On this page
- Introduction
- What can you manage with code?
- Creating the Central Repository
- Locally Cloning Drupal
- Updating Remotes
- Creating a Working Branch
- Setting up the .gitignore file
- Customizing .gitignore
- Creating a global .gitignore file
- Pushing Code to the Central Repository and Completing Initial Deployment
- Adding Contributed Modules and Themes
- Dealing with versions and dependencies
- Topic / Issue Branches
- Bringing Branches Back into the Main Codebase
- Merging
- Staging and Production - Tag Based Deployment
- Handling Hotfixes
- Updating Drupal Core
- Managing the Database (& your sites/default/files directory)
- Using Submodules
- Moving a Custom Module or Theme into its own repository
- Example
OBSOLETE Building a Drupal site with Git
This documentation is deprecated.
Introduction
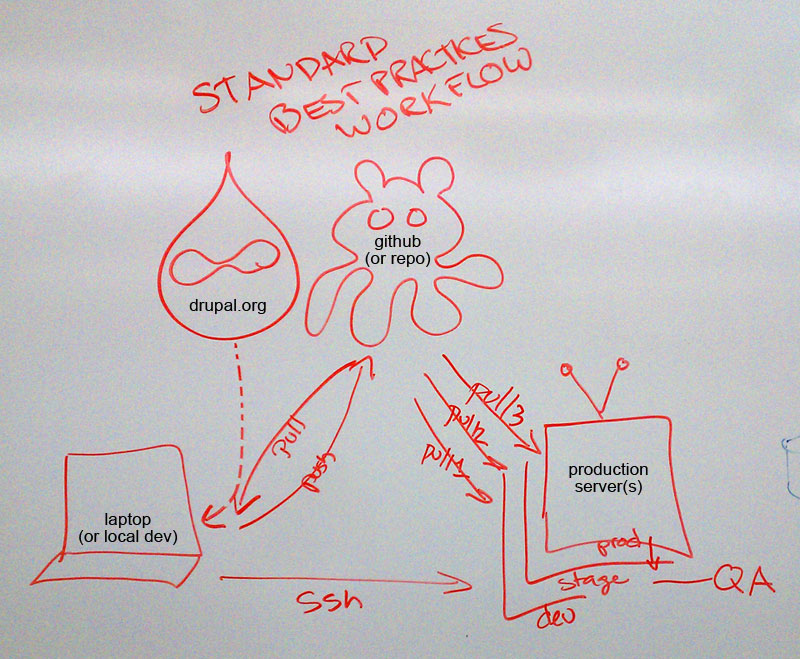
This document is intended to outline a basic process of using Git in the context of a basic site building, testing and deployment process. While there are many possible approaches to fitting Git into this process, this particular set of procedures should work in most circumstances and contains many best practices for using Git in this manner. When applied properly and with some forethought, Git is a very powerful tool for helping to manage collaboration, configuration and code changes during the life cycle of a Drupal-based project. Further documentation will be written to show how best to integrate other tools such as Drush into this process.
This documentation assumes that the project will be following a basic 4-tier development environment model: developers work on most code locally, then push that code up through Development, Staging and Production environments. It can easily be adapted to fewer tiers, as necessary. We will be illustrating the process by building out a Drupal site called ‘FooProject’, and will use fooproject as a placeholder anywhere a project or site name would be used.
What can you manage with code?
One challenge of using any kind of change management with Drupal is that many configuration changes normally reside only in the project’s database. You can move some of these configuration settings into code using certain Drupal modules, such as Ctools exportables, the Features module or the Configuration Management module. You may want to take advantage of these tools to export as much of your site’s configuration as possible into your repository for deployment and collaboration purposes. Additionally, the Backup and Migrate module can save database exports as files within your Drupal file tree; these are managed with Git like any other file.
Fortunately, since a Drupal site's module and theme files already live in code, you can manage those in Git without any extra tools.
Creating the Central Repository
When working on a project with multiple environments, a good first step after server provisioning is to create a central repository from which all other environments will pull. This could live on one of the servers provisioned for the project, a Gitosis server, a Gitolite server, a GitLab server, Github or any other repository hosting solution. For purposes of illustration, assume that your FooProject is running on a server configured with a user named ‘fooproject’ and all three environments will be running from separate directories under that user’s public_html directory. For convenience, create the central repository inside fooproject’s home directory.
(On your remote server)
$ cd ~
$ git init --bare fooproject.git
This command creates a new directory called fooproject.git that contains all of the git objects. This directory is not the working tree, where you edit and commit code. Rather, it is simply the central location for the git objects and history, and is essentially empty at this point.
Locally Cloning Drupal
This example begins the development process on the developer’s local development environment, but you could follow these steps on the server as well. Let's clone Drupal (version 7) to create a local development environment.
(On your local development environment)
$ git clone http://git.drupal.org/project/drupal.git fooproject
$ cd fooproject
$ git checkout 7.x
The first command clones the Drupal core Git repository from Drupal.org and saves it in a directory named fooproject. The fooproject directory will become your working tree. The final command, git checkout 7.0, ensures your code is on the Drupal 7.0 release. When using Drupal 8 or higher, note the addition of a decimal place in the version. For example, the equivalent command for Drupal 9.2.0 would be git checkout 9.2.0. To choose another release before install, you can run the following command to view a list of all releases:
$ git tag
Then, to switch to the version you want, you would type the following command, where <tagname> is the name of the release you want to use:
$ git checkout <tagname>
Updating Remotes
You’ll need to update your remotes to reflect that you won’t be pushing to drupal.org with your project’s code. You should rename the original origin remote (the drupal.org Drupal project repository) to ‘drupal’ and create a new origin pointed at the bare repository you’ve created on your server.
(On your local development environment)
$ git remote rename origin drupal
$ git remote add origin path/to/your/central/git/repo
(example: ssh://fooproject@fooproject.com/home/fooproject/fooproject.git)
To see a list of your remote repositories, run the command:
$ git remote
For a more detailed listing that includes the remote repositories' URLs, add a -v flag (for verbose) to the end of the command:
$ git remote -v
Creating a Working Branch
Now, you need a branch where you can track not only Drupal core, but also all of the contributed and custom modules and themes for your site. Create a branch using the command:
(On your local development environment)
$ git checkout -b fooproject
This command creates a new branch named fooproject and checks it out. It is equivalent to running the commands:
$ git branch fooproject
$ git checkout fooproject
You can use this fooproject branch as a working branch to add contributed and custom modules and themes to your site. Consider it the equivalent of the default Git ‘master’ branch for your project. For more information on standard Git development and branching see a post on A successful Git branching model.
At this point, you should complete the Drupal installation process to get a working local installation. For Drupal 8 or higher, you'll need to do 'composer install' in the Drupal site root before running the web installer:
$ composer install
Setting up the .gitignore file
There are a few things that you probably do not want to have tracked in the repository, namely sites/default/files and sites/default/settings.php. You would exclude the files directory if you prefer only to track application files in Git and to omit site content from the repository. You probably want to exclude settings.php because it contains sensitive database access information and will be different on each environment.
One way to tell Git to exclude certain files and directories from the repository is to set up a .gitignore file. When you clone Drupal 7 from the Git repository, it comes with a .gitignore file. Drupal 6 does not come with a .gitignore file at the time of this writing.
Drupal 8 or higher comes without a .gitignore but has an example.gitignore from which you can create a .gitignore. If you wish to transfer configuration between sites using git, you probably need to change the location of the config directory (which is set in settings.php) to one which is tracked by git. By default, the config directory is in sites/default/files, and by default the .gitignore which you create from example.gitignore will exclude this directory path.
The settings in the Drupal 7 default .gitignore file are as follow:
# Ignore configuration files that may contain sensitive information.
sites/*/settings*.php
# Ignore paths that contain user-generated content.
sites/*/files
sites/*/private
Customizing .gitignore
You may want to keep the above settings for your own site. However, if you decide to use different version control policies for your site, for example by deliberately excluding certain modules, themes, or libraries from your repository, you need different .gitignore settings. Here are some options for getting around the default .gitignore settings:
- If you don't want sites/all to be controlled at all (you want to ignore all modules and themes and libraries), add a file at
sites/all/.gitignorewith the contents a single line containing nothing but*. - Simply change the .gitignore and commit the change. You wouldn't be pushing it up to 7.x right?
- If you track core code using downloads (and not git) you can simply change the .gitignore and check it into your own VCS.
- Add extra things into
.git/info/exclude. This basically works like .gitignore (it has good examples in it) and is not under source control at all. - Add an additional master gitignore capability with
git config core.excludesfile .gitignore.customand then put additional exclusions in the.gitignore.customfile.
Note that only 1 and 2 are completely source-controlled. In other words, #3, 4, and 5 would have a slight bit of configuration on a deployment site to work correctly, but they work perfectly for a random dev site.
For more information about the above options, see Randy Fay's blog post:
http://randyfay.com/node/102
If you add a new ignore file or edit one that is not being tracked by Git, remember to add it to your Git repository using the git add command, and then commit those changes using git commit. For example:
$ git add .gitignore.custom
$ git commit -m "Initial FooProject commit"
Creating a global .gitignore file
You can also create global ignore settings across all of your Git projects. First, you create a global .gitignore file in your home directory (~/.gitignore). Then, you add it to your global configuration using the following command:
git config --global core.excludesfile ~/.gitignore
Pushing Code to the Central Repository and Completing Initial Deployment
Now, you can push your code up to the origin remote on your server:
(On your local development environment)
$ git push origin fooproject
This command copies your local branch fooproject to a branch of the same name in your remote repository origin.
You can now provision your other tiers with this code from the repository. Log into your server and provision a development environment from the code you’ve committed:
(On your remote server)
$ git clone --branch fooproject ssh://fooproject@fooproject.com/home/users/fooproject/fooproject.git fooproject_dev
Now, you have a fooproject_dev directory that you can use as the root of a new virtual host. You can proceed through the normal Drupal installation process using this development copy of your site and a separate database for it. Repeat this process for the Staging and Production environments- we'll assume that they live on the same server in directories fooproject_stg and fooproject_prod.
In Drupal 8 or higher the site should be installed only once (rather than repeating the install for dev, staging and production sites), and the different versions of the site should be created with databases set up using a dump of the database from the first copy of the site. This is because each install creates a distinct site with a site UUID, which would prevent import of configuration between the dev, staging and production versions of the site (subject to #1613424: [META] Allow a site to be installed from existing configuration being solved). After copying a site's database, it will be necessary to clear the caches (which can be done from Manage > Configuration > Performance, or using drush from command line).
Because the install is only run on the first copy of the site, it will also be necessary to open settings.php on each version of the site, and manually adjust the database settings in it to use the relevant copy of the database for each version of the site. Naming the databases similarly to the code directories, such as fooproject_dev, fooproject_stg, fooproject_prod, can help avoid confusion .
If you have set up a default .gitignore which excludes the sites/*/default folder before copying the code to each version of the site using git, settings.php and the config directory (assuming it is still in the default location) will not have been copied when copying the code with git. In that case, so you would need to manually copy settings.php to each version of the site, and you would need to either manually copy the config directory or rebuild it, in order to get the copies of the site working. For troubleshooting after copying a site see https://www.drupal.org/documentation/rebuild.
Adding Contributed Modules and Themes
The site development process rarely ends with core Drupal - you'll likely be adding contributed modules and themes throughout the development process. There are a number of possible approaches to this process that additional documentation on Git Submodules, Drush and Dog will describe. For the purposes of this documentation, we are not concerned with keeping Git history for contributed modules. Simply download and install these modules and themes to your site and add them to your main development branch. Let’s use Views as an example:
$ cd sites/all/modules
$ wget http://ftp.drupal.org/files/projects/views-7.x-3.0-beta3.tar.gz
$ tar -xzf views-7.x-3.0-beta.tar.gz
$ rm views-7.x-3.0-beta.tar.gz
If you check the status of your repository at this point, Git will point out to you that you have some new untracked files living in your working tree:
$ git status
# On branch fooproject
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# views/
nothing added to commit but untracked files present (use "git add" to track)
So, we’ll now add them to the Git index:
$ git add views
$ git commit -m “Add Views 3.0-beta”
You can now push this code back up to your central repository and pull it down to your Dev server:
(On your local development environment)
$ git push origin fooproject
(On your remote server while inside the fooproject_dev directory)
$ git pull origin fooproject
At this point, you should see the Views code in both your local environment as well as on the Development server’s codebase, and you should be able to enable this module in both environments. You can follow this basic procedure for adding any contributed module, contributed theme, or custom code to your site.
Dealing with versions and dependencies
When a module requires a specific version of another module, it's called a version dependency. For example, the Media 7.x module specifically requires the 7.x-2.x branch of the File entity module. If you don't have the right version of the File entity module, you can't enable Media.
If you've downloaded a tar.gz or zip file from Drupal.org, the version information is in the files you downloaded. But when you check out a module from Git, you've bypassed the Drupal.org packaging script and the information is missing.
To solve this, Drupal must get the version information directly from Git. To do so, download and enable:
Topic / Issue Branches
As your project progresses, you may find yourself in a situation where you need to work on an issue or feature outside of the main code-base, where your code changes won’t impact your fellow developers or your client. Alternately, it’s not uncommon to engage in fixing an issue with your code, only to find that the solution is more involved than you have resources to commit to it at the moment. In these situations. it’s helpful to be comfortable with Git’s branching system in order to give you a clean sandbox to work on your changes without losing the ability to pull code from the central repository.
Assuming you're currently on the main fooproject branch before you begin working on an issue submitted by your client, the workflow is simple:
$ git checkout -b issue_606_theme
This command creates a new branch for the issue based on the branch you were on before issuing the checkout command. At this point, you can work on code and commit changes to this local branch without any worry of losing your work in progress or being able to switch back to the main code-base to work on other issues.
Let’s assume that this particular issue involved changing something in your theme’s page.tpl.php file. Once you've edited the file, you can follow the basic change/add/commit workflow of Git:
$ git add sites/all/themes/footheme/page.tpl.php
$ git commit -m “Issue 606: Remove offending div from page.tpl.php”
You can make as many changes and commits to your branch as required to fix your issue or implement your feature. At this point, all of these commits are living in a branch that exists only on your local copy of the repository. If you have need to switch back to the main branch, you can add and commit your files in your topic branch and issue the following command to get back:
$ git checkout fooproject
Once you've brought your topic branches back into your mainline fooproject branch, as detailed below, it’s a good idea to clean up after yourself. When you've decided you no longer need that topic branch, deleting it is a simple command:
$ git branch -d issue_606_theme
If you’ve created a topic branch but never merged it back into it’s parent, Git will keep you from deleting it accidentally. If you’re sure that you no longer wish to have this unmerged branch, simply replace -d with -D to force deletion of the unmerged branch.
Bringing Branches Back into the Main Codebase
Once you have finished working on your fix or feature, you’ll need to bring those changes from your topic branch back into the main fooproject branch. There are a number of different strategies and opinions on managing the merging of code using either Git’s rebase or merge commands. Here are some basic considerations:
- If your branch’s commit history is considered public (i.e. multiple developers working on the same topic branch in their own repositories) - ALWAYS choose Merge.
- If you’re concerned with keeping a clean, linear history - Rebase.
Please note that these ground rules are nearly mutually exclusive.
For the purposes of this documentation, let's assume that you are going to use the basic merge-based strategy. For suggestions about using Git's rebase command, read Randy Fay's post at http://randyfay.com/node/91.
Merging
If you are the primary developer on a project, and you are not concerned with maintaining a completely linear history from your topic branches, using Git’s merge command provides a straightforward way for you to bring your topic branches back into your mainline codebase.
$ git checkout fooproject # Puts you back into your main branch
$ git pull # Fetch and merge changes from your main repo back into your local fooproject, if any exist
$ git merge issue_606_theme ## Merges your topic branch back into fooproject
$ git push ## Sends your newly updated fooproject code back to the origin repository
Staging and Production - Tag Based Deployment
You could simply allow your Staging and Production environments run from the code you’ve been adding and merging into your main fooproject branch - but it’s worth considering the fact that the fooproject branch is going to be moving forward as development progresses even after your site’s launch, and production sites should really be running a single, well-tested snapshot of the code-base during ongoing development. For this reason, it’s a good idea to use tags instead of branches for managing your non-development code. Tags are simply references to the state of the code-base at a specific commit - a snapshot of the project at one specific moment in time.
When your code has been tested and is ready to be deployed into the production environment, you could follow this process locally:
$ git tag prod_20110419 ## Creating a tag from the current commit. You can specify a commit here if you wish.
Now, you can push this tag up to your repository:
$ git push origin prod_20110419
Now, in your server’s fooproject_prod directory:
$ git pull
$ git checkout prod_20110419
Handling Hotfixes
An inverse procedure can be used to handle changes that need to be made to code in the production environment. Because your production and staging environments are running from tags, they are considered to have a ‘detached HEAD’ - with no commit history, and no branch to commit into. You probably saw Git warning you of this situation when you checked the tag out. Still, git makes it easy to manage hotfixes in this way. For example, you’ve been told about a bug that was just found in production, and it needs to be cleaned up right away. Open your local development copy and perform the following:
$ git checkout prod_20110419 # switching to the offending production branch
$ git checkout -b prod_hotfix_issue_707 # you’re now starting a new branch that begins at your current prod tag
# Code to fix the problem
$ git add <changed files to be committed>
$ git commit -m “Production hotfix for issue 707: Fix production bug”
Now, you can create a new tag from this commit to run on
$ git tag prod_20110515_hotfix_707 # create the new tag
$ git push origin prod_20110515_hotfix_707 # and push it to the repository
Now, logging in to the production repository:
$ git fetch --tags #update the dev repo with your pushed changes from production
$ git checkout prod_20110515_hotfix_707 # puts you back into a detached HEAD state against your new tag
Now, you’ll can merge that code back into your local fooproject branch
$ git checkout fooproject
$ git merge prod_20110515_hotfix_707 # brings the hotfix code back into the mainline code-base
Updating Drupal Core
In this workflow, managing updates to Drupal core is a fairly trivial process:
$ git checkout fooproject # making sure we’re on our main fooproject branch
$ git fetch drupal # update our repository with changes from the main Drupal upstream repo
$ git merge 7.1 # merge in the updates to Drupal
Then, run update.php and your code and database should be properly updated. If you wish to test the upgrade first, you could always create a new topic branch for the update testing process and merge the Drupal release tag to that branch before bringing it into your mainline codebase. From there, simply create new stg_ and prod_ tags, push them to the repository and pull them into your other environments as above, making sure to run update.php after checking them out!
Notice that in this particular workflow, modules are kept as part of your own code-base and not pulled with Git from drupal.org. Update these modules as per the normal Drupal documentation or with the drush up command, run update.php, then add and commit the updated modules to your repository.
Managing the Database (& your sites/default/files directory)
Data always needs to flow down-stream. That means your live database should be copied and imported to your test site, your dev site, and your local environment - and never moved the opposite direction. This is to prevent data loss. If you have users creating accounts, posting comments, or modifying content - that should all be happening on your live site. If you copy a development database into production any of those changes will be lost.
Because data should never be moved up-stream, it's a good idea to have at least three copies of your drupal site to work with. The live site, where your data grows, but you never do any development. The development site, that will use a recent copy of the database and files from the live site, but has no active changes so that it's a safe place to work on code, install new modules, and do other things that might be considered "too risky" to do on the live site. And the test site, where you can push up the code you've changed on the development site, and pull down the data that's been growing on the live site. This gives you a chance to see what will happen when your changes are pushed into production. A place to do test deployments, where the code and the data can be safely tested together.
For managing configuration in Drupal 8 or higher, please refer to the Managing your site's configuration documentation. In Drupal 7 and earlier versions, the database contains a mix of both data and configuration. In order to safely deploy configuration changes you may have made to your development site, they will need to be stored in code. There are several ways to do this:
- Use the Features module
- Use the Configuration Management module
- Use Ctools exportables (views, panels, etc) in your own custom module
- Use update hooks in your own custom module
If you are unable to get your configuration changes into code, you can also keep very good notes of every single change that was made, and manually make them again both on the test site, and on production.
Using Submodules
Git submodules allow foreign repositories to be embedded within a dedicated subdirectory of the source tree, always pointed to a particular commit. See git help submodule for more information. Submodules are ideal to capture both contributed modules and custom modules in a git-managed Drupal installation.
Moving a Custom Module or Theme into its own repository
Custom modules and themes can be tracked as a git submodule.
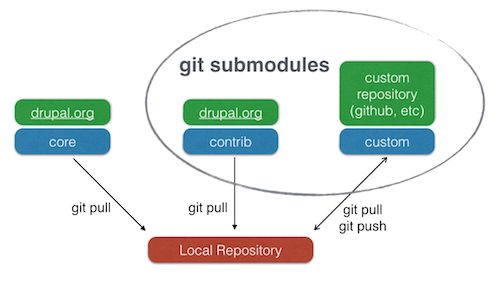
Example
In order to install Display Suite as a submodule to the main Drupal 8 or higher repository.
First find the Repository of the Drupal module at the "Version control" page of the module.
cd <drupal_root>
git submodule add http://git.drupal.org/project/ds.git sites/all/modules/_contrib_repos/ds
After adding the submodule you should have a file next to your .git folder named .gitmodules:
[submodule "sites/all/modules/_contrib_repos/ds"]
path = sites/all/modules/_contrib_repos/ds
url = http://git.drupal.org/project/ds.git
The submodule will not automatically upgrade with the main Drupal repository, but you can use the normal git commands in the submodule folder:
cd sites/all/modules/_contrib_repos/ds
git status
Once a developer has added, committed, and pushed the update for the Display Suite submodule to the central repository, everyone else can update their local repositories easily:
cd <drupal_root>
git submodule init # This is only necessary when your are grabbing the submodules for the first time.
git submodule update
git submodule foreach git checkout master # This fix the issue of detached heads for some submodule
Help improve this page
You can:
- Log in, click Edit, and edit this page
- Log in, click Discuss, update the Page status value, and suggest an improvement
- Log in and create a Documentation issue with your suggestion
