it than spend the next 3 weeks figuring that part out only to then not have any time to make sure the select-builder works, or the master/slave replication, etc. Many of the details to "flush out" are the same as on update statements anyway, I suspect, and we can't really drop those. :-)
@earnie: That's a good tip on how to implement this functionality on each specific database, but as it shows the actual structure and syntax is wildly different on different databases. (Also, MySQL's REPLACE syntax is not a merge; it's a delete/insert cycle.) Although perhaps we should simply factor this functionality out entirely into a db_merge(), and then let MySQL make an insert statement out of it, Oracle do whatever weirdness it has, etc?
Comment #136
Anonymous (not verified) CreditAttribution: Anonymous commentedYes the MySql REPLACE is a no-go but
is also supported in MySql. The ``IF EXISTS'' syntax exists for others as well (MsSql, Oracle) but the syntax I've found doesn't use ``END IF''.
Comment #137
Anonymous (not verified) CreditAttribution: Anonymous commentedOr better, after a pdo->execute to update use if (pdo->rowCount() = 0) then pdo->execute a insert. This is supported by all of the PDO DB. pdo->rowCount() should only be used for update, insert or delete. Not all DB would report the same result for SELECT.
Comment #138
Crell CreditAttribution: Crell commented@earnie: The problem, as mentioned above, is that on at least MySQL and Postgres with PDO rowCount() is not useful for that check. It returns the number of rows *affected*, not the number of rows *matched*. That means "INSERT INTO variable (name, value) VALUE ('test', 'test')" will return 0 if test already exists and has the value test. If we then use that 0 to mean "OK, now do an insert", it breaks. That's the problem we're trying to solve, and I think at least for now Barry has the right answer: Do insert()-or-update() instead, catching the insert failure to trigger an update, and don't worry about merge-style queries for now.
Comment #139
bjaspan CreditAttribution: bjaspan commentedI actually see no reason to remove orUpdate() functionality. I've been arguing that the interface we define to it should be simpler but since my epiphany that db_insert()->orUpdate() needs to be implemented as insert-or-update instead of update-or-insert, the implementation is not a problem. mysql can use INSERT ... ON DUPLICATE UPDATE (note: that's insert-or-update), pgsql and anything else can do try { insert(); } catch { update(); }, and other drivers can use special syntax if available.
From an API perspective, here is a summary of my recent suggestions (I've written a lot on this thread and may not remember everything). These are now all easily implementable, we just haven't agreed on the interface.
## InsertQuery
* fields($fields, $values = NULL). If $values is non-NULL, it is an array of values and $fields is an array of keys; otherwise, $fields is assoc. This is as currently implemented.
* values($values). Can provide additional values regardless of how fields() was called. As implemented.
* orUpdate($keys = NULL). $keys is an array of field names, not assoc, no values, no expressions. Enables or-update functionality, but only for the listed keys, and only to the constant values given to fields()/values(), and only if exactly one set of values is provided. As a special case, if $keys is NULL, all keys given to fields() are updated. Yes, this is less functional than the current implementation, but much cleaner, and if you really want the more complex behavior, just call db_update() yourself if the insert fails.
* orUpdateExcept($keys = NULL). Same as orUpdate(), but keys listed in $keys are not updated. This means that orUpdate(NULL) is the same as orUpdateExcept(NULL), but so what.
* execute(). If you are inserting into a type 'serial' pkey table, returns lastInsertId(), otherwise the return value is undefined. If you call orUpdate*(), the return value is undefined. Here, I am accepting Larry's suggestion for simplification.
## UpdateQuery
* fields($fields, $values = NULL). Same as InsertQuery, though this is not currently how it is implemented.
* expressions($expressions). $expressions is an array of expressions like 'age=age+1' that are inserted literally into the SET clause of the UPDATE statement. No one has yet commented on this idea.
Comment #140
bjaspan CreditAttribution: bjaspan commentedNow I'd like to summarize what I've learned about how fields and values need to be treated within the drivers.
The mysql driver calls queries like this:
In other words, it passes an array of arguments to the execute() method whose keys match the placeholders inserted into the text of the SQL. All it needs to do is make sure that the placeholders in the query are the same as the placeholders in the args array and that the values in the args array line up with the keys correctly.
The pgsql driver is more complicated. It does something like this:
The trick here is in the function column_type_for_the_field($value). It cannot just operate on $value alone (we might be inserting a PHP string into a varchar field or a blob field). It needs the *type* of the column this placeholder is going into. That information is in the schema, so what it needs is the *name* of column the placeholder is going into.
Some parts of database.inc make this easy but other parts may it impossible or inefficient. InsertQuery::fields() gets it right because $this->insertFields contains the name of each field and each($this->insertValues) is an array of the values for those fields. So, InsertQuery_pgsql::execute() can (and does) do something like this:
Compare this to (a slightly simplified version of) UpdateQuery::fields():
The relationship of the field name to the placeholder is lost (it is only preserved in a stringified form). UpdateQuery_pgsql::execute() gets around this by storing its own copy of $fields in an overridden fields() method and then doing a bunch of array manipulation to get the relationships back.
Class DatabaseCondition is even worse (or maybe just equally as bad as UpdateQuery::fields()). The relationship between the fields being tested, the placeholders, and the values are completely obscured. If we are willing to assume that all condition columns are "normal", then DatabaseCondition::arguments() returns an array of ('placeholder' => value) that we can use for bindParam(), but if we want to be able to say something like "WHERE FUNCTION_OF(blob) = value" then we need to preserve the field name to placeholder relationship here too.
What we need is some organized, efficient, and re-usable way to create and preserve the fidelity of field names, placeholders, and values so they are available throughout the query. This probably isn't hard to come up with but I have not spent the time yet to think about the right way to do.
Comment #141
Crell CreditAttribution: Crell commentedRegarding expressions(): I guess I don't see the need for it. That's my comment. :-)
Regarding orUpdate(): I will try to refactor it again to the simpler version you suggest tonight and see what happens.
Regarding saving field information: As I mentioned above, we can delay processing until execute() and __toString() but that will mean a double-pass. If we're OK with that, I can do that in the base classes and then possibly switch back to the pre-parsing version for MySQL, where we can get away with it and it's faster.
Regarding DatabaseCondition... Since the condition portion of a query will never be modifying data, does it even need the field type information?
Comment #142
Dries CreditAttribution: Dries commentedCrell et al: time permitting, it would be useful if you could update and extend the following overview table. It might sounds like a little bit of work, but it might be useful for documentation/blogging purposes later on. Until then, it would provide me and others a better overview of the motivations.
required
makes it easier
or cleaner
not necessary
more research
Comment #143
hass CreditAttribution: hass commentedFeature = Cross database support (MsSQL, Oracle, etc.)
New DB layer required = YES
Comment #144
Crell CreditAttribution: Crell commented@Dries: Well, that depends on what qualifies as "new DB layer" and therefore whether it requires it. The new DB layer does implement quite a bit. :-) I don't think it can be done as a simple table, but I'll see about posting a better analysis of what depends on what either here or on my blog shortly.
Comment #145
Crell CreditAttribution: Crell commentedA picture is worth a thousand words, so here's a thousand words on the feature dependency is here. :-) The middle line is the "goal features" that we're trying to achieve. Normal boxes are a developer-facing feature. Boxes with sidebands are internal "features" that don't directly matter to a developer. Solid lines indicate that a given change/features is, IMO, essentially required to implement the feature. Dashed lines indicate a feature that could be implemented some other way, but doing it the specified way during this work is, IMO, the best route.
Comment #146
Crell CreditAttribution: Crell commentedFor those watching, I've done the following (from the svn log):
- Add "required" flag for transactions.
- Add TransactionsNotSupportedException.
- Add unit tests for update queries.
- Fix return value from runQuery().
- Reverse $operator and $value in DatabaseCondition::condition() to make sense.
- Support conditional operator rewriting. (Planning ahead for Postgres' ILIKE.) This one still needs work before it can actually be overridden.
- Add simple DELETE test. (Most of DELETE is the same as UPDATE.)
- Move parseWhere() method to be just the __toString() of DatabaseCondition.
- Implement Countable interface on DatabaseConditional.
- Rename SelectQuery::limit() to SelectQuery::range() to be more database agnostic.
I have also further considered the merge query question, and I am even more convinced that it needs to be a separate query type from insert. The semantics are very different on everything but MySQL. I came to this conclusion when putting in exceptions for avoiding multi-insert and insert-or-update at the same time and realized that it was a sure sign that we were piling too much into a single query routine. So my next step will be to separate out merge queries into a separate object entirely.
To that end, I am thinking of the following API. Feedback welcome.
For MySQL, this folds down to INSERT ... ON DUPLICATE KEY UPDATE. For other databases, see the link in #134 above. The degenerate case is try { insert() } catch () { update() }, but most databases can do better. (Or maybe the ANSI MERGE statement, but it's not like anything supports that. :-) )
A note: I cannot think of any case where you'd want to run an expression on a LOB field. On some databases I'm fairly sure you cannot. Therefore, we do not need to worry about field-specific handling in expressions. Databases that require extra field handling for non-LOB fields we just won't support as they are just plain dumb.
That should also slice out all of the complex parts of db_insert() and let us move on to bigger and better things. Potentially we can get a useful return value from db_merge() (TRUE or FALSE depending on if we inserted or updated), but only if the database itself will give us that information reliably. TBD.
Comments?
Comment #147
bjaspan CreditAttribution: bjaspan commentedIn general I agree with factoring all orUpdate() functionality out of InsertQuery. That way, Insert and Update both represent simply their primitive operations, with all the complex goo in MergeQuery. Good choice.
I suggest that we could even commit a PDO patch without db_merge() and add db_merge() in a subsequent patch. However, actually most/all of the API issues I'll mention below with db_merge() apply to db_update() anyway, and the simple db_merge() implementation is just try/catch, so perhaps separating it to another patch would not save us anything.
Specific comments on your MergeQuery interface:
* Specifying the key explicitly via a method call does not save you from accessing the schema. Perhaps on MySQL it does but any db with field-type-specific behavior needs the schema anyway. So, I question the redundancy of having to specify it every time. Also, it seems non-orthoganal to require it for MergeQuery but not {Insert,Update,Delete,Select}Query.
* If we do have a key() method, it needs to accept an array because tables can have multi-column primary keys.
* I still really dislike having a single array contain assoc entries for key/value and indexed entries for expressions. IMHO, it is a design flaw of PHP that the array() type allows this dual behavior and we should not build that design flaw into our API. It's just ugly and confusing.
* Please provide an example where you'd provide different values for the update operation than the insert operation, *excluding* expressions.
Comment #148
Crell CreditAttribution: Crell commentedI suggested skipping merge queries for now above, but Dries said he didn't want to cut back features and make this update less useful.
Avoiding schema on MySQL and SQLite (and I think MS SQL Server, too) is worthwhile, IMO. Also, at a conceptual level, you don't need a key per se on any other query. On Merge queries, they generically read as "ensure that there's a row with key fields X, Y, Z and additional fields A, B, C, one way or another". Hm. I guess that would exclude expressions, but chx is right that those are useful. Perhaps key isn't the right word to use there, since I suppose it doesn't strictly speaking have to be the primary key field(s).
I guess we have to agree to disagree on arrays. I find the myriad ways that PHP arrays can be used to be one of its greatest strengths. :-)
Any other thoughts on merge queries or expression handling? Anyone? Beuler?
Comment #149
chx CreditAttribution: chx commentedPHP arrays are wiz. I like the current update syntax. it's easy and intuitive. But, I find node_get_types intuitive too. I am weird.
Let's reiterate the two type of queries where core needs merge operation (by examples): variable_set where we want to make sure a given name,value pair exists in the database regardless what was there before and statistics where we want to insert an initial value and increase later. Patch currently supports these so ripping out merge is not an option. If we specify the keys then you can know --regardless of schema-- which operation to perform. Keys are definitely not needed for anything like {Insert,Update,Delete,Select}Query which executes only one kind of operation.
Comment #150
bjaspan CreditAttribution: bjaspan commentedHmmm. I'm sorta going in a circle:
I think I'm coming to agree that the key() method is sensible because MergeQuery() is fundamentally different from {Insert,Delete}Query(). MergeQuery says "Please update any rows matching the key KEY, and if there are not any, please insert instead." So it makes sense to specify KEY. However, given that we're specifying it and not just taking the primary key from schema, it seems logical to ask whether KEY really always needs to be the primary key. In the quoted translation above, KEY is really acting more like a WHERE condition. So perhaps MergeQuery() should have a where() method instead of a key() method.
However, the only reason that "try { insert(); } catch { update(); }" works is because we know the insert() will fail if the primary key already exists. If key() is replaced by where(), or in general can be anything *other* than the pkey, we cannot make that assumption. We would then have to do "update(); if (rows_matched == 0) { insert(); }" and, as we've established, we can't get rows_matched reliably. Therefore, key() cannot accept anything other than a pkey or unique key, and it is probably best to restrict it to pkey because all the databases' special hacks (ON DUPLICATE UPDATE, MERGE, etc.) for this purpose will require it.
So, the only advantage to requiring the key() method is avoiding the dependency on the schema for those databases that do not otherwise require it anyway. Why is that a desirable goal? The only reason I can think of is performance. Not having key() means the query needs to call a method to retrieve the schema for the table and (the first time that table is touched per request) unparse the serialized schema structure. Having the key() method means that we're explicitly requiring a method call too, though we do not have to unserialize the schema. So the performance gain is not unserializing each db_merge()d table's schema once per request.
The disadvantage is that we're introducing redundant information (== more difficult to maintain, less reliable) into our code. We have the info we need in the schema, and we're not using it.
Whatever. I'm not so motivated to argue about it.
Comment #151
bjaspan CreditAttribution: bjaspan commentedIn #147, I asked:
* Please provide an example where you'd provide different values for the update operation than the insert operation, *excluding* expressions.
If there is not a good answer to that question, there is no reason that MergeQuery::update() needs to support assoc key/value pairs instead of a simple list of fields to update to the values given to values().
Also, no one has offered a disadvantage of the expressions() method I'm proposing for UpdateQuery and MergeQuery. The advantage is that is simplifies the API from a user's point of view because then fields() and values() take *either* assoc arrays *or* indexed arrays of constants, not a mixed assoc/index array, while expressions() always takes an indexed array of expressions. Consistent == simpler.
Comment #152
Crell CreditAttribution: Crell commentedBesides the performance difference (whatever it is), I find explicitly specifying the key to be more readable. It's like a pivot point. "Set [keys] => [stuff]" is a logical way to think about the operation. It's not really redundant since the key would have to be placed in fields() anyway if it's not in key(), so it's the same amount of data, just passed differently.
As for expression(), I'll have to think about it. I don't personally find anything unclear about a combined syntax, but I will toy with it in code and see what happens. I'll try to get to this tonight or tomorrow night unless someone else has a brilliant idea.
Comment #153
bjaspan CreditAttribution: bjaspan commented@crell: "It's not really redundant since the key would have to be placed in fields() anyway if it's not in key(), so it's the same amount of data, just passed differently."
Okay, I'm convinced, db_merge()->key() is fine. It does need to support multi-column keys, but the method name should still be key() since the multiple columns define a single key for the query.
Comment #154
phpdude CreditAttribution: phpdude commentedSubscribing
Comment #155
bjaspan CreditAttribution: bjaspan commentedLost in the comment clutter has been my suggestion about query tags. From #111:
As for the db_rewrite_sql() case, basing it purely on base table isn't sufficient either since (e.g.) some node queries should involve all nodes and some should involve those the user has permission on. I was thinking what we need are query tags. So node_query_alter() would document that it operates on all node queries having the "node-access" tag by doing the appropriate joins, and callers that want that behavior do db_select('node', ...)->tag('node-access')->etc().
Without this feature, node_query_alter() will have to add node-access joins to EVERY node query, which is incorrect behavior. Today, a module author decides whether to do that by calling db_rewrite_sql() or not.
In this particular example, I might support tag('no-node-access') so the access joins happen by default, but that is a separate issue from the feature of query tags in general.
Thoughts?
Comment #156
moshe weitzman CreditAttribution: moshe weitzman commentedThese query tags are what we called 'hints' and are currently sent as the 4th parameter of db_rewrite_sql(). they are seldom used, but as barry said should be used more. So, please keep this feature in some fashion.
Comment #157
bjaspan CreditAttribution: bjaspan commentedI just thought of another snafu.
This new db layer (at least for some dbms's) requires schema information about tables for (at least) non-SELECT queries. This makes it impossible to create a local temporary table and INSERT INTO/UPDATE it, because the temporary table will not be exported by any module's hook_schema.
Actually, I now also realize that while we have db_create_table() we do not have db_create_temporary_table(), and probably should.
At the moment I'm thinking that db_create_temporary_table() can just add the schema for the table it is creating to a temporary schema to be returned as part of the normal schema for the current request (but not saved in the schema cache) so that INSERT/UPDATE queries can access it. I'm not yet sure if this is sufficient.
Comment #158
bjaspan CreditAttribution: bjaspan commentedRe: #157, I'm not sure what to do about
which performs CREATE TEMPORARY TABLE SELECT. The function is not passed a schema structure to add to the global schema. If the table is only queried by SELECT there is no problem but if the code wants to INSERT into it, there is.
Comment #159
chx CreditAttribution: chx commentedWell, both MySQL and PostgreSQL supports
CREATE TEMPORARY TABLE ... AS SELECTso that's why we Drupal had no need for more elaborate definitions. The supposed use of temp tables are to create a temp table and the select from it... More than that -- do we need to solve everything in the scope of one patch?Comment #160
bjaspan CreditAttribution: bjaspan commentedMy point is that with the patch as it currently exists, on pgsql it will be *impossible* to insert into/update a temporary table using db_insert() or db_update(). db_query() will still work (because it does not try to inspect the scheme) provided you do not use any column types that require special treatment. That's probably an acceptable restriction for now, but it is worth noting.
Comment #161
Crell CreditAttribution: Crell commentedRegarding "Query tags": If it's a current feature, then yeah, I guess we should keep using it. At which point I agree with Barry that it can absorb the rest of db_rewrite_sql's flags, so ->alterTag('node_access') would be a message to node_query_alter() to do whatever it's going to do for node_access queries (instead of relying on base-table=node and primary field=n, those are implicit in the node_access tag.) I am sure someone will come up with something else cool to do with this functionality. :-)
Regarding temp tables: If the current mechanism will work for MySQL, Postgres, and SQLite, then I am perfectly happy to say "noted" and deal with that another time.
Comment #162
Crell CreditAttribution: Crell commentedMerge queries should now be complete. Because I realized expressions could potentially include placeholders, that forced it out into a separate method. That has now been applied to both update and merge queries. It also meant that I had to switch update queries to late parsing in order to get the precedence rules to work. That should make postgres easier for you, Barry. :-)
Comment #163
bjaspan CreditAttribution: bjaspan commentedFYI, over the weekend I also did some work on MergeQuery, making the generic implementation in database.inc work, and fixed a few other glitches around the code. I made all the pgsql tests, including the new merge tests, work again. I am part-way through making multiple blobs per query work (a limitation of the current pgsql code is that they do not) and discovered entertaining ways to crash Apache in the process. :-)
It looks like storing a connection's lastStatement is a permanent requirement, not something we can remove after taking out db_affected_rows(), because it is the only way to get the error code from (e.g.) a db_insert() statement. Well, possibly we can use the DATABASE_RETURN_STATEMENT option, though InsertQuery does not currently support it.
Of course, Larry new all of this already because he had to svn update the changes before committing... :-)
Comment #164
Crell CreditAttribution: Crell commentedBut of course! :-) I was wondering how we could get the statement back (and ran into yet another error code that it could return for some reason; I do not understand that in the slightest). Since we're calling insert() directly, we can't override it. I just conceptually hate having to get it from the connection object. I guess that's a cleanup for later, though, not something launch-critical.
There are 3 things left that I see which need doing:
1) Right now, the Conditional object generates globally unique placeholders. That is actually a problem when we try to query_alter a query, since the placeholders could then change within a given query from one run to the next depending on what other queries have already run. It needs to be query-unique. That means passing the query object to the conditional, which right now we have no facility for via db_or() and company. My only thought here is to switch to late processing and pass in a query object to a render() method, replacing __toString(). The advantage there is that we can also thereby get the connection object, which allows us to move the specials listing to the connection object where it is database-type specific, so that Postgres can cleanly use ILIKE instead of LIKE and the like. Barry, if you have any suggestions here let me know.
2) I'm starting to like the "query tagging" idea to replace messy base-table and base-field declaration. Unless someone has an objection, I am going to switch the select builder over to that. That also means a query that has no tags will not get sent through hook_query_alter(), so only queries that care will be altered, which is a small performance boost as well since we can often skip the alter step.
3) Refactor the select builder to be more Views-friendly. After talking with merlinofchaos and reading over the Views code again, it looks like while the current setup is nifty, it doesn't cover all of the bases we need. I am therefore going to refactor it to be more like the views query object (although not identical), which should make a D7-version of the views query object easier. I suspect we'll lose the fluent API on Select that way, but it cannot be avoided.
I'm setting this to CNR so that others know there's stuff for them to look at, specifically in the mutator query area, which is now complete save for point #1 above.
Comment #165
bjaspan CreditAttribution: bjaspan commentedYou can set it to CNR but it also absolutely needs work still.
I'm not sure I agree with not sending queries with no tags through hook_query_alter(). Some modules (e.g. devel) might want to operate on all queries, for example by logging them, caching them, checking them for efficiency or correctness, or who knows what.
Comment #166
Anonymous (not verified) CreditAttribution: Anonymous commented@Crell: here's the review i promised on #drupal. hope it makes some sense, feel free to ping me about it :-)
kudos to all involved in getting the patch this far - great work! i'm assuming the best way to help out from here on is to write tests that break things? ;-)
here are some things that don't seem obvious to me, *none of which i consider blockers in any way*. they are just my take on possible improvements.
- __toString --> why not a method called getSql or similar. seems more obvious than using __toString. is it just a keystrokes thing, or was there another consideration? the fact that we need comments like:
speaks against doing it that way IMO.
- the use of the term 'condition' feels a bit too overloaded - can we use something that can be described in english a bit more clearly, like 'a query can have one or more clauses (eg, where, having etc) depending on its type, and each clause can have one (or more) conditions?'. at the moment we are using 'condition' to refer both to what i've called a 'clause' and a 'condition' above. i'm totally not set on 'clause', just that we make a distinction.
- not sure why the various query objects implement the condition (or whatever we call it) interface? put another way, why do we want code that uses query objects to be able to use $query->condition at all, rather than $query->, eg. $query->where or $query->having? seems much more explicit as to what you are adding to a query, given that some conditions don't make sense for some queries. currently it feels like we are leaking internals about the condition code out into the query interface.
- could we make the different types of conditions extend a base condition, and use composition for each type of query object? e.g. in UpdateQuery->__toString we'd have something like:
Comment #167
recidive CreditAttribution: recidive commented"- __toString --> why not a method called getSql or similar. seems more obvious than using __toString. is it just a keystrokes thing, or was there another consideration? the fact that we need comments like:"
__toString()is a PHP magic method. It allows you to manipulate the object as a string in string contexts like when concatening you can use something like'foo' . $object . 'bar', instead of'foo' . $object->getSql() . 'bar'.Comment #168
Anonymous (not verified) CreditAttribution: Anonymous commented@recidive: ok, i guess i wasn't being clear enough. my question is not 'how does __toString work', but 'is using implicit string casting and php's __toString built-in as obvious as a well named method call?'
Comment #169
fgm(subscribing)
Comment #170
Crell CreditAttribution: Crell commentedWe went with __toString() because it was a convenient way to translate as "make a prepared statement string out of this query". It could have been done with a ->compile() method, too, I suppose. I defer to Dries on that one. We documented it inline because most Drupalers are not used to seeing magic methods, if they're used to seeing methods at all. :-)
I'll have a look at the documentation to try and clear up use of "condition".
The use of the condition interface on query objects is deliberate. Particularly for multiple conditions, I felt this:
was nicer than this:
Because we have a fluent API, I want to avoid having some methods return one object and other methods return a different object. That just gets very confusing. For SELECT queries we do have 2 different conditional objects, WHERE and HAVING, but I kept the same API with just different wrapper method names for HAVING for consistency, and because I can't remember ever seeing a HAVING clause in Drupal anyway. :-) Arguably we should do that on SelectQuery, UpdateQuery, and DeleteQuery since InsertQuery and MergeQuery don't use that API, and I may switch to that later for cleanliness, but while the API is still being worked on it was just easier to move it up to the Query class.
I'm not sure I follow your last inquiry. What extend who?
Comment #171
hass CreditAttribution: hass commentedWhere can we find the patch for review?
Comment #172
Crell CreditAttribution: Crell commentedThe best place to get it right now is to check it out from subversion using the link in the first post.
Right now it's a bit unstable as I'm trying to resync it with HEAD, and simpletest changed quite a bit. I've fixed that, but now the schema seems to not be pulling data at all. Barry, can you update and have a look at that? I've a try-catch block and some dpm() calls in the setup routine that shows what the problem is.
Comment #173
sunQuick question: Since
$db_urlhas been converted to$databasesI wanted to make sure the new DB layer will still allow to alter this array dynamically at runtime. I'm doing this in Drupal vB (example: drupalvb.inc) and Migrator modules, so users are able to setup an additional connection for the remote database in the module settings and must not alter settings.php. Will that still be possible?Also, shouldn't
$db_prefixbe moved into the$databasesarray? Why should we force users to have the same table prefix in all databases? I'm currently hacking around this limitation in both modules (see example above).Comment #174
Crell CreditAttribution: Crell commented$databases is still "global", so as long as you modify it before the first query is called, you can do whatever you like. You should be able to add to it as well, as long as you do so before a query tries to access that database connection. Basically no different than now.
For $db_prefix... Don't scare me. :-) I suppose that does make some sense, actually. I'm tempted to say "later", but on the flipside this patch is already doing so much, what's one more change? :-)
Thoughts from others on $db_prefix?
Comment #175
Anonymous (not verified) CreditAttribution: Anonymous commentedI've done some pretty stupid stuff as in this example:
Comment #176
hass CreditAttribution: hass commented$db_prefix should be DB specific, only a global definition is often too limiting.
Comment #177
sunAnother issue: In method
openConnection()there is already dummy code for error handling, like indb_connect()currently. In Drupal vB (#253076) I have to fork mysql and mysqli connection functions from db_connect() to test a database connection, because db_connect() immediately displays a maintenance page and there is no way to prevent this. If this was supported by the new db layer, install.php may benefit from that, too.Comment #178
Crell CreditAttribution: Crell commentedI'm not sure I follow what you mean in #177. Can you clarify?
Comment #179
sunCurrently, there is no way to test a database connection. db_set_active() invokes db_connect() (in D5/6) and if the connect fails, the script exits displaying a maintenance page. That means, even if your primary database connection is perfectly valid and working, but an additional one is not, Drupal displays nothing else than a maintenance page stating that it is unable to connect to the database (which is not true).
My suggestion is to (a) either not hard-code, respectively, tie the maintenance page into openConnection(), or (b) add another method testConnection(), which could be used to test a database connection during installation of Drupal and by module developers that are doing stuff like me.
So, in short: db_connect() should be clean, just doing no more and no less what the function name implies.
Comment #180
baldwinlouie CreditAttribution: baldwinlouie commentedsubscribing
Comment #181
RobLoachOnly Crell would make an issue with "The Next Generation" in the title. Subscribing!
Comment #182
Jamie Holly CreditAttribution: Jamie Holly commentedSubscribing
Comment #183
bjaspan CreditAttribution: bjaspan commentedI just fixed a few glitches in database.inc and updated the pgsql driver to work again. The pgsql driver is still kind of a mess. I duplicate the bindParam() loop for the insert and update queries in very slightly different forms, and I have to essentially duplicate some code from the parent InsertQuery and UpdateQuery classes with some changes to support the bindParam() approach.
I'm thinking that the "clean" approach would be to move the bindParam() logic into DatabaseConnection_pgsql::runQuery() which could then convert its $args array into a bunch of calls to bindParam(), all in one place. For this to work, runQuery() would need to take a Query object, not an SQL string. I know that db_query() passes SQL to runQuery(); we could handle that by having db_query() pass a class SqlQuery extends Query object which wraps the SQL. But I'm not yet sure I love this approach, either.
The tests all pass except for generating some exceptions when db_create_table() is called with an empty table structure. Oddly, the tests pass anyway, so clearly the table is being created somehow. Not sure what is going on yet.
Comment #184
Crell CreditAttribution: Crell commentedSimpleTest currently has a bug where exceptions are not considered failures. That is, it prevents exceptions from breaking the script but it does not actually test or handle them properly. There is an open feature request for that.
What about putting a runQueryObject() method in DatabaseConnection_pgsql which does its thing, and then calls $this->runQuery()?
Comment #185
cfennell CreditAttribution: cfennell commentedsubscribing
Comment #186
litwol CreditAttribution: litwol commenteddiverting my attention here.
Comment #187
chx CreditAttribution: chx commentedThe incredible shrinking patch! (Note: I just rolled it against HEAD.)
Comment #188
chx CreditAttribution: chx commentedUh huh. I did a few cvs up and now it's indeed a lot smaller.
Comment #189
Crell CreditAttribution: Crell commentedSo, a status update for those playing our home game:
Since the last update the major change is a brand new SELECT query builder. This one drops the fluent API in favor of being able to handle managed aliasing and auto-aliasing of tables and fields. From writing the unit tests for that, I believe that is a better API as well as one that should, hopefully, make life easier for Views. (It does NOT replace the Views query builder, but the intent is for the Views query builder to be able to leverage it.)
It also introduces two new concepts: Query tagging and hook_query_alter(). The idea is that any built select query can be "tagged" with one or more strings and can have metadata assigned to it (such as, say, a View object). Before the query is run, it is passed through hook_query_alter() in essentially the same way as hook_form_alter(), and for the same purpose. Modules can check to see what tags a query has and modify it as needed, even completely replacing it. Because all properties of the query are delayed-compile, it is very easy to dip into and tinker with virtually any aspect of the query. This offers 2 advantages:
1) hook_views_query_alter() is now in core for *any* built query.
2) In a follow-up patch we can drive a stake through the heart of hook_db_rewrite_sql() and its regex madness. It gets replaced by built queries with a tag of "node_access", which allows node_query_alter() to do whatever it needs to do. It also makes it much easier for other query-altering operations to take bizarre actions. Because the documentation (of which there is more than code, I think) specifies that tags should follow PHP identifier rules, we can easily add dynamic query alter hook support (hook_query_node_access_alter()) later if we want to.
Note that there *is* a performance hit for all of this building and compiling and altering. That's why built queries should be used *only* for either queries that you want to be alter-able or queries that you need to build programmatically based on various parameters. The vast majority of SELECT queries will still go through db_query() as now.
At this point I consider the new API "rev 1 complete", and I do not plan to add any more functionality at this point unless Dries demands we do so in order to get it into core. :-) While there are other things that we could do, I really really want to get this thing into core so we can refine it there rather than maintaining a 400 KB patch any longer. We also do need to update the rest of core to use the new APIs so that we can drop the BC layer, and that will take time.
What is not in this patch:
- UNION built queries. We can add this later.
- Sub-selects in the FROM statement of built queries. We can add this later. (Subselects in the WHERE clause are supported, however.)
- Changes to the way the initial database activation works mentioned in #177. The current methodology models the way we do things now as closely as possible, and I have to draw a line somewhere to prevent even further feature creep. We can refactor that later once the main patch has landed and we don't have a forked Drupal.
- Moving database prefixes to be connection-specific as mentioned in #173. I actually think that is a very good idea, but given the way SimpleTest works right now (it uses database prefixing) changing that would hose SimpleTest, too, and I simply do not have the expertise or time to deal with that as part of this patch. I would support that as a follow-up patch, however, if we can not break SimpleTest in the process.
- Master/Master replication. After talking with Narayan Newton a few weeks ago, we concluded that while the code here would properly split queries between active masters it would not actually help with the myriad synchronization issues that master/master replication involves, which may not even be solvable in a system like Drupal that doesn't tolerate data failure. Master/slave replication, however, should be solid and has his thumbs-up.
- The Postgres driver still needs a little work, but Barry and I are working on that. I wanted to get MySQL (which 98% of us use anyway) out into people's hands.
I am actually very confident in the bug-free-ness of this patch (assuming it applies properly, which is always iffy on a patch this size :-) ). That's because of the included dbtest.module, which contains over 1000 lines of unit testing. Specifically, 55 separate API unit tests that both exercise the API and serve as documentation and examples, just as good unit tests should. Unit testing is Awesome! (Druplicon: Awesome, just like Drupal!)
Dries: Given that the unit tests do require a schema hook and a query_alter hook, they cannot be part of system module and possibly not part of simpletest.module, either. My current recommendation is to maintain a "database_test.module" in contrib that is basically the dbtest module as it exists now that we just keep in sync. I don't want to hold up the patch itself because it's an oddball case for SimpleTest in its current state. :-)
Unless someone can find a fatal flaw in the current design or a critically missing bit of functionality, I would call this RTBC as soon as Postgres stabilizes. Then the really fun part begins. :-) (Converting core, SQLite driver, additional db targets, etc.)
Comment #190
catchThere's several tests that don't apply against so probably needs a re-roll.
More importantly, install is broken:
edited to fix crazy typos.
Comment #191
bjaspan CreditAttribution: bjaspan commentedI'm looking at this today.
Comment #192
Crell CreditAttribution: Crell commented@catch: Which tests specifically fail, that don't fail before this patch? I was running installs periodically and they worked fine. chx, problem with the last sync, perhaps?
Comment #193
catchCrell: some test hunks don't apply.
I can't actually test tests because I can't install drupal with the patch applied ;)
Comment #194
Crell CreditAttribution: Crell commentedcatch: Which hunks? :-)
Comment #195
catchtracker.test
search.test
drupal_web_test_case.php
profile.test
xmlrpc.test
Comment #196
bjaspan CreditAttribution: bjaspan commentedSome things I noticed today in the SVN version:
- includes/registry.inc is missing
- Test fails: Select: Returned the correct number of rows at [dbtest.test:1004]
- Test fails: Query altering: Returned the correct number of rows at [dbtest.test:1177]
- QueryConditionInterface::condition() does not seem to describe DatabaseCondition::condition(), and the latter is not documented.
Comment #197
chx CreditAttribution: chx commentedLet's see this one.
grep ^=== pdo.patch |grep testonly shows dbtest. registry.inc is not removed this time.Edit: it's a royal pain in where the sun never shines, rolling a patch this size...
Comment #198
chx CreditAttribution: chx commentedRolling...
Comment #199
samirnassar CreditAttribution: samirnassar commentedPatch still applies. Some hunks have offsets:
Installation and use:
Drupal-PDO installs nicely.
Not being able to test content additions sucks, but on this local machine this feels nice.
Comment #200
samirnassar CreditAttribution: samirnassar commentedForgot to set CNW
Comment #201
recidive CreditAttribution: recidive commentedThe filter_formats.fid column doesn't exist.
These lines are adding 'filters' table columns while querying 'filter_formats':
It's on filter.module filter_formats() function.
Comment #202
samirnassar CreditAttribution: samirnassar commentedrecidive,
I am not sure what you are trying to tell me. As it is, the patch needs work since important functionality (creating content) stops working.there are two issues.
The missing column and whether the code needs work. I think keeping the code needs work flag is pretty accurate.
Comment #203
samirnassar CreditAttribution: samirnassar commentedAs a test I added the fid, module, and delta columns which Drupal complained about and I am now able to access the Input Filter admin page as well as add content.
Administering the Input Filters is broken. (Admittedly, this is a hack.)
Adding content works.
The names for the filters do not show up, and editing the filters doesn't work properly.
Something funky happening in the interaction between the filters and filter_formats tables.
On a whim I dropped the whole filters table. Only leaving the filter_formats table and Drupal didn't die on me.
So I am assuming that filter_formats is supposed to supercede filters with this patch.
I am also assuming that the move from one table to another is incomplete.
Comment #204
recidive CreditAttribution: recidive commentedSorry, I didn't want to change to CNR.
Try applying this patch after the one in #199.
If it works, can someone commit this to SVN and reroll the patch?
Comment #205
recidive CreditAttribution: recidive commentedPatch didn't get attached. Here it goes.
Comment #206
samirnassar CreditAttribution: samirnassar commentedDelivered.
This patch is the patch from 199 as well as recidive's patch from 205 included. Viva la CVS.
Comment #207
samirnassar CreditAttribution: samirnassar commentedI don't know why my patch is about 90KB smaller than the patch on 199.
With the combined patch of chx and recidive Drupal installs nicely. All the errors that popped up previously are gone.
Comment #208
keith.smith CreditAttribution: keith.smith commentedPutting this in my tracker so that I can fix up some comments; mostly double spaces between sentences, sentences without full stops, etc. Nothing major.
Comment #209
Crell CreditAttribution: Crell commentedThanks, guys! I've updated the svn repository to the latest Drupal HEAD and applied the patch from #205. Everything looks good now.
What we still need at the moment is PostgreSQL support to be tidied up. I am working on getting more PostgreSQL gurus involved to fix up the last bits of that, after which we can toss this Dries' way, I hope. (If you are a PostgreSQL guru, please speak up now!)
Comment #210
cburschkaYour patch is smaller because it's missing new files added. You need to do a few complex things to make CVS include new files in a patch, so it's a common mistake with these large patches. The same thing happened to me in the .schema -> .install patch, so I suspected it immediately when the size didn't match.
These are the files that must be re-added.
I can reroll, I think.
Comment #211
cburschkaThis one seems to be the right size. It's #206 with the added files, or rather #199 with the #205 change.
Getting it to include sites/all/modules/dbtest was a bit of a challenge.
Comment #212
catchno patch
Comment #213
cburschkaTrying again.
Comment #214
cburschkaAnd again.
Comment #215
catchWith this patch, simpletest users appear to be created in the main database instead of the prefixed one (or that's as far as I've got tracking down a lot of test failures).
Comment #216
Crell CreditAttribution: Crell commentedHm. That's odd. The prefixing logic is just about the only piece of the system that did NOT change. :-) I will have to ask chx about that, since he wrote that part of simpletest, AFAIK.
Comment #217
cburschkaEdit: Never mind, I didn't understand how SimpleTest prefixes tables.
Comment #218
cburschkaProblem looks simple. SimpleTest changes the global $db_prefix table during the test. The user is registered through a remote HTTP request. Since this remote request does not share a persistent scope with the original request, the $db_prefix is no longer changed when the user is registered.
This is a log file output I got from the relevant functions:
As you can see, the user is saved by remote HTTP request, losing the global scope, and resetting db_prefix.
To fix this, you need to somehow remember that you are in a test across multiple requests. You can either do this via a cookie or a persistent variable (since you're unlikely to be doing other things at the same time on a testing site).
Sorry if some of this is obvious or supposedly fixed; I'm new to SimpleTest and had to basically investigate from scratch.
Comment #219
Crell CreditAttribution: Crell commented@#218: cwgordon was working on that issue last night in Simpletest itself, without the database patch. So it sounds like that is a separate issue in Simpletest only. Which is fine by me, because then we don't have to deal with it in this patch. :-)
Comment #220
xaweryz CreditAttribution: xaweryz commentedsubscribing
Comment #221
catchThis patch keeps 'fields' used as a synonym for 'column' - there's an old issue against schema API to change 'field' to 'column' to avoid confusion with fields in core - I still think it's a valid issue: http://drupal.org/node/190162
Comment #222
Crell CreditAttribution: Crell commented@catch: Yes, I agree with changing the terminology, but after this patch lands. It's big enough that I don't want to add even more to it at this point if we can avoid it. :-)
Still need someone to confirm that postgres still works...
Comment #223
grub3 CreditAttribution: grub3 commentedVery interesting, thanks. I am a PostgreSQL fan.
In Drupal 6.2 I am amazed by some unsigned int together with SERIALs which are int4 (or 8) don't remember.
As a result the database has to cast during JOINs, which results in sequentiel access.
I can only recommand you to choose one single INT for all integer values.
This will boost JOINs and produce better results.
Don't think in term of database storage space ... it costs nothing nowadays.
Think in term of queries.
The database will always adapt better to a situation where its own types are used.
SQL92 is there, so there is no need to create custom types IMHO.
Will test anyway. Great project.
I will log queries and read query plans to tell you if PostgreSQL
will cast / sequential access or not.
Kind regards, JMP
Comment #224
alex_b CreditAttribution: alex_b commentedSubscribing.
Comment #225
bjaspan CreditAttribution: bjaspan commented@JMP: Your comment in #223 sounds like an important point but is not directly tied to this issue. Please create a separate issue here at d.o regarding the performance penalty of inconsistent types for pgsql joins.
Comment #226
Crell CreditAttribution: Crell commentedThere's actually already an issue for that, and I think it's been fixed in D7 at least. I don't recall about D6. (Block module in particular was joining badly, which died in Postgres 8.3.) That is definitely a separate issue from this thread, though.
Comment #227
mfer CreditAttribution: mfer commentedThe patch no longer applies for me.
Comment #228
sammys CreditAttribution: sammys commentedJust a heads up on PostgreSQL installation.
I've just debugged the install on PostgreSQL and passed on my findings to Crell. Turns out the install code is passing $args == array(1) with the CREATE TABLE statement when creating the variable table. This in turn breaks the PostgreSQL PDO driver for some reason. Removing the array(true) from the update_sql() function results in the table creation being successful.
We appear to have a transaction error following on after this so some more to do still.
Comment #229
sammys CreditAttribution: sammys commentedFollowing on from #138 above where it is stated that the following sequence is the way to get a merge to work in a DBMS without the MERGE query:
While this works in code it seriously breaks transactions. The insert failure will abort any surrounding transaction (i.e any transaction started before the call to db_merge()). So this method of doing can not be an option for us.
Provided db_merge() isn't used in heavy write scenarios it's safe to implement it as:
As annoying as this method is, it works and will get us moving forward with db_merge() not breaking transactions.
PostgreSQL can avoid the transaction breakage and allow us to use the insert()-or-update() method with savepoints. This will only work with versions >= 8.0. I've tested savepoints and they will allow the following sequence of queries:
What will be the minimum postgresql version for D7?
Savepoint statements can't be run unless you're in a transaction already:
http://www.postgresql.org/docs/8.0/static/sql-savepoint.html
Since I haven't looked into the code of the whizzbang new DB layer enough... Will we have an insideTransaction() function available to us? PDO may not implement one but we sure can put a static var in to track this (though I imagine this should be possible to override for some silly DBMSs).
Comment #230
catch@sammys: there's an issue here to up the minimum postgresql version, trivial patch but three months stale.
edit: forgot the actual link #248205: PostgreSQL surge #7: Require PostgreSQL 8.3
Comment #231
Crell CreditAttribution: Crell commentedI have no idea what the version distribution is for Postgres, but given that Drupal 7 is already dropping support for PHP < 5.2 and MySQL < 5, I wouldn't have an objection to dropping support for Postgres < 8. Let's do all of our version cleanup in one round. :-)
PDO itself doesn't support savepoints or nested transactions as far as I know. However, once we're in MergeQuery_pgsql::execute(), we can absolutely do Postgres specific stuff if needed. So we can bypass the PDO transaction handling entirely and issue BEGIN and SAVEPOINT commands if it makes it easier.
The main place merge queries are used, I believe, is variable_set() and cache_set(). You can grep the svn checkout for "db_merge(" to see if there are any others, but it's fairly limited. So maybe we can get away with a COUNT(*), but I'm not certain.
Comment #232
recidive CreditAttribution: recidive commented@Crell, can you clarify why this patch breaks more than half of tests?
It would help testers if this patch gets re-rolled more often.
Changing to CNW because it doesn't apply anymore.
Comment #233
Crell CreditAttribution: Crell commentedGiven the size, length, and complexity of this patch you're much better off pulling from the svn repository. That's updated much more often and I try to resync with HEAD after every major change. Rerolling an 8 file 300KB+ patch every few days is really not that effective a use of time. :-) (Especially when this issue is already well past the 200 comment mark.)
Comment #234
recidive CreditAttribution: recidive commentedI already have a checkout from SVN and am running tests on it. Just so you get a sense:
Block module tests:
Without the patch:
58 passes, 0 fails, 0 exceptions
With the patch:
38 passes, 37 fails, 0 exceptions
How can I help with code?
Can you give me commit access to SVN so I can help with cosmetic changes?
Posting patches against SVN here can cause confusion, i.e. people would try to apply the patch against their clean HEAD checkout.
So what is the process? I'm willing to help.
Comment #235
Crell CreditAttribution: Crell commentedOh blargh. :-)
I suspect that such issues are caused by complex queries that don't work with the temporary BC layer we're using. The best thing to do there is track down the breaking query and update it to the new syntax. (See dbtest.test for extensive examples.) I suspect that will fix it, although those tests used to work. :-/
For svn commit access, poke chx. He should be able to set you up with an account.
Thanks for the help!
Comment #236
Crell CreditAttribution: Crell commentedPS: You can also corner me in #Drupal if you have further questions. I'm in there most nights US time these days, especially later at night.
Comment #237
recidive CreditAttribution: recidive commentedI tracked down the tests problems and discovered it is missing the "User-Agent with db prefix" hack originally set on
drupal_set_active(), I added this code toDatabase::openConnection()asDatabase::setActiveConnection()is only called when switching databases, not when the first database connection happens (not sure if it's the place though).All block module tests failures are gone. Patch against SVN code attached.
This patch is against PDO SVN code. Doesn't try to apply/test this on a clean Drupal HEAD checkout.
Edit by ChX: I gave recidive SVN access and he checked this and a bit more in.
Comment #238
Crell CreditAttribution: Crell commentedThanks, recidive!
Comment #239
cburschkaQuestion: Since the eventual outcome of this work will be a patch against the CVS repository, I suppose that the SVN repository must be kept up to date with changes to CVS? session.inc is put in a conflicted state by a change earlier today. This patch (for SVN) merges in revision 1.49 of session.inc. There are other merges, but this is the only conflicting one.
Comment #240
Crell CreditAttribution: Crell commentedYes, the svn repository needs to be kept in sync. I CVS UP the svn repository every few days at this point to sort out breakage, which is usually caused by changes to simpletest. :-) I'm not sure if separate patches would work properly, to be honest. I'll give it a try later today and get it up to date one way or another. Thanks!
Comment #241
Crell CreditAttribution: Crell commentedDocumenting this here for lack of anywhere better:
I have just learned experimentally that MySQL and Postgres are diametrically opposite when it comes to ordering.
Specifically, if you ORDER BY a field that has some rows that are NULL...
MySQL will order the rows: NULL, 1, 2, 3, 4, 5
Postgres will order the rows: 1, 2, 3, 4, 5, NULL
I have no idea which is correct according to the SQL spec, or if there is a correct according to the SQL spec. But this is why true database portability is never going to happen, ever. If even the open source databases can't get their act together and agree on something as small as that, the SQL business as a whole is basically doomed to never, ever have a real standard that anyone can actually use. And that's before you even get into questions of syntax or field handling that have been driving me batty for months.
It also means I have to rewrite a unit test to not rely on the order, because guess what, the order is database-dependent. Databases suck.
</late-night-rant>Comment #242
Crell CreditAttribution: Crell commentedIn other news, there has been much progress on the driver. Arancaytar, your patch for session.inc worked a lot better than trying to svn update that file, so thank you. :-)
1) We're now resynced with HEAD. I think there's actually a bug in the installer (unrelated to this patch) right now that should be fixed by tomorrow, when I'll resync again. :-)
2) I also split the tests up into more classes to avoid PHP timeout issues. Yeah, it's kinda sloppy but that's a limitation of the testing framework. I am not going to fix that here.
3) I implemented a useDefaults() method for insert queries. Simpletest uses this, but I'd never heard of it before. :-) It lets you specify fields that should get whatever the schema-defined default values are, which is apparently a rarely-used SQL feature.
4) Postgres is now about 90% working. The outstanding issues are:
- Postgres can't run multiple unit tests at once, as the $vid created in the default install profile returns NULL
the second time. I do not know why.
- Postgres merge queries are not yet functional. This needs to be written in such a way as to not use an exception. I am consulting with Postgres gurus on this front. :-)
- expressions have not yet been implemented in Postgres update statements. Barry, is this something you can look into?
We're very close, folks! MySQL passes all database-specific unit tests. Postgres passes *almost* all, except for merge queries and update expressions.
If you can, please grab a copy of the code from svn and start running tests on other modules, comparing against a vanilla copy of HEAD. If anything is broken by this patch, post the full details here so we can fix it. Remember we need someone to do MySQL *and* Postgres.
I will be posting a new patch as soon as both drivers are passing all database-related tests.
Comment #243
Anonymous (not verified) CreditAttribution: Anonymous commentedRe: #241
Postgres supports a [NULLS (LAST | FIRST)] option on the ORDER BY clause.
http://www.postgresql.org/docs/current/static/sql-select.html
MySql lacks this but an interesting conversation is at http://lists.mysql.com/internals/6868 where I learn NULLS sort first beginning 4.0.2.
Comment #244
Frando CreditAttribution: Frando commentedSo, I did a round of testing today. MySQL 5.0.51a, PHP 5.2.4, Linux.
Here are the results:
HEAD without the patch: 4775 passes, 24 fails, 0 exceptions
PDO patch SVN checkout: The tests did not complete. After 3708 passes, 38 fails, 0 exceptions simpletest stops with an uncaught exception:
And here is a list of tests that pass in HEAD but fail in the PDO SVN checkout:
Comment - comment functionality: 16 fails
Comment posted. Other comment.test 64 postComment
Comment id found. Other comment.test 64 postComment
Reply found. Other drupal_web_test_case.php 274 testCommentInterface
Found the requested form at Other comment.test 277 drupalPost
Found the Preview button Other comment.test 277 drupalPost
Failed to set field subject to simpletest_taJS Other comment.test 277 drupalPost
Failed to set field comment to simpletest_TkPr Other comment.test 277 drupalPost
Found the requested form at Other comment.test 279 drupalPost
Found the Save button Other comment.test 279 drupalPost
Failed to set field subject to simpletest_taJS Other comment.test 279 drupalPost
Failed to set field comment to simpletest_TkPr Other comment.test 279 drupalPost
Comment posted. Other comment.test 69 postComment
Comment id found. Other comment.test 69 postComment
Modified reply found. Other drupal_web_test_case.php 274 testCommentInterface
Link to the 2 comments exist. Other drupal_web_test_case.php 274 testCommentInterface
Page two exists. %s Other drupal_web_test_case.php 274 testCommentInterface
DBlog - 1 fail
DBLog contains 2 records for simpletest_vNsv that now have uid = 0 Other dblog.test 165 doUser
The other tests that fail do fail on HEAD as well.
Comment #245
Frando CreditAttribution: Frando commentedAnd now results for Postgres 8.3.3. First of all, in current HEAD simpletests on Postgres for me simply stop after 6 out of 70 tests (at Categorize feed item functionality.) without any error message, the batch just doesn't continue. I will file a seperate bug report for this.
And on install in current HEAD I get several error messages, whereas in the PDO SVN checkout installation goes smooth without any errors! Nice, eh? ;)
In the PDO SVN checkout simpletests go better than in current HEAD, I get 1010 passes, 407 fails, 12 exceptions until it stops as well. Detailed results are here
Comment #246
cburschkaI'm a noob with prepared statements and PDO, but is that error supposed to indicate that
UPDATE {search_index} SET score = score + ? WHERE word = ? AND sid = '?' AND type = ?contains a different number of placeholders thanArray ( [0] => 1 [1] => ipsum [2] => 1 [3] => _test_ )contains values?Comment #247
hass CreditAttribution: hass commentedIn the test results I saw a valid email address
simpletest@test.com. We should usesimpletest@example.comhere.Comment #248
cburschkaIrrelevant to this issue though. I've made a separate patch:
#285184: contact.test uses bad email domain test.com
Comment #249
siromega CreditAttribution: siromega commentedIs anyone working on an Oracle driver? I've got 4.7.2 on Oracle 10g and would eventually like to update to a more modern version of drupal.
Re: #241
According to SQL2003, null order is explicitly left to the vendor to choose how they want to implement it....
"If <null ordering> is not specified, then an implementation-defined is implicit. The implementation-defined default for <null ordering> shall not depend on the context outside of <sort specification list>."
So don't point your finger exclusively at the DB vendors, since the standards body also failed to define the standard. At least most DBs support nulls first|last SQL syntax (which is part of the standard).
Comment #250
Crell CreditAttribution: Crell commentedThis issue against SimpleTest is critical for a reason: #242069: Simpletest should include exception data in reporting. It breaks any tests that have a database failure in a catastrophic way, as seen here.
The actual query looks like an issue where core is passing in extra, unnecessary arguments. That didn't break in the old API, but PDO is pickier. I'll convert that query to a proper dynamic query tonight. Frando, do you think you can help localize where the issue is on the extra failing tests?
I had the Postgres almost working this weekend, but then it imploded. :-( I'll report back as soon as that's worked out.
Re NULLs, Bah and double bah! Like I said, SQL is broken by design. For the time being I think I'll leave it undefined, but I am open to forcing it to NULL first, at least in built queries, if there is a consensus to do so. Probably best to wait until after this patch for that.
Re Oracle, no, not for this DB API, yet. However, this system is designed to allow drop-in drivers, so I am looking forward to someone writing an Oracle driver in contrib after this lands.
Comment #251
chx CreditAttribution: chx commentedComment #252
chx CreditAttribution: chx commentedThis is all Crell's work, I am just rolling here.
Comment #253
Crell CreditAttribution: Crell commentedThanks, chx!
OK, for those playing our home game, the svn repo is in sync with HEAD as of right now, and the patch should work against current HEAD. All database unit tests pass in both MySQL and Postgres. w00t!
This also fixes a bug in simpletest, where the schema is not flushed between test cases. That was causing all sorts of excitement for PostgreSQL, which depends on the schema.
Unless there are any major regressions in other unit tests, I consider this patch commitable. (We should leave out the dbtest module, as that can be maintained in contrib until simpletest is able to handle virtual modules.) There is still a lot of follow-on work to do, and the "convert the rest of core" tasks, but those can all be done after this patch is in so that more people can get involved in more bite-sized patches As God Intended(tm). In particular:
- PostgreSQL merge queries are very non-optimal, as they involve multiple queries. David Strauss suggested writing a Postgres SQL function that we call that will take care of everything in one call. That should work fine, but I leave it to someone who actually knows Postgres to do so. Until then, the generic version works.
- The reference to dev_query() is gone. It will come back in a subsequent patch, as soon as we decide how we want to handle the new format of queries. (The query string doesn't contain values; those come separately as an array, and in Postgres are bound before we even get to the query function.) We will need to fix this, but it's not critical for commit. I'm happy to let the devel maintainers decide how they want to do it. For now, though, this is cleaner and shows the actual logic of the query system itself.
- I've tried to be as pedantic as I can about coding style, but I probably missed a space somewhere. Once it's in, we can run coder module on everything.
Going once, going twice...?
Comment #254
catchCall to undefined function db_decode_blob() in cache.inc - looks like only one of them gets removed in the patch.
I hacked it out and I'm running tests again now. Quick re-roll?
edit: also getting DBLog functionality: 308 passes, 1 fail, 0 exceptions
Module list functionality: 53 passes, 4 fails, 0 exceptions
Database placeholders: 108 passes, 4 fails, 0 exceptions
Fails:
edit again - this was with #252, trying with #251 now.
Comment #255
catchWell. #251 seems to be the better patch. I only get the one dblog failure and 4 system failures with it, and no undefined function in cache.inc.
Which one are we supposed to review?
Comment #256
cburschka#252 is about 80 kB smaller than #251. Sure that all files were diffed properly?
Edit: Looks like #252 does not delete certain files that #251 deletes.
Comment #257
Crell CreditAttribution: Crell commentedThe second patch. The first one accidentally removed a bunch of extra files it shouldn't have. Please ignore that one. :-) #252 is the real patch.
@catch: Can you localize what queries are causing those failures? Most of the tests are functional which makes ithem hard to localize to a particular function or query, which we need to do. (I suspect it's more cases of queries that just need to be updated as they're not compatible with the BC layer.)
(I don't think we should worry about database.test failures, as those tests are against the old DB API anyway so I don't expect them to work.)
Comment #258
catch@Crell, in that case #252 still needs a re-roll for the cache.inc fatal error - it's just removing that one line.
I manually confirmed that aggregator installs properly, got a feed into it etc., so these look like test framework issues in system.test at least. I've already cleared my HEAD out but will see about a bit closer look later on.
Comment #259
cwgordon7 CreditAttribution: cwgordon7 commentedconst ARGUMENT_BOUND seems to never be used.
Comment #260
catchTracked down two failures:
system.test calls http://api.drupal.org/api/function/simpletest_get_like_tables/7
Line 501 of simpletest.module
post a reply to a comment generates:
SELECT MAX(thread) FROM {comments} WHERE thread LIKE '?.%%' AND nid = ? - Array ( [0] => 01 [1] => 1 ) SQLSTATE[HY093]: Invalid parameter number: number of bound variables does not match number of tokens in /home/catch/www/drupal7/includes/database.inc on line 272Line 696 of comment.module
Also line 214 of dblog.test
db_query('SELECT wid FROM {watchdog} WHERE uid = 0 AND wid IN (%s)', implode(', ', $ids));I think that's all the simpletest failures (the old db placeholders tests need to be removed or rewritten since we'll no longer use those placeholders).
Comment #261
shunting CreditAttribution: shunting commentedSubscribing.
Comment #262
cwgordon7 CreditAttribution: cwgordon7 commented..but then it progresses to put some pgsql-specific code in _db_query_process_args(), manually typecasting integers and floats to integers and floats, which is only necessary for pgsql, according to the inline comment. Would there be a way to move this to a pgsql-specific location and avoid the regex on other database types?
Comment #263
Crell CreditAttribution: Crell commentedThe issues mentioned in 258, 259, and 260 have been fixed. The old database.test file has been removed as no longer applicable. There was some discussion in IRC if simpletest_get_like_tables() is vestigial or not. It's also a very very strange edge case that may not even be kept, so that may still be broken. It's only used in two very strange places, though, so after talking to the simpletest folks I'm going to leave it be for now.
_db_query_process_args() is part of the temporary backward compatibility layer until we get the rest of our queries upgraded to the newer, stricter format. I've moved it to the "legacy" @group to make that clearer. It will be removed later.
Comment #264
chx CreditAttribution: chx commentedHere comes the patch. bzr rocks in rolling patches like this.
Comment #265
catchAll simpletest errors fixed (only testing on MySQL) - except for module_list and I agree simpletest_get_like_tables() is just strange. Reading through the code now.
Comment #266
nielsvm CreditAttribution: nielsvm commentedSubscribing
Comment #267
slantview CreditAttribution: slantview commentedsubscribe
Comment #268
AmrMostafa CreditAttribution: AmrMostafa commentedsubscribing
Comment #269
Crell CreditAttribution: Crell commentedAnyone? An actual review? An RTBC maybe? Beuler?
Comment #270
agentrickardPatched version works as advertised -- nothing breaks; tests pass. I am still trying to walk through the code and comments to figure out exactly how.
Some initial notes:
And I'm only about 15% through the database.inc file.
My opinion -- not being familiar with OO code style -- is that this may be RTBC so we can really start testing, but we may need to be able to roll back the patch.
Comment #271
Crell CreditAttribution: Crell commentedThanks, Ken!
- "already_prepared" is actually vestigial. runQuery() is now smart enough to tell if it is called with a query string or a prepared statement, so I've removed that default value. Similarly, runBoundQuery() is no longer actually used (runQuery() handles both cases) so I have removed it and beefed up runQuery()'s documentation.
- I've added extensive documentation to the docblock at the top of the file on how prepared statement placeholders work. I suspect it will later get copied verbatim to the handbook. :-)
- makeSequenceName() now has a docblock.
- DatabaseStatement documentation clarified.
- Fixed the docblock for DatabaseConnection::defaultOptions() to correctly describe the various return types.
- Database::openConnection() params defined.
I do not believe we need to override the static cache of prepared statements. It doesn't seem to cause an issue for simpletest, which is where that is most likely to break. If a use case comes up later we can add it then in a way that makes sense for that use case, but for now let's keep it simple.
I'm not sure why we'd need to roll back this patch, as it is already more heavily tested and unit tested than any major overhaul patch to date. There are surely bugs we'll find only after the patch lands (there always are), but I cannot think of any that would force an entire roll back.
As the above changes are 95% documentation I've committed them to the svn repository and resynced with HEAD. I'll bug chx to reroll the patch at his leisure. :-)
Comment #272
hass CreditAttribution: hass commentedI'm not yet very familiar with the PDO changes... only this sentence wonders me a little bit. I know that we often have issues in ColdFusion with prepared statements and this makes us often to hard restart the ColdFusion services at all as prepared statements cannot be cleared in CF by hand. This is unbelievable bad and I'm not sure how to clear PHP-PDO cache, but I hope we could do better in Drupal then Adobe does in CF.
We changed often in such situations from
SELECT * ...to naming the columns or simply added a blank to a as only this makes CF to recompile the statement :-(. Nevertheless this solved the issues in CF we are restarting the services to not add stupid blanks to SQL statements. But this should all be easier... There are many statements using * in Drupal and if the DB layout changes you need to clear/overwrite the prepared statements cache or the new columns are invisible until the cache is cleared.Comment #273
catchI've looked through about 70% of this patch now, looks like Ken has already picked up most of my initial concerns.
Whilst I think the db_insert() etc. syntax will probably take a little getting used to, looking at the converted queries it's going to be much more readable - since the fields and values sit right next to each other in the array - much easier to see which maps to which when there's lots of variables to insert.
Moving $db_url to the $databases array is also a nice change, and likely to reduce mess ups when new users have to manually edit it.
There's commented stuff in install.php- calls to db_set_active and install_already_done - these either need deleting, or @TODOs or something.
Otherwise this looks RTBC to me - the tests and phpdoc are verbose, I'm not really qualified to comment on the actual PDO implementation and abstraction layer, but I think we're past that point now since that's been looked at in depth by people who are.
Comment #274
Crell CreditAttribution: Crell commentedI cannot speak for ColdFusion, but recall that in PHP nothing is maintained between page requests. The static cache of prepared statement objects lasts only as long as the page request and then dies like any other static variable. If the schema changes, the next page request will recompile the queries anyway. (Besides, you shouldn't be using SELECT * anyway.)
Also, on at least PDO/MySQL and I believe any PDO implementation a prepared statement is keyed internally by the database on the exact text of the query. Even whitespace differences will indicate a new query. We therefore cache the same way, so we can re-use the object. That means the only time a query will be reused is if it really is the exact same query, down to the same placeholder names and same whitespace formatting. In that case we do want to reuse the same prepared statement object, as that is why we're saving the object in the first place; it saves recompiling the query a second time. In practice, that will happen most often for us in cases where the same query line gets called multiple times, such as the 100+ calls to do a path alias lookup or when loading several nodes on the same page. As those are the same query, reusing the query object is exactly what we want to do.
I removed the commented out code from install.php. I think that was just leftover from earlier work. Since we've been able to install with this patch several times and the unit tests pass, I'm assuming that code is not needed anymore. :-)
I'll ask chx to roll another patch. At that point, anyone up for marking RTBC to get Dries' attention? :-)
Comment #275
chx CreditAttribution: chx commentedComment #276
hass CreditAttribution: hass commented@Crell: This gives me an idea why PDO is not faster then the older drivers :-). Bad thing... prepared statements should be cached over page requests as the time consuming process of binding data types and validating them to DB fields gives "often" only a win over multiple page requests. Thank you for the explanation.
Comment #277
Crell CreditAttribution: Crell commentedUnfortunately that is not really possible in PHP, as it is a stateless, shared-nothing architecture. We get the security benefits of prepared statements, but not a cache-forever behavior from a database connection.
Comment #278
mikey_p CreditAttribution: mikey_p commented#275 gave me the following:
An error occurred. /dbtng/batch?id=2&op=do <br /> <b>Fatal error</b>: Uncaught exception 'PDOException' with message 'SELECT watchdog.wid AS watchdog_wid FROM {watchdog} AS watchdog WHERE (uid = :db_condition_placeholder_584) AND (wid IN ()) - Array ( [:db_condition_placeholder_584] => 0 ) SQLSTATE[42000]: Syntax error or access violation: 1064 You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '))' at line 4' in /home/mike/public/dbtng/includes/database.inc:414 Stack trace: #0 /home/mike/public/dbtng/includes/database.inc(2317): DatabaseConnection->runQuery('SELECT watchdog...', Array, Array) #1 /home/mike/public/dbtng/modules/dblog/dblog.test(218): SelectQuery->execute() #2 /home/mike/public/dbtng/modules/dblog/dblog.test(165): DBLogTestCase->doUser() #3 /home/mike/public/dbtng/modules/dblog/dblog.test(39): DBLogTestCase->verifyEvents() #4 /home/mike/public/dbtng/modules/simpletest/drupal_web_test_case.php(274): DBLogTestCase->testDBLog() #5 /home/mike/public/dbtng/modules/simpletest/s in <b>/home/mike/public/dbtng/includes/database.inc</b> on line <b>414</b><br />Crell fixed this in r642. Any chance you could re roll the patch?
Comment #279
Crell CreditAttribution: Crell commentedJust a note, the issue in #278 is a bug in dblog.test, not with the database API itself.
Comment #280
catchsystem and node module have hunk failures as of this evening, needs a re-roll.
Comment #281
catchComment #282
chx CreditAttribution: chx commentedComment #283
catchNew one applies cleanly and passes all non-failing tests on MySQL. edit: except the four fails on system.module, which are a simpletest oddity, and ought to be handled in a different issue.
Comment #284
Crell CreditAttribution: Crell commentedSo who's going to have the guts to mark this RTBC so we can move on to the next step? :-)
Comment #285
catchIt seems to be quite a while since we had a positive review on postgres, IMO there should be one more on that in case of any regressions since the last one.
Comment #286
catchI installed postgres, installed drupal, tried to run tests - and they don't work on a clean install of HEAD with postgres, so pretty useless for comparison.
However, a bit of manual clicking, and I get Call to undefined function module_load_all_includes() in bootstrap.inc - this is in drupal_get_schema() - which is called from InsertQuery_pgsql { in database.pgsql.inc
Comment #287
chx CreditAttribution: chx commentedWe now defer cache_set until a full bootstrap. merge will need documentation: do not fire during hook_boot, not guaranteed to work because it uses schema.
Comment #288
catchWith this new patch, install works fine on postgres. I got an error in search.test - but as noted, I can't even get to search.test in postgres with HEAD since simpletest is throwing exceptions and timing out etc.
So, any remaining test failures on postgres I think we should fix in a follow-up patch - since this is already a massive improvement on the status quo anyway.
Based on this having extensive review so far by numerous people and no caveats for quite some time - I'm marking RTBC.
Comment #289
Crell CreditAttribution: Crell commentedWe may be able to play some games with the schema and autoloading very early on to clean that up, but as it affects only an edge case in postgres I am not interested in holding up the whole patch for it. That will come after this lands and the boostrap refactoring that chx and moshe are working on.
(This patch already makes postgres work better than it ever has before, and yet no one actually uses it except for the MySQL people that are writing the postgres driver. I will *not* be held hostage even further by a database no one uses.)
Comment #290
catchI think Crell cross-posted.
Comment #291
Crell CreditAttribution: Crell commentedOopsies, I did! Thanks catch!
Comment #292
pwolanin CreditAttribution: pwolanin commentedminor note - the code example in the doxygen at the top of database.inc has been wrong since 4.7.x - there is no n.body field. see: http://drupal.org/node/293558
https://4si.devguard.com/svn/public/pdo/includes/database.inc
Comment #293
yettyn CreditAttribution: yettyn commentedPlease re-roll the patch as it's broken at about 8-9 places now.
Comment #294
yettyn CreditAttribution: yettyn commentedI was able to apply the patch after some manual adjustments and it applied cleanly. But then I got an error about the Class PDO not available and I figured out it was because my php 5.2.6 wasn't compiled with it, so recompiled and got passed that.
Now though I get "Fatal error: Interface 'Countable' not found in /var/www/www.astro.nu/htdocs/includes/database.inc on line 2663" and I guess it's because something else not being compiled into php, but what? Yes SPL, I figured that out as well. Previously I found out that D7 now also demands php to be compiled with json support and maybe I have missed something but I haven't been able to see these new requirements listed anywhere? I just mean, it will probably save a lot of support fuzz if it was as it probably isn't uncommon that php is compiled w/o these extensions. Just a though.
Comment #295
Crell CreditAttribution: Crell commentedI recommend just checking out from the svn repository mentioned at the top of the thread. I really don't want to sit here and chase head on a patch this site without getting any committer feedback. That's a waste of my time and chx's. :-)
PDO and SPL are part of a default compile of PHP as it comes from php.net. Some distributions reconfigure PHP so that you can pull them down piecemeal, but at that point you should anyway in order to have a functional PHP 5 environment. While it is possible for web hosts to disable those, it would be moronic for them to do so. They can disable PCRE, too, but that's assumed as a given part of a PHP install as well.
I suppose potentially we can add some extension_loaded() checks to system_requirements(), but that's a task for another patch. (I'm saying that a lot at this point, I know.)
Comment #296
chx CreditAttribution: chx commentedI CVS upped hoping to attract some comitter attention :)
Comment #297
yettyn CreditAttribution: yettyn commentedOk some feedback,
latest patch apply cleanly and a fresh install with a remote (not localhost) mysql 5.0.60 db went fine. Only problem I have here is that D7 still cannot send mail due to my mailserver also is located on a separate host - but that's no blaim on this patch I think.
I will test furhter and will record back if I notice anything but as before this patch it wasn't even possibly to install D7 I would say it's RTBC - at least that would invite more ppl to start testing D7
If it hadn't been for this patch I probably had dropped it, but luckily I found it on the top of the issue quee ;-)
Now I will try t build a site on D7 which doesn't need so much extra, making it an excellent candidate.
Comment #298
Anonymous (not verified) CreditAttribution: Anonymous commentedIt isn't the default, you have to specify it in the configure command if you want it and you have to have the DB supplied PDO objects handy; else you don't get it. It may be default using someone's version of a package manager package ini file; but if you build it straight from the configure script it isn't the default.
Comment #299
bjaspan CreditAttribution: bjaspan commentedThis patch has come a long way! Good work, everyone.
I performed a static (human read-only) code review of the latest SVN code. Most of my comments are minor tweaks and some are just questions. The really important ones are marked HIGH. Since there are a couple HIGH (including at least one security vulnerability), I've marked it CNW again (sorry).
If a pgsql (or mysql) test run is needed, let me know.
# database.inc
## Opening docs
* Extra argument to db_insert() in example:
db_insert('my_table', 'node')->fields($fields)->execute();
## class DatabaseConnection
* makeSequenceName(): Why "@param unknown_type $field"?
* public function setLastInsertInfo() is obsolete.
* query() is public and calls runQuery() which is protected. InsertQuery (and others) call runQuery() directly, which means query() cannot ever really perform any additional functionality. So why not just rename runQuery() to query() and make it public?
* mapConditionOperator(): Why must $operator be case-sensitive? SQL is not.
## class Database
* parseConnectionInfo(): Is it possible that $databases[$index][$target]
will not be cleanly 0-indexed? If so, we should use
$databaseInfo[$index][$target] = $databaseInfo[$index][$target][array_rand($databaseInfo[$index][$target])];
* openConnection(): "// TODO. error handling."
## class InsertQuery
* protected $delay is not used in this class, should be removed
* useDefaults(): What is the difference between specifying a column to useDefaults() and not specifying it at all? Perhaps the doc should say so.
## class MergeQuery
* I continue to object to the non-orthogonal treatment of update() and updateExcept(). What is the compelling use case for update() to take a list of values separate from those given to fields()? I suspect this interface was chosen because MySQL's ON DUPLICATE clause allows it, not necessarily because it is worth the confusion. :-)
## class SelectQuery
* HIGH: addField(): Schema API functions accept ($table, $field), this function accepts ($field, $table). This is HIGH because one we release this API, we'll be stuck with the order forever.
## Schema API functions
* HIGH: db_type_placeholder(): Using %s without quotes for numerics allows SQL injection attacks. This bug has been fixed in HEAD and 6.x, so this patch should not re-introduce it. I *thought* a unit test for this fix was committed.
# database.pgsql.inc
## class DatabaseConnection_pgsql
* Remove commented-out, obsolete lastInsert code.
# database.mysql.inc
## class DatabaseConnection_mysql
* public static $rand and $timestamp are not used
## class MergeQuery_mysql
* Remove commented-out call to drupal_alter().
# Post-PDO SVN commits to CVS database files
HIGH: Some changes to database.inc and database.*.inc have been committed since the PDO SVN tree was created. Since these changes are to files that have been completely written, the periodic cvs updates probably missed these changes. I suspect there are really only one or two such changes that need to be integrated.
I generated this list with:
cvs log -d '02/20/2008
* database.inc: 1.93, 1.94, 1.95, 1.95
* database.mysql.inc: 1.91
* database.mysqli.inc: 1.56, 1.57
* database.pgsql.inc: 1.68.2.2, 1.70, 1.71
Comment #300
fgmThe 296 patch rolled by chx applies cleanly to a fresh checkout of head this morning, with just some offset.
I don't know if this is related, thought, but a few problems do happen:
- admin/reports/updates returns a WSOD.
- admin/build/modules returns twice: "Undefined index: #value in D:\src\drupal\head\modules\system\system.admin.inc on line 782"
I think I've tested all pages in a default install (only a few posts, though), and these are the only warnings I got.
MySQL: 5.0.51a-community-nt,
InnoDB engine, tables are created with utf8_general_ci although this was not the default for the DB.
Comment #301
Crell CreditAttribution: Crell commentedThanks, Barry.
Fixed.
Because my IDE like every other PHP IDE out there uses PHPDoc, not Doxygen (like we should be doing), and so includes a placeholder for the argument type. Fixed.
Removed.
But PHP is for string data, and we're doing the lookup matching in PHP space, not SQL space. I opted to not do case folding here mainly for performance reasons (and the assumption that developers can and should be using capitals for SQL code anyway), but I can add some folding in if the committers (Dries) prefer.
## class Database
That's only possible if someone is doing something totally wrong with the $databases array. I file this under the "don't babysit broken code" category. (I've been told that the mt_rand() method is slightly faster than array_rand(), which is why I went that route, but I have not benchmarked it myself.)
I think kicking off to the installer is the proper error handling there, so I've documented it as such and removed the TODO.
## class InsertQuery
Wow. OK, I don't know when that went missing because there is supposed to be a method to set delay true or false. That's then used by concrete subclasses or not as appropriate. I have restored the method instead. Good catch!
To be perfectly honest, I'm not sure. :-) I'd never even seen this syntax until I was converting simpletest to the new API. As near as I can tell it's only useful when you want to insert an "all default" row, so you would have to otherwise specify "VALUES ()", which is a parse error. I've updated the docblock to say something to that effect.
Incrementer queries. From statistics module:
OK, that's expression() not update, but having one and not the other makes absolutely zero sense. :-) And actually if I read the wiki page above properly such behavior is supported (albeit in a totally different syntax) by the SQL2003 standard merge query.
Stuck with an API forever? Please, this is Drupal. :-) I'd originally wanted to make the table optional, which would mandate it coming second, but in the end that wasn't really possible. I hadn't considered the schema parallel. Since the table is always required, I've reversed the param order to match schema as well as the order you'd write the field in straight SQL.
## Schema API functions
Oh is that what that unit test was for. :-) It was removed as no longer having any relation to the new API, and db_type_placeholder() is vestigial and only there as part of the BC layer. I've forward ported the portions of the %n patch that are relevant anyway.
# database.pgsql.inc
Removed.
# database.mysql.inc
## class DatabaseConnection_mysql
* public static $rand and $timestamp are not used
Those were from earlier experimentation that I pushed off until later. Removed.
## class MergeQuery_mysql
Gone.
I don't think there are any other recent DB patches of relevance. Dries has kept most of them at bay to make life easier on this patch, so I think we're good.
@fgm: I cannot reproduce the WSOD. The notices look like they have nothing to do with the database, so I am skipping those to avoid conflict with other patches in case they get fixed elsewhere.
I've committed all of the above, and asked chx to roll a new patch.
And here we are on comment #301. *sigh*
Comment #302
chx CreditAttribution: chx commentedHere is the patch.
Comment #303
catchNotices are from a commit yesterday, nothing to do with this patch.
message_id - test_id prevented 302 from running simpletests (it's a one line fix though), however after getting them running, there's fails in nearly every simpletest, so looks like a big re-roll to do.
Comment #304
chx CreditAttribution: chx commentedComment #305
Crell CreditAttribution: Crell commentedThanks chx!
OK, the latest patch should be up to date against the latest HEAD. Under MySQL, test passage is 100%. (w00t!) Under Postgres, it's somewhere around 95%. There's a few things that don't work, but I suspect they're existing Postgres bugs (such as #296624: do_search() fails hard on Postgres). Given that before this patch Postgres doesn't work with Simpletest at all as far as I'm aware, that's still a huge improvement. Fixing up the last bits of Postgres support will have to happen during the query conversion process, which can be a team effort. :-)
Would someone care to do the honors and send this to Dries before HEAD moves again?
Comment #306
NaheemSays CreditAttribution: NaheemSays commentedJust tested from a fresh checkout
1. Patch applied cleanly.
2. Installed on WampServer in windows Vista with Mysql 5.0.45, php 5.26
3. Clicked around, created content taxonomy etc. things seemed to work
4. Ran tests.
4a with max execution of 30 seconds, the tests timed out after just aggregator tests. (My first time with running tests so I will assume we need a higher limit).
4b reset to max execution a higher limit (3000), and the tests are still running - currently at 30%. All passes so far except for:
Blog API functionality: 35 passes, 10 fails, 1 exception
I never ran the simpletest before patching, so no idea if that is new.
Comment #307
Damien Tournoud CreditAttribution: Damien Tournoud commented@nbz: The failure in BlogAPI probably means that you don't have clean urls enabled (see #296470: TestingParty08: BlogAPI tests should pass without clean-urls enabled).
Comment #308
NaheemSays CreditAttribution: NaheemSays commentedI have cleanurls.
The test is now complete - 9 more failures at XML-RPC validator, but that may be because this is a localhost without webaccess (no idea).
Total failed tests:
Request for user's blogs returned correctly. Other drupal_web_test_case.php 284 testBlogAPI
Post created. Other drupal_web_test_case.php 284 testBlogAPI
Recent post list retreived. Other drupal_web_test_case.php 284 testBlogAPI
Post found. Other drupal_web_test_case.php 284 testBlogAPI
Post successfully modified. Other drupal_web_test_case.php 284 testBlogAPI
File successfully uploaded. Other drupal_web_test_case.php 284 testBlogAPI
Uploaded contents verified. Other drupal_web_test_case.php 284 testBlogAPI
Post categories set. Other drupal_web_test_case.php 284 testBlogAPI
Category list successfully retreived. Other drupal_web_test_case.php 284 testBlogAPI
Post successfully deleted. Other drupal_web_test_case.php 284 testBlogAPI
array of structs test: %s Other drupal_web_test_case.php 284 testValidator1
count the entities test: %s Other drupal_web_test_case.php 284 testValidator1
easy struct test: %s Other drupal_web_test_case.php 284 testValidator1
echo struct test: %s Other drupal_web_test_case.php 284 testValidator1
many types test: %s Other drupal_web_test_case.php 284 testValidator1
moderate size array check: %s Other drupal_web_test_case.php 284 testValidator1
nested struct test: %s Other drupal_web_test_case.php 284 testValidator1
nested struct test: %s Other drupal_web_test_case.php 284 testValidator1
multicall equals result Other drupal_web_test_case.php 284 testValidator1
Warnings:
array_key_exists() [function.array-key-exists]: The second argument should be either an array or an object Warning blogapi.test 84
I will le someone else be the judge of what that means.
Comment #309
swentel CreditAttribution: swentel commentedSome first benchmark results, collected from irc this afternoon, by catch and swentel
ab -c1 -n500 http://drupal7/
* one node, front page, no page caching, no opcache
Catch: unpatched: 7.06 request/sec patched: 5.47 requests/sec (1/2 sec error margin.)
Catch: just ran again - 7 unpatched, 5.35 patched, so looks accurate.
Swentel: unpatched 6.35 r/sec , patched: 5.23 r/sec
* 5,000 nodes, 10,000 comments, 250 terms, 15 vocabs, 500 users.no opcache
Catch: unpatched: 3.64 reqs/sec patched: 3.29
Catch: normal page caching - 60 reqs/sec unpatched, 32 reqs/sec patched
Catch: aggresive: unpatched 55 reqs/sec, patched 37 reqs/sec
* 2500 nodes, 5,000 comments, 250 terms, 15 vocabs, 500 users. no page caching, no opcache
swentel: unpatched 5.15 [#/sec], patched 4.33 [#/sec]
[update] some more results
* 1500 nodes with terms attached, 0 comments, 250 terms, 15 vocabs, 500 users
note: devel generate triggered an pdo exception when trying to add random comments to nodes, so I left comments out of it for this testing
unpatched, no opcache, no page caching, 5.43 [#/sec]
unpatched, no opcache, normal page caching, 57.74 [#/sec]
unpatched, no opcache, aggressive page caching, 61.73 [#/sec]
unpatched, xcache, no page caching, 13.09 [#/sec]
unpatched, xcache, normal page caching, 175.44 [#/sec]
unpatched, xcache, aggressive page caching, 195.10 [#/sec]
patched, no opcache, no page caching, 4.40 [#/sec]
patched, no opcache, normal page caching, 34.07 [#/sec]
patched, no opcache, aggressive page caching, 34.69 [#/sec]
patched, xcache, no page caching, 9.19 [#/sec]
patched, xcache, normal page caching, 126.77 [#/sec]
patched, xcache, aggressive page caching, 138.59 [#/sec]
Comment #310
XanoThese are the results of Catch's tests. I had to find them in my IRC log by hand, so I hope I have found it all.Dries__: chx: one node, front page, unpatched: 7.06 request/sec patched: 5.47 requests/secchx: on this machine thoug, and I'm getting 1/2 sec error margichx: yes I can repeat - run about 4 times on eachchx: 'cos mine always seem weird. ab -c1 -n500 http://drupal7-test.localhost/ fwiwDries__: chx: just ran again - 7 unpatched, 5.35 patched, so looks accurate.//edit: I see swentel found all data already
Comment #311
catchWith APC, aggressive caching on:
Unpatched: 171 reqs/second
Patched: 110.07 reqs/second
With APC, no page caching:
Unpatched: 7.18 reqs/second
Patched: 4.69 reqs/second
Comment #312
webchickSo am I on crack, or do the benchmarking results above mean that this patch causes a 35-40% reduction in performance?
Comment #313
catchwebchick, unfortunately, you don't appear to have a crack habit.
Comment #314
Crell CreditAttribution: Crell commentedI strongly suspect this is caused mostly by code weight, since database.inc does grow in size with this patch. Earlier benchmarks from before the query builders were really built out showed that performance was about a wash, too. I'm going to do some refactoring tonight to move code around, which should help with the code weight.
Given the amount of code involved I don't think we'll see an increase, and a small decrease is probably acceptable as long as we can make it up elsewhere (eg, registry and further code splitting). I agree that a 20%+ hit is a bad thing, though. :-(
Comment #315
Dries CreditAttribution: Dries commentedI don't see how code size could result in a 30% performance decrease -- especially not when opcode caching is enabled. I don't know exactly how APC/XCache/etc are implemented, but the whole point of them is that they keep the compiled code in memory to avoid the parsing and (part of) the interpretation steps.
Two years ago, I wrote http://buytaert.net/drupal-database-interaction. It seems like that is exactly the experiment that we need to conduct to answer our questions.
Comment #316
recidive CreditAttribution: recidive commentedIMO, we'll be able to better measure the performance of the new database layer when we convert all queries to use the new methods, the type agnostic placeholders, and get rid of the legacy wrappers, specifically db_fetch_* ones which tends to be called thousand of times. Removing those indirections and using the full power of PDO prepared statements, it will surely perform better.
The question is, should we really wait for this patch to get in to do this conversion? I'm here to help.
Comment #317
Crell CreditAttribution: Crell commentedI was able to reduce the loss by doing some code reorganization last night. It's still slower than HEAD, though.
@ #316: Converting the rest of core in one fell swoop is absolutely not an option unless we're going to put 10 people on it over the course of 48 hours and guarantee that no other patches land in the same time period. We're just going to collide with everything else in HEAD otherwise.
Comment #318
chx CreditAttribution: chx commentedSome findings. module_implements is broken, adding a return in the
if ($refresh)part helps lots -- the registry cache was broken.The temporary BC layer is 1.61% of the page execution time. Not insignificant in itself but when we are after several tens of percents it does not worth the extreme effort to remove it.
db_query is 31818 vs 19832 (dunno what unit the profiler uses but what matters is the ratio) -- 50% more! This despite the fact that
php::mysqli_queryeats 7276 vsphp::PDO->execis just 3176 (!) even withphp::PDO->preparebeing 1317, we are quite good on the lower level.The real interesting thing is Database::openConnection which is called twice and alltogether costs 12266. There is a _registry_check_code in there called once which costs 8073 (!) -- is this some PHP automagic? 4908 is marked as being inside the function which would be strange given the length of the function. DatabaseStatement->execute function spends 2012 with itself. That's 0.76% percent of the whole page execution time. I picked on this because against it's too small. To give you an idea, the 22 user_access call spend 0.24% of the page time inside user_access and that function looks more complicated.
I attached the logs so you can cachegrind that as well.
Comment #319
dgtlmoon CreditAttribution: dgtlmoon commentedsubscribing
Comment #320
chx CreditAttribution: chx commentedComment #321
lilou CreditAttribution: lilou commentedIn htaccess ...
Comment #322
olav CreditAttribution: olav commentedIs there a description of goals and rationales for the new database layer?
This issue goes on for a long time now and is even continued from an earlier thread - I feel that I should be interested in this but it is impossible to tell from the task description what this is all about.
Comment #323
chx CreditAttribution: chx commentedComment #324
chx CreditAttribution: chx commentedWith less debug.
Comment #325
chx CreditAttribution: chx commentedComment #326
catchwarning: call_user_func(simpletest_menu) [function.call-user-func]: First argument is expected to be a valid callback in /home/catch/www/drupal7-test/includes/menu.inc on line 1730.
Also got duplicate key errors when running tests with existing content in db.
Comment #327
swentel CreditAttribution: swentel commentedBenchmarks with patch from #325
1000 nodes, 500 users, 15 vocab, 250 terms, mysql
unpatched, xcache, no page caching: 6.98 [#/sec]
unpatched, xcache, normal page caching: 142.66 [#/sec]
unpatched, xcache, aggressive page caching: 154.08 [#/sec]
patched, xcache, no page caching: 6.30 [#/sec]
patched, xcache, normal page caching: 133.03 [#/sec]
patched, xcache, aggresive page caching: 149.70 [#/sec]
Other things with the pach:
- Notices: Undefined index: default in /var/www/drupal/drupal-7.x-dev/install.php on line 197
- Something goes wrong with menu caching: When I enable devel generate or testing, it doesn't appear after submit. When reloading modules page or first going to other page and back to modules page, it's there. Same thing when disabling a module. Menu won't disappear after going to modules page again + some errors too:
warning: call_user_func(devel_generate_menu) [function.call-user-func]: First argument is expected to be a valid callback in /var/www/drupal/drupal-7.x-dev/includes/menu.inc on line 1730.
- Simpletests fail a lot
Comment #328
webchickComment #329
Crell CreditAttribution: Crell commentedswentel: Are you sure the issue with the modules page is not already there? I have no idea how this patch could be related. I've not seen any of the other issues you mention, and as of last night I was getting 100% test passage in MySQL. You'll have to define "a lot".
Comment #330
catchCrell: The modules page/menu issue is definitely due to the patch - both the menu item and admin/build/testing not registered without a second refresh of the modules page. When you disable a module, it also doesn't get rid of the menu items. It's menu_router_build - which has a module_implements in it.
Comment #331
chx CreditAttribution: chx commentedHEAD is a bit buggy isnt it. This patch fixes a number of registry related bugs... which makes tests pass.
Comment #332
Dries CreditAttribution: Dries commentedI'll review this patch in around noon tomorrow. That is in about 13 hours.
Comment #333
catchAll tests pass.
Requests per second, APC enabled:
No page caching:
unpatched: 6.69
patched: 5.93
Normal page caching:
unpatched: 126.64
patched: 110.22
Aggressive page caching:
unpatched: 148.87
patched: 145.67
So a 10% hit on uncached pages, but normal and aggressive is within 2-5%. I think it's reasonable to expect we can make up that elsewhere (and in optimising the db api once it's in, and removing the bc layer). So RTBC!!
Comment #334
catchCrell asked for benches without APC:
no page caching:
unpatched: 4.15
patched: 3.24
normal page caching:
unpatched: 55.22
patched: 54.36
Aggressive page caching:
unpatched: 61.54
patched: 57.66
Comment #335
CalebD CreditAttribution: CalebD commentedJust wanted to provide another voice echoing support for RTBC. All tests for MySQL 5.0.51b passed (4890 passes, 0 fails, 0 exceptions).
As Crell mentions in #305, there are some fails for PostgreSQL. I agree that these should be fixed in a follow up patch. This patch is way too big to be held up any longer. Here are the fails I ran into, for reference:
Search > Search engine ranking
Kills the testing process with an uncaught PDO Exception:
An error occurred. /drupal/head/drupal-dbtng/batch?id=4&op=do Fatal error: Uncaught exception 'PDOException' with message 'SELECT COUNT(*) FROM (SELECT i.type, i.sid, (? * COALESCE((n.sticky), 0)) AS score FROM {search_index} i INNER JOIN {search_total} t ON i.word = t.word INNER JOIN {node} n ON n.nid = i.sid WHERE n.status = 1 AND (i.word = ?) AND i.type = ? GROUP BY i.type, i.sid HAVING COUNT(*) >= ?) n1 - Array ( [0] => 10 [1] => rocks [2] => node [3] => 1 ) SQLSTATE[42803]: Grouping error: 7 ERROR: column "n.sticky" must appear in the GROUP BY clause or be used in an aggregate function' in /usr/local/apache2/htdocs/drupal/head/drupal-dbtng/includes/database/pgsql/database.inc:73 Stack trace: #0 /usr/local/apache2/htdocs/drupal/head/drupal-dbtng/includes/database/database.inc(1154): DatabaseConnection_pgsql->query('SELECT COUNT(*)...', Array, Array) #1 /usr/local/apache2/htdocs/drupal/head/drupal-dbtng/includes/pager.inc(72): db_query('SELECT COUNT(*)...', Array) #2 /usr/local/apache2/htdocs/drupal/head/drupal-dbtng/modules/search/search.module(955): pager_qu in /usr/local/apache2/htdocs/drupal/head/drupal-dbtng/includes/database/pgsql/database.inc on line 73
System > Module list functionality: 53 passes, 4 fails, 0 exceptions
Tables matching "aggregator" found. Other drupal_web_test_case.php 284 testEnableDisable
Tables matching "aggregator" found. Other drupal_web_test_case.php 284 testEnableDisable
Tables matching "languages" found. Other drupal_web_test_case.php 284 testEnableWithoutDependency
Tables matching "locale" found. Other drupal_web_test_case.php 284 testEnableWithoutDependency
Statistics > Top visitor blocking: 20 passes, 10 fails, 0 exceptions
Found name: simpletest_O4OH Other statistics.test 41 drupalLogin
IP address found. Other drupal_web_test_case.php 284 testIPAddressBlocking
Block IP link displayed Other drupal_web_test_case.php 284 testIPAddressBlocking
Clicked link block IP address () from http://server/drupal/head/drupal-dbtng/admin/reports/visitors Browser statistics.test 47 clickLink
IP blocking page displayed. Other drupal_web_test_case.php 284 testIPAddressBlocking
IP address was blocked. Other drupal_web_test_case.php 284 testIPAddressBlocking
Unblock IP address link displayed Other drupal_web_test_case.php 284 testIPAddressBlocking
Clicked link unblock IP address () from http://server/drupal/head/drupal-dbtng/admin/reports/visitors Browser statistics.test 61 clickLink
IP address deletion confirmation found. Other drupal_web_test_case.php 284 testIPAddressBlocking
IP address deleted. Other drupal_web_test_case.php 284 testIPAddressBlocking
Comment #336
catchFor reference, Damien made a list of postgres failures on HEAD: http://groups.drupal.org/node/14137 - it's a longer list than with the patch.
Comment #337
Crell CreditAttribution: Crell commentedSo under MySQL everything works, and under Postgres more things work than before. The performance hit is reasonably low, and there's plenty of places to optimize Drupal later (DB or otherwise) and to remove the BC layer, so it should be a wash by the time we're done.
Anything else to do? Beuller? Let's get this in before we have as many comments as we do KB of patch. :-)
Comment #338
Dries CreditAttribution: Dries commentedSorry for the delay. It took me a while to review/grok it. I've committed this patch as is, but I have a couple of follow-up issues/tasks that I will create.
Thanks for all the great work, folks! :)
Comment #339
mfer CreditAttribution: mfer commentedI just found an interesting quirk in PDO. If you do something like
it populates the attributes from db result row before it calls __construct() on the class className. If you want __construct() called first you need to do something like
PDO::FETCH_PROPS_LATE and this case don't seem to be very well documented.
This situation doesn't seem to be accounted for in DatabaseStatement::execute. It only allows for the first code case above.
Comment #340
mfer CreditAttribution: mfer commentedoops, I cross posted on Dries. I'll file a followup issue for this situation.
Comment #341
Crell CreditAttribution: Crell commentedmfer: One of many feature requests for follow-up patches. :-) Please file a new issue.
Comment #342
mfer CreditAttribution: mfer commentedAlready filled the issue at http://drupal.org/node/298309
Comment #343
catch#298329: Add new database layer to ugprade modules page
Comment #344
chx CreditAttribution: chx commentedStop crossposting please.
Comment #345
agentrickardThe patch has landed. There may be fallout bugs.
Let's please file those separately. This issue is too long to manage.
Comment #346
Garrett Albright CreditAttribution: Garrett Albright commentedDoes this mean that SQLite support via PDO is now a realistic possibility? Has anyone tried that yet?
Comment #347
Crell CreditAttribution: Crell commented#67349: Support SQLite databases and chx has already started prelim work on a PDO-based driver, I think.
Garrett: Please stop posting in this issue. It is finished. Let it die, man! :-)
Comment #348
Pasquallecongratulation!!! where is the champagne???
Comment #349
p.brouwers CreditAttribution: p.brouwers commentedDon't know if this is an issue, or was already mentioned before, but with my CVS checkout it tries to look for a database.inc file in the CVS folder which of course it can't find.
Comment #350
catch#298391: HEAD broken: Database engine initialization during install failure
Comment #351
moshe weitzman CreditAttribution: moshe weitzman commentedI have disabled comments for this issue, becuase we are bothering hundreds of people with each post. File a new issue for your concern.
If you *really* need to post here, ask an editor to reopen comments.
Comment #352
Anonymous (not verified) CreditAttribution: Anonymous commentedAutomatically closed -- issue fixed for two weeks with no activity.
Comment #352.0
gregglesdocs link