Problem/Motivation
Ideally, I should be able to assign an arbitrary state to any revision. I could have a published revision, a revision pending approval, and a draft revision beyond that.
Core, however, doesn't support such a workflow, because the most recent revision is always stored in the {node} table. This leads contrib to have to wire numerous workarounds for that default behavior.
If we would instead store the "default" revision in the {node} table by default, then contrib is free to develop more complex workflows without having to work around core limitations.
Proposed resolution
During node_save() only save to the {node} table if an "isDefaultRevision" flag is present -- by default it is. If the new revision is not "default", then do not update {node} and the respective field data tables. This makes the "default" revision the front facing representation of the node, while there might be any number of revisions dated before and later than this one.
As a followup, this logic should be abstracted to other entity types.
As a followup, this logic will allow for branched revisions in the event that two users edit the same node. Currently, when a user saves a node that another user has open, user 2 is denied a save. With this patch in place, that logic can change so that user 2 saves a new, but not default revision.
Remaining tasks
Needs documentation.
Needs additions to handle the behavior of node properties -- e.g. path and menu should only update on the "default" revision. There may also be UX fallout for node properties. The patch to change property handling has started at #1522154-1: Saving non-default revisions shouldn't trigger a search reindex
User interface changes
There are no user interface changes in this patch, we purely target an API addition.
API changes
Modules that provide static properties would need to incorporate a "only update if this is the live revision" check.
Modules that provide field storage should be unaffected.
Original report by jstoller
In an article-based site, content is typically submitted as a draft, possibly edited, and then approved. At this point it stays up until it is no longer relevant and is archived or deleted from the site.
In contrast, most of the content I deal with is largely static, but must be edited periodically. The edits must be reviewed and approved, just as the initial draft was. However, all this must be done without taking the originally approved page off line. In other words, new revisions should not alter the published revision.
For example, consider the "About Us" page of an organization's website. Once published it must be available 100% of the time. It can't be taken down for editing, but now and then editing is necessary. In many cases, the individual doing the grunt work of editing the page is not authorized to approve said content changes. Once the edits are made, they must be reviewed by more senior staff, possibly edited further, and finally approved to go live. While this editing is taking place, the public should still see the original, un-edited version of the page when they go to the website.
The Revision Moderation module attempts to deal with this deficiency, but I believe this feature should be part of the core Drupal development. There are just too many situations where this capability is needed to ignore it.
Ideally, I should be able to assign an arbitrary state to any revision. I could have a published revision, a revision pending approval, and a draft revision beyond that.
In practice, I picture a sort of "virtual staging site." Users with the appropriate permissions could flip a switch and browse the site as if all unpublished content awaiting approval was published, while the general public still saw only the previously approved content. Once an approver was happy with the draft revision of a node, they could change its state to published and it would magically go live for the public. This permits decentralized, collaborative content development, but still allows for a more centralized approval process when necessary.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
catchI know webchick has mentioned the possibility of trying to get revision moderation into core. The main thing would be a way for core to handle various states for revisions, then UI/workflow stuff like seperate save and publish buttons, approval queues would be a lot easier to do in contrib (with maybe a 'draft' state in core?).
+1 anyway.
Comment #2
mki commented+1. Please consider also "stable versions" feature from Wikipedia. I wonder can we have stable version but users (anonymous or logged in) still can view and edit the latest (draft) version.
Comment #3
cwgordon7 commentedWhy not just move fields from the node table to the node revisions table? (In particular, the 'status', 'sticky', and 'promote' fields?)
(subscribe) :)
Comment #4
alan d. commented+1 to this feature.
The lack of this feature prevents/hinders the usage of Drupal in larger corporate/governmental installations where this requirement is listed as vital.
Comment #5
catch@cwgordon - moving those fields sounds like a good way to approach this.
Comment #6
jstoller#301058: Add Revision Moderation to 7.x Core? marked as duplicate of this issue.
Comment #7
ultimateboy commented+1 to the idea, subscribe.
Comment #8
bsherwood commentedI updated the issue I created:
#301058: Add Revision Moderation to 7.x Core?
Maybe you can provide more details to this.
Thanks
Comment #9
jstoller@ specmav: Here's a basic example...
As an editor of my companies website, I create a new page node. I do not have permission to publish nodes, so this node is in what I will call the "Draft" state. Perhaps I edit this node a few times before my boss, the site moderator, approves it. At that point revision #3 of my node, which was in the "Draft" state, is switched to the "Published" state. Now the node will appear in my site hierarchy and the public can read it. Then one day I go back to that node and edit it some more. However, I still don't have permission to publish content, so my edits create a revision #4 in the "Draft" state, but revision #3 remains in the "Published" state and that is what the public continues to see when they browse my website. If later on the moderator is happy with my edits and approves them, then revision #4 will be switched to the "Published" state and the public will be able to see the changes, but at no time during this editing process will the page disappear from the site.
This describes a simple two-state system, which I believe is what the Revision Moderation module is trying to implement. There is the current revision (which I was calling "Draft") and there is the published revision. Sometimes the current revision is "Published" and sometimes it isn't, but the public always sees the "Published" revision.
This basic capability would be a major improvement and would likely fulfill most peoples' work flow needs. However, when looking for ways to implement this I suggest we consider the possibility of allowing an arbitrary number of states for revisions to be in. This may not be that difficult. Especially if we are OK with restricting each individual revision to one state. For instance if, as cwgordon7 suggests above, we move some fields from the node table to node_revisions, the only other change would be to allow multiple values in the status field. Instead of a check box to indicate whether a node is published or not, we could have a drop-down selector. By default the status selector would include "Published" and "Unpublished" as choices, but site admins and module developers would be able to extend this list to support more advanced work flows (likely all through contrib modules).
I can't understate the importance of this feature.
Comment #10
moshe weitzman commentedsubscribe. i too think this is much needed in core.
Comment #11
FrankieBegbie commentedSubscribing. This would be a wonderful addition, especially if user-defined multiple states were implemented. I hacked together a horrible "Draft > Pending > Published" workflow in conjunction with the the node access tables to get this functionality in a D5 site, so I'll revisit that and see if I can at least give ideas on what *not* to do.
Comment #12
chriz001 commentedSubscribing. i also think this would be a valuable feature.
Comment #13
steve02476 commentedSubscribing. This is crucial for a professional site that will have non-professionals contributing to it by editing existing pages.
Comment #14
jstollerForgive my naivete, but how do we make this happen? There seems to be some general agreement that this feature is a good idea. I'm afraid I'm more of a front-end user experience guy myself—so I won't be much help on the programming side of things—but I can tell you from the user experience perspective that this is important. What can I do to make sure this feature finds its way into D7 core? I would hate to see another version of Drupal slip by without this fundamental capability.
Comment #15
webchick@jstoller: One way to start might be to mock up a "spec" of sorts for a coder to conform to. I think lots of people have different ideas of what it means to have moderation in core. If you can draw a "picture" (via a set of annotated screenshots / diagrams that illustrate what you're thinking), that might help attract a developer to work on the problem if it seems "solvable."
I marked #118134: Put back moderation in core as a duplicate of this. Although that one is technically older, this one seems to have more recent attention.
Comment #16
babbage commentedSubscribing. +1 to having this work really well—I admit I haven't thought it through enough to be sure personally that I think it needs to be in core but interested.
Comment #17
mdupontSubscribing. Integrated with Rules, a way to define custom "states" (using an integrated method, or taxonomy, or flags...), and some kind of content access you would have a very flexible way to define advanced publication workflows:
Currently only Revision Moderation allows to leave an existing revision published while new ones go into moderation. But it doesn't allow defined roles to access the pending revisions (you need the "administer node" permission, which is overkill), and like with modr8 you can't have the several steps of approval needed in a large website.
Comment #18
webchickWe are not putting Rules in core.
Comment #19
mdupontSure, I was just explaining my needs and plans in regards of revision moderation, in conjunction with contrib modules (I'm not suggesting to put them in core). As long as we can leave existing revisions published while new ones can be in a "not yet published" state, and that we can assign role permissions for viewing and editing these it would be fine :-) I think that this capability would be very useful in core. If nodes can be in a "Draft" status (created but not published yet), revisions should have the same abilities.
Comment #20
jstollerPer webchick's suggestion, I've thrown together a glimpse of what this might look like from the user's perspective. Hopefully this will provide a jumping off point for further development.
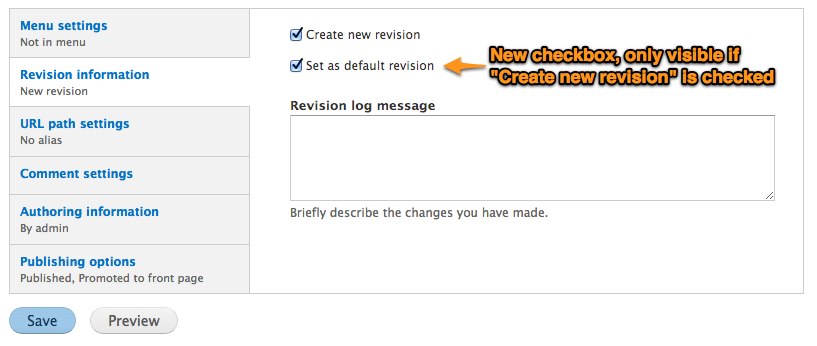
Most user's interaction with this feature will be on a node's edit page. Instead of the traditional publishing options provided on an edit page, with a simple check-box for "Published" [image], there would be a select widget [image]. This allows a user to choose the revision's status from a list possible states.
Remember that this status is associated with the revision, not the overall node.
Under the Site Building menu, users will find a States page [image]. This is much like the current Menus page. It lists all the "state groups" that have been defined. When creating content types, users can select any one of these state groups to associate with that content type. This will then determine what options are available in the status selector when editing nodes of that type. Under the Settings tab, you can set which state group will be assigned to new content types by default [image].
If you edit one of the existing state groups, or add a new one, you'll come to the "Edit state group" page [image]. Each state group can be given a title, a description and an arbitrary number of states. The states can be ordered as you would like them to appear in the status selector on node edit pages. Due to the ambiguity of multiple states with arbitrary names, I've included a check-box to indicate which states should be considered published. Note that it is possible to have multiple published states (why not?).
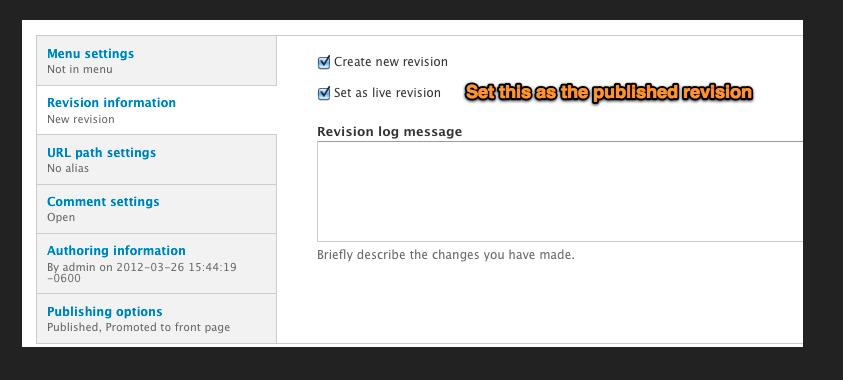
If you edit one of the existing states in the group, or add a new one, you'll come to the "Edit state" page [image]. As with state groups, you can give each state a title and description. You can manually set the weight of the state, though I expect most people will use the drag-and-drop table on the state group page. You can also set which states this state is allowed to transition to, and which rolls have permission to initiate that transition. Any transitions that are not allowed, or for which you do not have permission, will appear grayed-out in the status selector on applicable nodes. For instance, looking at the image above, if an Editor was working on a Published revision she would only be able to save it as Draft or Review. Every other option would be grayed-out. I've also provided a check-box to force a transition to create a new revision, rather than modify the existing one. Returning to the above example, If our Editor saved her changes as Draft, it would actually create a new revision in the Draft state, while keeping the old revision in the Published state.
It goes without saying that integration with Triggers and Actions is a must. Any state transition (including to the same state) should be available as a trigger. In fact, the "create new revision" feature I described above could be implemented as a triggered action if you didn't want to complicate things here. It seemed like a nice touch though.
The allowed transition check-boxes may be unnecessary, as you could just assume that any transition with associated rolls was allowed, but for some reason my gut tells me to keep them in there. And in theory you could manage all of the transition permissions from the User Management console, but from a usability standpoint it really, really makes sense to keep that functionality here as well.
Let the games begin!
Comment #21
jstollerIf you'd like to see a specific use case, take a look at this state diagram. It shows our current concept for the approval process we want to implement in a new institutional website. Please forgive my UML though. I'm just learning and I may not be following the rules precisely.
This use case requires a six state process. Right now we're trying to figure out how we can implement this in Drupal 6, but it isn't pretty. If Drupal supported revision states, I expect it would be a snap to implement.
Comment #22
mdupontWow, this a very nice, useful and well thought draft :-) Being able to have an arbitrary number of states (not only Published / Not published) for revisions and nodes would be extremely useful for a lot of people and is really in Drupal's tradition of flexibility. It could be a way to finally bring features of the workflow.module into core - referring to http://groups.drupal.org/node/2119 from 2006(!): "Dries had said he would like to include a configurable workflow system in core" .
The actual (D6) workflow.module is quite complicated and doesn't care about revisions (if I believe its issue queue). The only way to build the kind of workflow we are talking about here (i.e. having a workflow applied to new revisions without unpublishing existing ones) would be to develop a new action "Create new revision" on workflow state change while keeping online the last approved/published revision (thanks to a Revision Moderation-like module). If anyone has an idea about how to achieve this...
Comment #23
jstollerI was starting to think about what the database structure might look like if we implement this feature, when it occurred to me that this may be impacted by the fields in core initiative. Will Title, Body and Teaser fields be moved out of the node & node_revisions tables? That does seem to make sense. I know I've wanted to create content types that don't have a Body field, or that have a custom Teaser field implementation. If that's the case, I'd think it would simplify the role of these tables pretty dramatically.
Comment #24
jstollerSo, if I assume my previous assumption is correct and all content fields will be moved out of these tables (instead using the new field API), then would something like what follows make sense? Let me preface this by saying I'm no DB designer, and to be honest I'm still a little fuzzy about how some of the existing fields are used, but I thought I'd give it a shot in the hopes it will spark some inspiration in those of you with a better grasp of this stuff.
type
uid
created
changed
comment
language
tnid
translate
vid
uid
timestamp
log
format
sid
promote
sticky
name
module
description
sgid
help
name
description
module
sid
name
description
weight
published
access_arguments
sid
tsid
access_arguments
The node table has only those fields that are specific to the entire node. Anything that could change based on a node's state is moved to the node_revisions table. This includes the promote and sticky fields. Instead of a status field indicating whether or not a node is published, we have a sid (state ID) field. This integer references one of any number of states a given revision can be in.
Note that the moderate field is no longer applicable. Moderation is not an on/off setting, but rather a highly flexible system based on the states and state transitions you enable for a given content type.
A given set of states will be associated with a specific state group. The sgid (state group ID) is determined by the content type assigned to a node. Access to revisions in specific states can be restricted by role in the node_states table. Transitions between states in a given state group are detailed in the node_state_transitions table. The transition from any state (sid) within a group (sgid) to another state (tsid) within that group can be restricted to specific roles, or disallowed all together. And of course any defined transition could trigger an action.
I've included a published field in the node_states table. You could potentially have multiple states in a state group that were all considered published. "Published" becomes a property of revisions in those states, rather than a state in and of itself. This may allow for some interesting flexibility when creating workflows.
Comment #25
jstollerI think I answered my own question.
#372743: Body and teaser as fields
Comment #26
webchickWow! I hadn't been looking at this issue in awhile. Great work speccing out a path forward, jstoller!
It sounds like the next step is to spawn a few sub-issues to put the necessary plumbing in place. For example, creating an arbitrary states system and migrating published/sticky/etc. to it should probably handled separately from any moderation in content.
The smaller and more well-scoped individual issues are, the easier they are to review, and thus the easier they are to commit. http://webchick.net/please-stop-eating-baby-kittens
Comment #27
jstollerI think perhaps I've been mixing up the requested feature and its possible applications a bit too freely in this discussion. As I see it, any content moderation could be handled using triggers and actions, or a contrib module, like Workflow. I expect all that can be worked out later, once the underlying foundation is in core.
The real issue is developing the multi-state revision system and reorganizing the database schema to support it. All else will flow naturally from this, in time. Can this monster task be broken up into smaller chunks? I would hate for any innocent kittens to loose their lives. Anyone want to take a crack at this? You'll have my undying respect and admiration. ;-)
Comment #28
mdupontI was told about the new Revisioning module, which seems to allow workflows at revision level.
Comment #29
jstollerI'm looking over the Revisioning and Module Grant modules now, and I'm hopeful that they will help me workaround my immediate obstacles. However, I do not think their existence obviates the need for this feature. Implementing basic publication workflows should not require elaborate workarounds to deal with core deficiencies in Drupal. At the very least, Drupal Core should provide a foundation that cleanly supports these features. I believe multi-state revision support would be a big step in that direction. It would give contrib modules a central framework to build off of and lessen the probability that they will conflict with one another.
Comment #30
aac commentedSubscribing!!
Comment #31
aac commentedComment #32
comicat commentedsubscribe.
Comment #33
realityloop commentedI'm not sure what the current consensus is on this but it may be worth checking out the save_as_draft module, which I recently patched to work with drupal6.
This allows you to have a working draft without affecting the published version of the page.
Anyone with access that edits the node will be shown the current working draft to continue editing.
Once save as draft is unchecked the draft is published
http://www.drupal.org/project/save_as_draft/
my patch for drupal6
http://drupal.org/node/296537#comment-1405826
Comment #34
kemitix commented+1 subscribe
Comment #35
jstollerI understand the code freeze for Drupal 7 is fast approaching and I fear opportunity may pass us by. All the moderation features and such we've discussed can be implemented in contrib for the time being, but the fundamental concept of supporting revisions of the same node in different states must be implemented in Core if is to work properly. That will give the contrib modules the tool they need.
This idea has received a good deal of support, but alas there has been little movement on implementation. Given that #372743: Body and teaser as fields has been committed to Core, now seems like a good time to make these modifications. I'm marking this issue as a task in the hopes it will inspire some kind soul to pick up the torch. My own skills have taken me about as far as I can go on this, but if there is anything I can do to further facilitate the completion of this task, just let me know.
Comment #36
webchickI think you've done a great job speccing this out, jstoller. Maybe the next place to try would be in something like the Wiki group on groups.drupal.org, or in the issue queue for some of the revision-related modules such as Revision Moderation? Might be able to entice a module maintainer or user who does not regularly follow the core queue?
Just a thought.
Comment #37
catchWe can't move status / promoted / sticky out of the node table - these are used in a lot of queries. i.e. we absolutely want to avoid a change from SELECT nid FROM node WHERE status = 1 to SELECT nid FROM node n INNER JOIN on node_revisions nv node_revisions WHERE n.vid = rv.vid AND rv.status =1.
However, node_revisions should at a minimum allow you to reconstruct the full state of a node for any revision - this to me means we should start with duplicating the status, promoted etc. columns in that table like we currently do for uid and title. Have more thoughts on this in general and would really like to see save as draft and some basic revision workflow in core but no time to write more now.
Comment #38
johngriffin commentedsubscribe.
Comment #39
jstollerHere's an updated version of my proposed database architecture, taking new information I've gleaned and feedback I've received into account. For instance, while the Body and Teaser fields will be moved out of the node table and instead use the new Field API, the Title field will not. Again, I'm no DB designer, so someone trained in this sort of thing should take a look at this.
vid
type
uid
title
created
changed
comment
sid
published
promote
sticky
language
tnid
translate
vid
uid
title
timestamp
log
format
sid
published
promote
sticky
name
module
description
sgid
help
name
description
module
sid
name
description
weight
published
access_arguments
sid
tsid
access_arguments
Per catch's comment (#37) above, I returned promote and sticky to the node table, duplicating their appearance in the node_revisions table. I've still removed status, but replaced it with both sid (state ID) and published. These are also duplicated in the node_revisions table. The sid field contains an integer referencing one of any number of states a given revision can be in (see the node_states table). The published field is similar to the current status field, except you could potentially have multiple states in a state group that were all considered published. "Published" becomes a property of revisions in those states, rather than a state in and of itself. This may allow for some interesting flexibility when creating workflows. This field can then be used as a short-cut to determine whether a node is published or not, which should speed things up on sites with simple two-state workflows.
Given this duplication of fields in the node and node_revisions tables, it begs the question "which revision should the node table reflect?" Should it be the most recent revision or the most recent published revision? Should this be configurable by the site admin?
Note that the moderate field is no longer applicable. Moderation is not an on/off setting, but rather a highly flexible system based on the states and state transitions you enable for a given content type.
A given set of states will be associated with a specific state group in the node_state_groups table. The sgid (state group ID) is determined by the content type assigned to a node. Access to revisions in specific states can be restricted by role. Transitions between states in a given state group are detailed in the node_state_transitions table. The transition from any state (sid) within a group (sgid) to another state (tsid) within that group can be restricted to specific roles, or disallowed all together. And of course any defined transition could trigger an action.
Comment #40
mradcliffeDo approval and node states really need to go into core? It's my understanding that complex workflows and states should be possible and implemented in contrib. However, the ability to make these shouldn't be restricted by core (i.e. we don't want to kill domo-kuns to make it possible).
I still think that just being able to choose what revision is "current" or "live" would be suitable. Adding the promote/sticky fields would also be helpful too. The node state tables in the post above probably should be left to contrib.
Apologies for the crude flow chart below. Currently, we just flow right down the chart. Contrib has its chance to do validation at the validate stage, and save extra data. However, if a new revision is created, it's always the "current" or "live" revision. With a UI (and via API) option during node edit dependent on permissions could send a new revision to its own branch. It could later be made live via the UI (or API as seen via the green contrib branch). Whatever happens in the contrib branch in terms of approval workflow happens in its own space, and could support whatever it needs to.
Comment #41
mradcliffeI had been working on this in the past month or so, and had a basic patch for changing how revisions can be manipulated in core. Still needs work though.
I cleaned it up a little just now so maybe someone else can work with it.
Comment #42
jromine commentedsubscribe
Comment #44
jstoller@mradcliffe: I think node revision states absolutely need to go into Core. How those states are used to create workflows could live in contrib—at least for now—but in my mind the only way to cleanly allow contrib modules to deal with workflow issues is to provide a mechanism in Core for associating a state with each revision of a node.
Barring a miracle, it's probably too late for this to make it in before D7 code freeze, but I suggest everyone take a look at #543294: Add status/promote/sticky to node_revisions table and #282122: D7UX: "Save draft" and "Publish" buttons on node forms. Together these will provide a huge leap in support for workflows and content moderation.
Comment #45
mradcliffeI don't think that is all necessary to allow enterprise cases such as yours to function. Contrib just needs more control over revisions.
When I think about complicated approval/reject workflows I see it as a 'need' / 'don't need' approach. That pretty much puts this into contrib, and I have a good picture on how to develop a module to do so. Basically, stemming from what I have already done in og_node_approval and possibly taking over the now defunct node_approval module to do so.
I do think we can push greater flexibility with the way that revisions are handled into Drupal 7 before the code freeze if there's some go-getter available in Paris to help out (I don't have the time nor the resources to be in Europe).
Edit: actually, RdeBoer puts it a bit more cleanly in http://drupal.org/node/282122#comment-1946138
Also, what is the status of #120967: Separate revisions from node.module, which hasn't been worked on since June. Are revisions going to be separated out from node.module or not? Anybody know who to contact on that? I'd hate for these two issues to be passively ignored amongst all the rest of what needs to get worked on before September 1st.
Comment #46
jstollerI still think what I've outlined here would benefit greatly from being in Core, however you are correct that much of it could also be developed in Contrib IF some key changes are implemented in Core to support this development.
Along those lines, I strongly encourage any developers who can to lend a hand in finishing #282122: D7UX: "Save draft" and "Publish" buttons on node forms before the code freeze. If implemented as is currently proposed, this should provide much of the missing Core support for workflows. The issue has been through a great deal of debate and received Dries' blessing to proceed. Now it just needs a little programming help with implementation.
Once that issue is committed, we can reassess the need for further changes to Core in order to support arbitrary state designations and more elaborate workflow scenarios.
Comment #47
xtfer commentedI've just made a suggestion at http://drupal.org/node/282122#comment-1958304 that might make this possible...
Comment #48
sunsubscribing
Comment #49
jstollerThere's a last ditch effort to provide basic support for revision states in the D7 database, thus permitting further development of these features in contrib moving forward. See #579654: Add "state" and "last_state" to node_revisions table. developer help is needed, so please lend a hand if you can.
Comment #50
cyberswat commentedsubscribe
Comment #51
jstollerHere are the slides I submitted on this topic for the Drupal Core Developer Summit at DrupalCon 2010.
Comment #52
aac commentedThanks Jstoller for sharing these slides!!
I liked you proposal for removing this issue. After adding this scheme, Drupal will become more feature rich CMS.
Comment #53
jstollerHere are my thoughts on this issue after last Saturday's Core Developer Summit. First, I think the vast majority of workflow management can happen in Contrib. For instance, other than two small tweaks I don't think we need to provide any GUI in Core. All of that can be developed in Contrib later. If years from now we find that a Contrib module has solved everyone's workflow problems and gained significant traction, then we can talk about baking it into Core. However, I remain convinced that the basic building blocks of workflow management need to be built into Core so that Contrib developers have something to hook into and build on top of. Workflow management and content moderation are such fundamental concepts in content management that it's shameful not to provide these tools within the Drupal framework.
So then, what should we implement?
As the title of this issue implies, at the most basic level we need to associate a state with every revision in the node_revision table. We should also make sure that all the metadata about a node is contained in node_revision. That table should gain created and changed fields for each revision. Then I think we need to add two more tables to the database: node_state and node_state_group. The former would define individual states which can be associated with nodes. The later would define groups that those states can be organized in, each representing a single workflow. Every state would belong to a group. Finally, the node_type table needs to include a workflow field which links each content type to a specific state group. Drupal Core could ship with one state group, called "default," containing two defined states, "unpublished" and "published."
As I see it, there would only be two small changes required to the GUI. First, on the node edit page, the "Published" check-box needs to be changed to a select menu, so it has the ability to support a multi-state workflow. Second, if there is more than one entry in node_state_group, then a select menu should appear under the Publishing Settings tab on the content type edit form, allowing users to pick a workflow for that content type.
So, what about the node table? In previous discussions there seemed to be a desire for node to still contain all the information in node_revision for the "most important" revision. That way people who don't want to use revisions on their site can ignore node_revision. I'm not completely sold on this approach, but I'll let others argue the pros and cons for now. In any case, if every state has a weight, then the node table can reference the revision with the lightest weight state (the most current one in that state, if there's more than one). Ultimately though, module developers should never be able to just assume that node is referring to the most current revision, or that the most current revision is the published revision, or that there aren't other important revisions in defined states.
Of course the real work will be in the API. There needs to be a way for people to create states and state groups, assign the former to the latter, query the state of a revision, find all revisions in a given state, etc... In the default configuration permissions can be pretty simple—you can either change the publication state of a node or you cant. However, the tools should be there for Contrib modules to offer more fine-grained permissions, defining who can initiate each possible state transition.
One of the most important parts of the API will be providing appropriate hooks and triggers for Contrib developers and users to tie into. Any time the state of a revision is changed, or a new revision is saved in a given state, it should be able to trigger actions and rules.
Note that in previous discussions of this topic, I proposed adding two state fileds to node_revision, state and last_state. My thinking was that you probably only want to have one published version of a node at any given time, but you might want to know which versions used to be published and last_state would maintain that information for you. However, after giving it more thought, I no longer believe this is necessary. The same functionality could be achieved with a single state field. You simply define "previously published" as a state, just like "published." Then, if you saved a new revision in the "published" state, that could trigger an action which changed the state of any older published revisions to "previously published". In fact, a well designed contrib workflow module could automatically create these "previously x" states every time you added a new workflow state, but use hook_form_alter() to hide them from the user. And anyone needing more detailed historical information could create a contrib module that logged every state change.
At the Core Developer Summit there was some talk of building RDF into any state system, so that, for instance, we can all agree on what "published" means. Admittedly I am a little fuzzy on RDF and its implications, but I would hesitate to place a rigid definition on any state in this context. For instance, "draft" may not mean the same thing to me in my workflow that it means to you in yours. In fact, I could have two different workflows, for different content types, which both contained "Draft" states, but the practical meaning of draft could be different in each. In any case, I would love to hear more about how RDF might figure into this, but at the moment I'm wondering if its implementation might be better left in contrib.
Comment #54
mdupontThanks jstoller for the detailed status update!
I definitely support that, we need a sane way to build workflows with revision-based states.
Comment #55
Crell commentedI am very much in favor of a more robust state mechanism for nodes in Drupal 8 core, so overall +1. However, I have to throw in three important wrenches:
1) There's more than just nodes to consider. Any sort of state system should support not just nodes but any entities. Not all entities are revisionable, but we do want to support entity state, not just node state.
2) State definitions will need to be exportable, probably along the same lines as image styles in D7 core. This should, hopefully, be fairly simple.
3) I have to throw in a link to an earlier proposal by chx that I think has a lot of merit: http://drupal4hu.com/node/233
Comment #56
jstoller@Crell
To be honest, I never considered adding states to other entities. I've always thought of states as primarily a tool for content moderation, which to me implies revisions. It's an interesting idea though. I suppose a user could go through multiple states on their way from registration to approval (or would that case just be handled by roles). Can you provide use cases for how states might be used with some of the non-revisionable entities in Drupal?
What if we used the Field API and "state" was essentially a predefined field which could be added to any entity? Would that work? I think it would address your first two points. Fields are revision aware, so it should work from that standpoint, but "state" would need to be a required field on every node in order to make it meaningful. This is essentially what we're doing internally at the California Science Center right now. We're building a custom module that stores state information in a CCK field. Our module has our workflow hard-wired into it, but the idea could be generalized.
The idea of always archiving and never deleting—as proposed in the article you linked to—is a good one, but I do think both options should be available to site builders. For my part, I always intended to build the "Archived" state into our workflow. Once a node has been approved, only a high-level system administrator can go in and delete it. Garbage collection does become an issue, but I figured we could build a module that did something like delete all revisions that are more than xx days old, older than the last published version and have never been in the "published" state themselves. That way we can get rid of old drafts that are taking up space, while still archiving previously published versions of a node. In any case, all of this can be handled in Contrib and is tangential to the issue at hand.
Comment #57
mradcliffeAwesome. Kind of wish you got selected on Saturday now. :(
If all editable data on a web site needed to be approved for security purposes, then it makes sense to be able to have states on entities other than a node entity. Profile/user entities would fit this process.
Ubercart right now uses "order" as an entity-like thing. If it were moved over to order you could manage order states via the above as well. This might cut down a lot of code in e-commerce suites for Drupal 8.
Comment #58
Crell commentedNodes are not the only revisionable entities we could have. I'm actually thinking as much about non-core entities like Commerce module, or site-specific entities. (I will likely make a bunch during D7 as part of my normal site design.) The better question, really, is why WOULDN'T we make states available to all entity types? Just because there's no immediate use case in core doesn't mean there aren't a hundred use cases in contrib, and not all of them would be revision-dependent. Don't think small. :-)
As for using Fields for it, that's a non-starter. For one, as you note that means we have a required field on everything. For another, I see state as more of a meta-data, like presence in a nodequeue or flag or workflow modules. Fields are really more for intrinsic data, that is inherent to what it means to "be" that entity, rather than extrinsic, which is about the entity's relationship to the rest of the world.
Fields are lousy for extrinsic data.
Comment #59
jstollerI've not often been accused of thinking too small! ;-) I've just been afraid of reaching too far and nothing getting implemented (as happened with D7), but I'm happy to ask for more.
First, if we had a State API that associated arbitrary state information with entities, what existing systems would it be replacing? What are all the current cases of entities that already have something akin to state data? For instance, nodes and comments can be published or unpublished. A user can be active or blocked. A file can be temporary or permanent. A block can be active or inactive. Am I missing anything?
In each of these cases, there is a status field in the entity's database table. Perhaps we should just replace status with state, allow it to contain an arbitrary integer value and require that every entity include this field. In the case of revisionable entities, we could require that the field be associated with the revisions. We could then change the node_state and node_state_group tables I proposed to simply state and state_group, allowing any state group to be associated with any entity. All of Drupal's existing status pairs could be included as default state groups. We could still leave all the GUI stuff for managing states to contrib, but if a module needed a non-standard state group, it could define it in code when it defined its entities.
Am I making any sense? Is this more along the lines of what you were thinking?
Comment #60
sunAll of that makes sense and is a nice summary of all states in core.
However, to come up with a solid States API for D8, as Crell suggests, for entities, not as field; we need to generalize entity tables, which hold exactly that meta information for each entity first.
Also, I'm not entirely sure whether Crell is fully right - I agree with his arguments :) but when going into extremes, à la "preview site" and "production site" with corresponding states, then a state would have to be attached to fields of an entity. The entity itself exists (or not), but the user's permissions and external factors may decide on which state/revision of an entity is actually displayed, for me, by default. (But not for you, or, but not on the production site.)
Comment #61
jstollerSun, can you expand on that some? I'm not entirely sure why states would be attached to the fields of an entity rather than the entity itself. That seems a little extreme at this point. What would a use case be?
Generally speaking, fields are part of the content of an entity, so I don't see why an individual field would go through states independent of its containing entity. The one pseudo exception to this is when the field is an entity in and of itself (i.e. file field, node reference, user reference, etc...). But in those special cases, the referenced entities would also have state information associated with them by virtue of being entities. In fact, I would say that if you have a field that needs states associated with it then your field probably should be a separate entity. When viewing an entity, specific fields may be displayed, or not, in one form or another, based on the state of the containing entity and the current context. Throwing field specific states into this equation just sounds like it will complicate matters. Am I missing something?
Comment #62
Crell commentedI'm not sure I see the use case for field-state either. If you need to version/track fields in an entity separately, they should be a separate entity.
Other use cases: States-in-core, if done right, become a replacement for the workflow module. And, maybe, flag and nodequeue. And once we have a real state system, we then have the ability to build real access control and approval workflow systems on top of that. And then there are ponies and unicorns. :-)
Comment #63
jstollerI like unicorns!
At this point I don't see States-in-core replacing Workflow completely. As much as I personally would love workflow management in Core out of the box, my sense is that that would be considered overreaching for a Core enhancement at this point. My goal is to get enough low-level functionality in Core that modules like Workflow can easily build on top of it. Workflow would provide a GUI for these underlying Core functions, adding mechanisms to define states and workflows, to manage permissions and allowed transitions, and bringing integration with other contrib modules, like Rules. My hope is that if this low-level State API is in Core, it will promote greater compatibility between Contrib modules when it comes to workflow and allow for a greater depth of development in this area.
John VanDyk, Workflow's maintainer, was at the Core Developers Summit and made some interesting comments relating to this topic (some of which I didn't completely understand). I would love to get his input on this issue here.
I also didn't see this replacing Flag or Nodequeue. To do that you would need to allow for a single version of a single entity to be in multiple states from multiple state groups simultaneously. That sounds intriguing, but it seems way more complex than the original intent of this issue and I'm afraid we'd just be talking ourselves out of ever implementing this. If we went this root, then we'd essentially be creating a Flag API in Core. It would have to support both binary and multi-value flags, support an arbitrary number of flags per entity and associate these flags with the revisions of revisionable entities. We'd basically be creating the meta-data equivalent of the Field API. Actually, this isn't an entirely bad idea. It would handle things like the "sticky" and "promote to front" fields, as well as any number of site-specific flags. However, this would still have one of the same issues you brought up with the idea of using Fields to store state information—we would have a required state flag on everything? Is that requirement more palatable here than it was with Fields?
Comment #64
Crell commentedYou're catching the bug. :-)
I agree with you that core should just be the API. My point is that once we have a consistent, clean entity state system it becomes easy for other modules like workflow to extend it in new and exciting ways. We want to be an enabler.
In the very abstract, what I see is a "state group", which then has one or more states. A state group can be associated with one or more entity bundles (subtypes, like node types). An entity of that type is then always in one and only one state within that state group, but any state group can have an arbitrary number of states. If a bundle supports revisions, then the states are all revision-bound. Thus "published/unpublished" is a state group, "promoted/not promoted" is a state group, "flagged/not flagged" is a state group, "active/blocked/pending" is a state group, "needs work/needs review/RTBC" is a stage group, "needs editor approval/needs management approval/published" is a stage group, etc.
OK, it probably wouldn't replace flag then as it wouldn't be per-user states. But it still covers a lot of ground, and with good views and actions/rules integration gives us a ton of potential functionality. It also removes a lot of silly special cases for published, sticky, etc.
Perhaps that should start as a D7 contrib module and then migrate into core for D8? That gives it time to mature a bit and get the integration points working.
Comment #65
jstoller@Crell
It sounds like your describing the same thing I was saying for nodes in #54 and generalized for entities in #59. Yes?
My fear with trying to develop this in Contrib is that it seems like doing this right requires a huge amount of integration into Core systems, which is basically impossible to get in a Contrib module. I mean, Revision Moderation is a great module, but it doesn't do me any good since Workflow doesn't recognize it. No Contrib module can reasonably expect every other Contrib module to recognize its existence. And what's the philosophy when it comes to Contrib modules modifying Core tables in the database?
Comment #66
Crell commentedVery close, yes. The difference is from the sound of it you're talking about a single field on the entity table itself. That makes supporting multiple state groups difficult as you need to screw with the table every time you add a state group. I actually see it as a separate table or tables, as that is more extensible. There are performance concerns there, though. I'm not sure where the trade off would be there.
However, that's why I think a contrib module deliberately aimed at core inclusion later would be a good start. There's a lot of stuff we'd need to work out, and contrib can rapidly iterate faster than core can. True, it wouldn't get us the ability to replace node published status in core, but then that isn't going to happen until Drupal 8 anyway. I'd hope it's a module that could get ported into core during the D8 cycle after evolving a few months in D7 contrib land. There's actually a couple of modules that I hope that happens with. (If we can keep the API consistent, that would even make the D7->D8 upgrade easier for modules already using whatever gets developed.)
Comment #67
jstollerHow so? Why would adding a state group effect any of the entity records? As I envisioned it, we would have two new tables in the database that looked something like this:
name <-- The human readable name of this state group
description <-- A description of this state group for the admin page
module <-- The module that implements this state group
sid <-- The primary identifier for a state
name <-- The human readable name of this state
description <-- A description of this state for the admin page
weight <-- The weight of this state in lists
status <-- 0=unpublished; 1=published; -1=archived;
Out of the box these tables might look something like this:
state_group table:
state table:
Each instance of an entity would have a single field in its table that referenced the sid of that entity's current state, and each type of entity would reference the sgid of the state group which governed it. None of these IDs would change when new state groups were added.
The most straight forward implementation of this would be for nodes. The node_type table would have a state_group field, allowing each content type to use a different workflow. And the node_revision table would include a state field, allowing each revision of a node to be in a different state.
The other entities are a little trickier. It makes sense that there would be one state group for all users on a site, but can the same be said for blocks? Should a comment's state group be tied to the content type of the node it's attached to, or should there be one state group designated for all comments site wide? Should a file's state group be tied to the field through which it was uploaded? This could get pretty complicated if we let it.
I'm still leery about the effectiveness of developing this in Contrib if you can't touch Core tables, but seeing as I'm not much of a developer, I'm happy to leave that in your capable hands. ;-) I do think that any module we develop will need to hook into the node access process enough to enable content moderation, along the lines of Revision Moderation.
Comment #68
Crell commentedSee, that's where I think we're still not on the same page. What happens if, from the UI, I create a new state group and want to associate it with nodes of a given type? I don't want to have to add more fields to the node_revision table, from core or contrib. That means entity states are stored in a separate table anyway.
As for node access integration, that's probably an add-on module that changes node access based on a state change; basically what workflow/actions do now.
Comment #69
jstollerI still don't understand the problem. If you create a new state group, with a new list of states, then they'll be added to the state_group and state tables. If you want to associate that state group with nodes of a given type, then you go to the settings page for that content type, where you will find a "Workflow" drop down selector. If you select your new state group from the list, then the state_group field in the node_type table will be updated for that content type, referencing the sgid of your state group. From then on, any nodes of that type you create will be tagged with the sid of one of your states from that state group. There is a single state field in node_revision that holds this sid. We never add more fields to the table. Each content type must be associated with one—and only one—state group. And each node revision must be associated with one—and only one—state. The only problem comes when someone wants to change the state group for a content type that already has nodes associated with it, but that's going to be an issue no matter how we store the data.
Are you thinking about associating multiple state groups with a single entity, or allowing one version of a node to be in more than one state at the same time? That's the only situation I can think of where you'd want to add more fields to the tables. I'm also afraid it would add way more complexity than necessary.
Comment #70
Crell commentedAh! OK, that's where we're talking past each other. Yes, I am talking about a given bundle supporting more than one state group at the same time. There's absolutely use cases where we would want to support nodes that have one state in the published/unpublished state group and another state in the needs work/needs review/RTBC state group, for instance. Saying that a given bundle can only use one state group at a time seems very over-limiting to me.
I think we're both in agreement that within a given state group, states are mutually exclusive. (Vis, a bundle cannot be both published and unpublished at the same time.)
Comment #71
jstollerI've been giving this a lot of thought. At first I thought it was a great idea and I can certainly see potential uses for multiple state groups on a single entity. But I also see the potential complexity that might introduce and I want to make sure we don't bite off more than we can chew for D8, since the fact we missed D7 is already depressing me.
Lets hold off on the question of database structure for the time being and just assume we have a way of assigning multiple workflows to each entity and allowing them to be in several states simultaneously. My first question then is how does Drupal know what the different states mean? How does it know when something is published, for instance? If we have a single workflow for a node, then we can tell Drupal that states 1, 2 and 3 should be considered unpublished, states 4 and 5 should be considered published and state 6 is archived. Easy! But if we superimpose a second or third workflow on top of the first, then how do they interact? It could be something like a node is published if it's in state 3 or 4 from workflow 1, or state 5, but only if it's also in state 1 from workflow 2, except when it's in state 6 from workflow 3, etc... This seems like it would involve a much more intricate rules engine to manage. And then there's compatibility with contrib modules to consider. How do they know how they should interact with an entity that's governed by five overlapping workflows?
When I talk about states in the context of this issue, I'm really talking specifically about publication workflow states. And it seems to me that an entity can only have one publication workflow. Each node will have one path it takes from being created, to being published, to being archived or deleted. A site I am working on now has a six state publication workflow, with Draft, Review, Pending Approval, Approved, Published and Archived states. Nodes may skip a step or two sometimes, or loop back to earlier states, but each node will move back and forth along this line over the course of its lifetime. Where a node is within this sequence determines who can view it, who can edit it, and what happens when such events occur. Looking at the example you gave, the "published/unpublished" state group is the publication workflow. The "needs work/needs review/RTBC" state group is meta-data about the node, and it is made up of states, but it's not part of the node's publication workflow.
I started thinking, maybe we need a Meta-data API to handle this sort of thing. But the more I thought about it, the more blurry the line between data and meta-data seemed to me. I felt like my Meta-data API would effectively be a duplicate of the Field API. So then I ended up at my original question of why can't we use fields to store this meta-data? How would you draw the line between intrinsic and extrinsic data and how is it that fields are "lousy for extrinsic data?" For instance, it seems like your "needs work/needs review/RTBC" states could easily and effectively be tracked in a field.
Publication states seem different from other state data, if for no other reason than they are required for every entity and they are linked to content access at a fundamental level. Is there something unique about other kinds of state groups—including binary flags, I suppose—which make them stand out as needing special treatment that the Field API just can't support? Are there small changes which could be made to Field API to allow it to support such data, or do we need a different system to handle it? If so, then should publication states be lumped in with this new system, or should they be handled separately? If publication states are lumped in with all the other meta-data, then you need a way to ensure that every entity has one—and only one—publication workflow associated with it.
My original proposal was just to address publication workflows for nodes, which I thought would be relatively straight forward to implement. Extending that to address all entities seems simple enough, though it does bring up a few more complications. Extending that further to allow multiple simultaneous workflows brings on a pile of complications. I think we should discuss it, but I don't want to loose sight of the number one priority. And if we need to sacrifice the awesome to implement the very cool, then we should be ready and willing to pull the trigger. I'd like to make sure we stay somewhat focused on the ultimate goals and priorities for this issue, so here they are as I see them:
Anything else is icing on the cake.
Comment #72
Crell commentedHm. I think I'm thinking more complex than you in some areas and you're thinking more complex than me in others. Exciting! :-)
In no special order:
- Fields are very "heavy" conceptually. They have lots of moving parts. They load "as part of" the entity. They can have multiple internal components. They can be multi-value. An entity can have its base data and its field scattered over multiple storage systems on different servers. Translation makes the API consist mostly of horribly obtuse array dereferencing. There's a *lot* going on there, most of which is unnecessary complexity in this case.
- I believe there is value in a conceptual distinction between intrinsic and extrensic data. Yes, that's not always an immediately obvious line, but there is still value in thinking of "a thing" and "how we organize our things".
- As to how different entity states interact to form publication state, well, they don't. Why would they need to? A state, as I see it, is a value within a fixed set of exclusive options. They needn't interact with each other.
- Once you introduce more than two states in the "publication status" state group, you've already added a great deal of complexity. Suppose you have "needs editor review, needs senior editor review, rejected, approved, archived". That's a perfectly reasonable state combination to support, and then build a UI on top of to allow for complex editorial control. And of course those are per-revision, because we want to allow one revision to be "live" while a new draft bounces around through the editorial maze.
Which of those states is the "live" one, though? Which do we show to anonymous users? Do we show the same state by default to all users?
1) We could hard code the state string of "published" as the "live" version, kthxbye. I hate hard coding. :-) It also means that state is fixed, and a given site can't use another name for it. (That could be a good thing, perhaps; I am not sure.)
2) We could impose no fixed "live" version and make the resolution logic for which one is default, or which ones are publicly accessible, pluggable. That gets very weird, though, as it allows you to configure all sorts of bizarre logic. If you configure two states as "live", and an anonymous user comes to the site, which do they get? Even if it's only one, then you have to have a way of defining a "key" state within a state group that means "anonymously accessible". That's what we would not be hard coding, which means we need a way of defining it.
And that's still with just a single state group! :-) Now, suppose we also have CNR/CNW/RTBC as another state group. Or a "not spam/probably spam" state group that is triggered by some crowd-sourced interaction. How does that impact publication status? It doesn't. The values in one state group have no impact on those in another, unless you respond to a state change in one group by changing state in another group. So having multiple state groups doesn't, inherently, add much more complexity beyond what having a single n-value state group does.
Am I making any sense at all here? :-)
Comment #73
catchWe are not taking the ability to do "SELECT nid FROM {node} WHERE status = 1 ORDER BY created DESC" out of core in Drupal 8 or possibly ever. That is precisely the kind of over-normalization which will make it impossible to run even smallish sites without mongodb or materialzed_views, since then even the most basic node query will never, ever use an index. So no, this doesn't make any sense, whatsoever, if people actually want to run sites on Drupal 8 that don't fall over with more than three nodes on them.
There needs to be some kind of on/off switch, on the base table to say "is this visible in a publicly viewable listing query". Node access breaks that contract, but not every site runs node access (and even with node access, there's a potential approach with lossy pagers which could avoid joining on every query, and node access is different to 'states' anyway).
If you have a publishing workflow, then you have a process which eventually leads to the article being "visible in a publicly viewable listing query", hence, as I've said too many times on this issue, there is a difference between the workflow state of the node, and whether it's draft, published, unpublished or deleted (since we may want to make deletion a subset of 'archived' in D8, something might be deleted but not yet removed from the database). So the way I'd like to see this handled, if at all in core, is more along the lines of flag actions - you track the state of a node somewhere, and when a certain combination of conditions are met, you flag its status in the node table.
Having typed that rant, there is another option. I'm intending to redo revisions in Drupal 8 so that every entity has revisions by default. Additionally, if we take {node} and {node_revision}, these tables would be self-sufficient - I can delete a row from {node} (and fields_current), and then recreate it again from {node_revision}, instead of the mix of properties we have now (what's the difference between {node}.uid and {node_revision}.uid - answer that question and discover that node revisions are completely broken as they are now).
This would allow 'drafts' and 'unpublished' and 'deleted' entities - anything which is $not_intended_for_general_consumption to be stored only in the node_revisions table, then the simple query above becomes more simple instead of less - ""SELECT nid FROM {node} ORDER BY created DESC" - however that wouldn't allow to do things like showing comments which are still in moderation in context to the poster, or showing people a list of all their nodes whether published or unpublished, so I imagine we won't be able to do that except for perhaps draft and deleted.
Comment #74
Crell commentedcatch: Hm. OK, so if we use {node} (and {users}? Hm...) as just a denormalization table for "currently live version", how would you implement the resolution logic to decide which revision is the currently live version?
And would that get easier or harder if we implemented chx's suggestion that I linked to several comments up about "never update, just insert a new revision" (with then potentially a stale-revision-cleaning routine)? (I actually rather like that concept, and I think it could simplify a lot of things. It also looks cooler to the corporate workflow and big-brother tracking types.)
Comment #75
catchSo I completely agree with "always insert a new revision + garbage collection if you want it", not for this issue, but I also want to be able to store nodes and revisions in different storage backends (nodes in mongo, node revisions in cassandra) - cassandra is fast enough for inserts we could do autosave using revisions for thousands of concurrent users and barely notice apparently. I think for drafts and deleted, they might not need a record in the node table - you work on something as a draft, save it properly to create a record in the node table, then it either gets published, or stays unpublished and goes into a publishing workflow. When you delete it, revisions are kept until garbage collection runs, so you could potentially implement undo.
Thinking about it more, I don't think it's possible to take unpublished out of the node table though - we need to be able to do things like show unpublished comments in context (unless we dropped that feature permanently), so WHERE status = 1 will likely need to stay.
By the way I'm not opposed to moving 'sticky' and 'moderated' out of the node table, where they're used in core, those modules either do or should implement denormalized tables anyway (forum for example), also they're c.2001-ish concepts which I don't really think apply any more to many sites, so I'd be happier removing them from the node module even if we had to keep something like that in forum module. However "visible to unauthenticated users" isn't out of date yet by a very long way, and very basic queries like the front page one need to not die when using SQL entity storage - which is currently every site, and will still be 95% when D8 is released.
The current resolution logic for which revision is the currently live version, is that vid = :current_vid and whichever field values are in fields current. I think we'll see less, possibly zerp, modules managing their own data tracking vid in D7, so it could eventually be "whatever's in the {entity_current} and {fields_current} tables and that's it (and if you still want to manage your own data you have to mimic that setup). Then there'd be a copy of everything in the respective revision tables too. When you want to replace that, you update those tables with whatever values you need, which would also create a new revision.
So, if you had a newer revision which was being worked on, but not published, it'd get an entry in {node_revision} and an entry in {$field_revision}, but nothing happens to {node} and {$field} until the revision is published. What this is likely going to end up with is a much, much stronger separation between entities and entity revisions - so that you can work with both fairly independently without having to worry too much about the other.
Comment #76
Crell commentedHm. I think I followed that. :-) So you're saying that "published", meaning "this is the live for reals version to be using", remains a one-off binary flag. But we build a state system beside it (which can be as normalized as we need) and then allow triggering of toggling the published flag by the states.
So in the above example, we'd have a state group of "needs editor review, needs senior editor review, approved, archived". Then a trigger (or something) is configured so that when a revision is saved with a state of "approved", it gets copied to {node} with a published flag of 1 and all other revisions of that node are either removed or set to published=0.
And published is then the only "magic quasi-state" we deal with. The rest move out to more generic systems, as being discussed in this thread.
Am I following that correctly?
Comment #77
catchYeah that's what I was trying to say in #73:
Which I think is the same thing you described. We have three 'entity states' (draft, current, archived) which are completely canonical - create, read, archive vs. CRUD, not the same as workflow states at all, and possibly closely linked to overall storage (like keeping both draft and archived out of the node table). If we need both publically viewable and current content to be listed in the same place, then we have an additional 'published' flag which can be triggered any way you like (i.e. not just by a checkbox on the node form). Nodes and comments are often published/unpublished, users are blocked/unblocked, this seems pretty necessary.
Additional 'flags' like sticky, promoted, abuse etc. I think need a different system again - similar concepts/flexibility to flag/nodequeue etc. but with denormalization of some kind baked in or easy to swap in. Whether workflow systems are built on top of or parallel to those I'm less sure of.
Comment #78
Crell commentedWouldn't the implication of that be that if you wanted to do a more complex node-access-based listing of some kind, you'd have to change your approach entirely and pull from {node_revisions} instead of {node}? That means you couldn't have queries coded against {node}, or hook_query_node_access_alter() would have to swap out all instances of {node} for {node_revisions}.
I also disagree with "need a different system again". We don't want 3 separate state-ish workflow-ish systems. We have that now. It's a mess. We want one that works properly, and then possibly some special denormalized magic states (published, active user, etc.).
Comment #79
catchIf you want to do node access, why couldn't you do node access the same as now? That doesn't depend on funky revisions stuff. You can't do node access listings on revisions now either. So I'm not really sure what that means?
I'm fine with workflow and 'flags' being similar on an api level, as long as the api is actually suitable for both.
Comment #80
jstoller@catch: I think what you're calling "entity states" are the same as what I was referring to with {state}.status in #67. I defined three of these super states: Unpublished, Published and Archived. In this context, "Unpublished" is any content that is in process, but is not visible to the general public. This could include initial draft content, content undergoing editorial review, or even approved content that has been scheduled for publication but has not yet been published. "Published" content, as you might expect, is any content that is visible to the general public. The "Archived" state is for content that you want to keep in the database, but you also want to keep out of the way. It should not show up in any listing query, unless it is specifically looked for.
Just to keep things clear, I'll refer to these "entity states" as the entity's status, since (in most cases) this is closely related to the current status field in the entity tables. Of course we are now talking about each entity's status having at least three possible values, instead of the two currently supported.
I had always seen my publication workflow as sitting on top of this more low-level state system. I could see several states that would all have node status of Unpublished, others that would have a node status of Published, and I could even see several workflow states that all corresponded to the Archived node status. So perhaps the key to allowing my publication workflow is not so much pulling workflow out of contrib and into {node_revision}, but rather its expanding a bit on this concept of entity status.
I'm just thinking aloud here, but what if we had four different node tables: {node}, {node_revision}, {node_published} and {node_current}.
{node} would contain only that information which always applies to the entire node. Right now I foresee this including nid, type, language, created, changed, comment, tnid and translate.
{node_revision} would be a slightly expanded version of the current table of that name, containing any node data that could potentially vary from one version to the next. For instance, timestamp should be replaced by separate created and changed fields.
{node_published} and {node_current} would be denormalization tables for the two most basic views of node data. They would be similar to today's {node} table in structure. Their content could be completely rebuilt from scratch using the new {node} and {node_revision} tables. {node_published} would reference the most current version of each node with a "Published" status, unless there is a more current revision with an "Archived" status. In the later case, the node would be omitted from the table. {node_current}, on the other hand, would reference the most current version of each node (Published or Unpublished), unless that version is "Archived"—again omitting archived nodes from the table.
Here "published" and "current" could be thought of as two standard entity display modes for nodes. If I'm viewing the site in the "published" mode, then I'm seeing only the publicly visible content. If I'm viewing the site in the "current" display mode, then I'm seeing all the latest non-archived content, even if it's still unpublished. This goes way beyond just seeing the unpublished comments on a node. I could now see my entire site as if the current revisions of all my content were published, which is just too awesome for words. It's like a virtual staging site for content!
This same concept could be expanded to all entities—perhaps changing "published" to "active". For instance, we could have {users}, {users_revision}, {users_active} and {users_current}, or {comment}, {comment_revision}, {comment_published} and {comment_current}.
One question that comes to mind is, are three entity status values enough? Does Unpublished, Published and Archived cover all the use cases we can think of, or do we need more? For that matter, should there be a method in the API for contrib modules to define more status values? Should each entity have a different set of status values, or should there just be one set for all entities site wide?
Another question is about these entity display modes. Is there any reason we shouldn't allow modules to define additional display modes, other than the two defaults I've outlined here? For instance, maybe I want something similar to {node_current}, but I only want it to display unpublished content if it has some flag set on it, thus filtering out initial drafts which the author isn't ready to release.
My publication workflow would then sit on top of the whole entity status/entity display system. My workflow states could be stored in a field, or in a field-like construct which was optimized for this sort of meta-data. When a node was saved, my workflow module could either change the state of the current revision, or create a new revision in the given state, depending on what rules I'd set up. It would also set the node status in {node_revision} of whatever revision it was saving, which would trigger {node_current} to be updated, as well as possibly {node_published} and any other node entity displays which had been defined.
I hope I'm making some semblance of sense with all this. I think I'm heading toward something which elevates revisions to their proper place of importance, yet includes adequate denormalization to support simple sites that don't have five DB servers. It permits advanced workflow and content moderation modules to live comfortably in contrib, without needing grotesque workarounds and/or creating massive compatibility issues with every other module.
Comment #81
texas_tater+1 subscribing
Comment #82
johnpitcairn commentedWow. Subscribing.
Comment #83
bellHead commentedSubscribing.
Comment #84
kiphaas7 commentedsub
Comment #85
davepoon commentedSubscribing. It's so nice to implement this feature in Drupal.
Comment #86
benanderson commentedsubscribing
Comment #87
jstollerI just marked #282122: D7UX: "Save draft" and "Publish" buttons on node forms as a duplicate of this issue, in an effort to consolidate future conversation, but there is some good historical information there for anyone who's interested.
Comment #88
AdrianB commentedSubscribing.
Comment #89
bforchhammer commentedsubscribing
Comment #90
florisg commentedmake revision an entity :)
so we can make revisions on any other entity.
Comment #91
agentrickardSubscribing, but also noting that we'll discuss this during a core conversation about editorial workflow at DrupalCON London.
Comment #92
jstollerI'm glad this has made it to a Core Conversation, but I wish I could be there. Will it be recorded? Streamed? Is there any way to participate remotely?
Comment #93
agentrickardNo participation AFAIK, though you might hang out in #drupalcon or #drupal-contribute and ask people. I don't think these sessions are being streamed.
Comment #94
jstollerCan someone who was able to attend the Core Conversation in London please summarize the discussion here, so that we might continue the conversation? Was there any consensus on these issues?
Comment #95
agentrickardNo consensus, because we were very short on time and had no discussions.
Comment #96
jstollerSorry to hear it. Shall we jump-start this conversation again?
Anyone have any thoughts on where the discussion was headed, ending with my post in #80? I know there have been more than a few changes to Core since May.
Comment #97
agentrickardMy "official" recommendation at DrupalCON was as follows:
* Add a third core state, something like, "draft", to allow contrib to leverage all kinds of cool features on entities. This "draft" state would allow a "published" revision to stay live while the new draft was worked.
* Unify the draft/published/unpublished concept for all entity types.
But we haven't gone very deep into that. I am actually against making radical changes. I'd like to see an incremental improvement that we can test in the next cycle.
Comment #98
mradcliffeWouldn't this all be solved by providing an option to not automatically switch a node to the latest revision?
This is how revisioning does it iirc, which has to go through a bunch of round about ways to set the real revision. If this were solved by core, then the work flow parts of this can be solved by contrib. Contrib can handle sunsetting, approval voting, etc... via any of the modules available (revisioning, maestro, etc...) while core can handle the simple use case.
That is still my recommendation.
edit: I forgot to mention the issue with localization.
...Another task which is related to this is if you allow a user to draft content, but not have it visible, then you would need a way for the user to see that draft content anywhere it shows up on the site. This would be particularly frustrating to not have this for a user who publishes content that is a part of a view, panel, context, etc...
Comment #99
jstoller@agentrickard:
That's how I felt three and a half years ago, when I posted this issue, but now I think I'm ready for a little radical change. After all, we've got a good two years to increment and test while D8 is in development. The thought that, in 2013, my favorite CMS still won't be able to do something as fundamental as moderate content, seems unfathomable. I would like to see Drupal take a leap in this arena and build something fabulous.
When you get down to it, workflow issues are so core to content management, how could we not make them a priority? Sometimes I feel like Drupal's current lack of content moderation and workflow support has caused much of the community to turn a blind eye to the importance of those features. But they are important. Very important. It is my ardent hope that D8 will be the release that finally allows even the most basic website to implement multi-state workflows and to stage pending content, without need for multiple Drupal installations or complicated domain access configurations. I know I've never worked on a single website where I didn't want, at a minimum, "save as draft" functionality. And in all but the smallest websites I would probable throw in a couple states on top of that.
@mradcliffe:
That's part of it, but I think the solution needs to be a little more involved than that. There needs to be a shift in how revisions are treated and what it means for something to be published or unpublished.
That's partly what I mean by staging content, and is basically what I was after with the whole "display modes" thing in #80. It gets complicated though, because to truly stage content in this way, it isn't just about the nodes. You're saying, "show me what the website would look like if all the currently pending content were suddenly published." That means you also need to think about the menu system, path aliases, etc... Of course, if everything were revisionable and there were certain set display modes, or contexts, which everything knew how to respond to, then maybe we'd have something.
Comment #100
mradcliffeI think we should start a Node Publishing initiative as this is going to be more than just one task called "support revisions in different states". And then maybe by the next core conversation in Denver we have some requirements/goals/objectives that can be turned into development tasks for D8.
@jstoller
I think that this can be done by doing what revisioning does on hook_node_load, and load the appropriate revision based off of some widget a user can set a revision (or preferably a date). I really think that could be something contrib could handle as well.
edit: why the heck didn't i catch those tags. Whoops.
Comment #101
johnpitcairn commentedMost of my clients would just want to see the preview as it would be as if the node they are currently previewing was published. Not all the currently pending content, and not even all their currently pending content.
But I have other clients who are using Revisioning in conjunction with a scheduled publishing mechanism (via Rules at present), and those clients would dearly love to be able to step forward/backward through the future publishing schedule and see the entire site as it will be at each step of the schedule.
Having hooks in core available to implement this sort of thing would be great, though I appreciate roll forward/back is probably a whole other discussion.
Comment #102
jstoller@mradcliffe:
Once you start thinking about the details of accurately staging an unpublished node, let alone an entire website staging environment, it gets way more complicated then a just hook_node_load(). A node's reach goes far beyond the node itself. When I edit a node, I can change its position in the menu system, which in turn can change its path alias, but neither of those things can change for the published version of the node until my edits are approved. That means a single node would have to appear at one place in the site hierarchy when viewed by the public, but in an entirely different place when it's unpublished draft is viewed. And this is important, when you consider that a node's menu location or path can be used to set contexts, which will determine many other things about how that node is displayed, like what blocks are in what regions. That context must be preserved and displayed properly if you are going to have a true preview of how the node will look if published.
Comment #103
colanSubscribing.
Comment #104
colanActually, I don't see a patch file here.
Comment #105
moshe weitzman commentedcatch just linked to #1082292: Clean up/refactor revisions. that might be a prerequisite for this work given our current entity push.
Comment #106
agentrickardHere's a patch I just worked on after a discussion at DrupalCON Denver. It tries to keep things simple, introducing the following changes:
* An update hook a that adds {node_revision}.live column, which is a boolean indicating the live revision.
* A form element and node property $node->is_live, which affects how data is saved. This form element is #states sensitive and defaults to TRUE.
* Note that node_access rules are only generated from the live revision. This is by design.
Things still todo:
* Test that the field handling trick actually works, especially with files. Potentially clean this code up.
* Write tests.
* Document how modules that set node properties (not fields) might need to interact with the new system.
* Improve the UI through a follow-up patch series that allows branch editing off of a revision.
* Improve node validate in a follow-up patch that changes the concurrent editing behavior to spawn a new, not-live revision in the case of a save conflict.
Comment #107
agentrickardScreen shot of the UI change.
Comment #108
mradcliffeYes, I like this approach as well.
Comment #109
moshe weitzman commentedThe architecture of Field API insists that the 'live' revision is in separate tables from all other revisions. This is a performance optimization. You are indeed going to have to dig in there. Have fun!
We might consider unifying the terminology for published (the entity) and live (the revision).
Comment #110
agentrickard@moshe
The patch accounts for that. See this part:
What it may not account for is non-field node properties.
Comment #111
stevectorThanks agentrickard for getting this started. Robeano and I gave a core conversation in Denver about the need for this distinction. http://denver2012.drupal.org/content/i-just-want-edit-node
I agree that non-revisionable properties will need to adjust how they interact with nodes. For instance, path module should check the 'is_live' property before actually changing it's table. We may also then need to separate what path module thinks the alias for a node revision should be from what path module puts in the {url_alias} table. That could be done with a revisionable field whose value only goes in {url_alias} when the revision goes live. I think that can be worked out in follow up issues.
Also this patch will need refactoring if the change to classed objects gets in first: #1361234: Make the node entity a classed object
Comment #112
aspilicious commentedWoow, missed this issue. But I want to point out something. The goal for drupal 8 is to have revision support for *entities* not only for nodes. So when #1361234: Make the node entity a classed object I would maybe try to make this revision (rewrite) work for every entity.
Maybe I missed something (I'm not going to read 111 comments) but I wanted to write down my opinion.
Comment #113
agentrickard@aspilicious
Let us please define the behavior we want. Then implement it. Then abstract it to entities.
Otherwise, this will never get done.
Comment #114
aspilicious commentedOk sound good. Just wanted to mention it :)
Comment #115
agentrickardI added that as a follow-up task in the issue summary.
Comment #116
jstollerDoes making a revision "live" remove the live tag from previous revisions? Or are all revisions that have been live at some point still marked as live, with the {node} table reflecting the most recent live revision?
Comment #117
agentrickardRemove.
EDIT: I would think that some form of audit trail for "when did the live revision change" would be either a follow-up task or a contrib problem.
Comment #117.0
agentrickardAdds an issue summary
Comment #118
yoroy commentedSeeing a screenshot posted in #107, I wonder if 'live' means the same as 'published'? If so, we should use published here. It seems Moshe suggests the same in #109. I realise there's a difference between the entity itself and its revision, but making that distinction here seems prone to confuse instead of clarify.
Exciting to see this issue progressing!
Comment #119
yoroy commentedToo funky a file name in the previous attachment:
Comment #120
agentrickard"Live" does _not_ mean "published". The "published" option is part of the "publishing options" tab.
That grouping may need to be fixed in a follow-up, but note that the Revisions tab only appears if revisions are enabled.
Perhaps we should call it the "active" revision or something similar. The effect of "live" is similar to Git or SVN: it sets the current revision as the head or trunk of the revision tree, so that all subsequent actions (view and edit, primarily) act on that revision.
Comment #121
yoroy commentedThanks for clarifying. Seems to me 'active' is much better then, less looking like a synonym of 'published'.
Regrouping vtabs options will happen as (follow up) part of the new create content page design, we'll get to that eventually.
I'm sure there are more important parts of this patch that need review still :)
Comment #122
catchI'm not sure what the value of having an actual 'active' column in the revisions table is, at least with the current patch - everything still relies on {node}.vid = {node_revision}.vid and switching the active flag on the {node_revision} table won't change anything?
Comment #123
Crell commentedcatch: See the link in #111. Right now the tight coupling between "this node is published" and "and this is the version of it that you should be showing to random site visitors" makes doing any sort of interesting editorial workflow way uglier than it has any right to be. The idea is to make it possible to save a new revision without also making that new revision also the version that random visitors see. Basically, this lets Workbench rip out a lot of yuck. :-)
Comment #124
catch@Crell, I understand that's what the patch does, but your comment doesn't go any way to explaining why there's an 'active' column added to the {node_revision} table when no code in the patch actually checks the value of that column.
The 'active revision' in this patch is based on the vid stored in the {node} table, same as now - which is fine, it's more or less what revision_moderation does conceptually, but for now the extra column is just duplicating that information rather than replacing it.
Comment #125
agentrickard@catch
The intent was to allow queries for revision data straight against {node_revision} without a JOIN. But I can remove it if it is a blocker.
Comment #126
stevector#1361234: Make the node entity a classed object is currently RTBC and should go in before this patch. This patch, along with with nearly every other patch touching the node system, will need a reroll when the switch to a classed object happens.
Comment #127
jstollerRe #125: It does seem like having the 'active' column in {node_revision} could be quite useful when you start thinking about possible views and such. Is there a compelling reason not to include it?
Comment #128
stevectorHere's an updated version.
The main differences in this patch compared to the last:
Comment #130
stevectorSome of these failures might be related to #1550454: Regression: Following taxonomy entity conversion, Taxonomy EFQ causes warnings and notices
Comment #131
videographics commentedCan someone give me a sense of what's happening at the workflow/state API level? I can't tell if people are working on an API for D8 that would apply to all entities, or if this current effort is limited the implementation of a specific workflow for the publishing and revision of nodes.
Comment #132
indytechcook commentedThe title is a little misleading. This patch really just adds a live flag on the node entity and handling of not having the latest revision be the live revision.
This does not do a full API around states or allow for any state except for published and unpublished. I do think a better way to handle states is necessary but out of scope for this patch.
Comment #133
agentrickardBut having the live flag will allow that better state handling. Right now, it's very difficult.
Comment #134
videographics commentedgot it. thx.
Comment #135
videographics commentedindytechcook, can you tell me if you know of anywhere a core workflow API issue IS being looked at?
Comment #136
indytechcook commented@videographics not that I know of but it's something i will be looking at in the upcoming months.
Comment #137
jstollerIt has been well over four years since I first posted this issue and this is the closest we've come to having anything committed to core. So, first and foremost, I don't want to do anything which might jeopardize that progress. I recognize that Core support for revision moderation is a critical first step for any workflow implementation, so I am eager to pass this hurdle.
That said, once this patch has been committed, it is my sincerest hope that we can return this conversation to discussing a more full-featured system for supporting arbitrary content states. I have not forgotten the dream of a workflow API in Core and I still believe we can do more in D8 before it launches. I just don't want to see D8 become another D7, where there is no movement at all in this area.
Comment #138
agentrickard@jstoller I agree with that sentiment.
Comment #139
videographics commentedI'm with you on all of those last three comments. Please keep me in the loop (if you don't see me involved) and hopefully I can be of some help...
I know especially those in the staging and moderation space understand that published and unpublished are just two of many states entities (and revisions) can be in. What I want it for everyone else to start thinking about how far we've moved beyond the blog and even the publishing site. Our new entity filled reality is filled with products to be built and sold, people to be hired, films to be produced, etc. and all of these entities need to exist in states other than published and unpublished.
I do hope we can make this happen. Leaving the workflow/state APIs in contrib means continuing to manage extra layers of permissions and all kinds of other unnecessary confusion for something that is so essential to managing content. I just hope there's a enough general awareness of all this so it gets the appropriate attention. I think having an integrated workflow/state API is one of the best ways we can distinguish Drupal as a platform that can manage as well as publish content.
Comment #140
stevectorHere's an updated patch. The previous one no longer applied. I've also moved the isLive property back the the Node class. This might get tests to pass.
Videographics, I too would like a more solid, possibly core, answer for moderation/workflow in 8.x. I'm focusing on this patch first because I see it as a prerequisite for workflow.
Comment #142
stevectorIn that last patch I used the wrong variable name in taxonomy_build_node_index().
Comment #143
videographics commentedstevector, I understand and I'm with you on that. I certainly don't want to distract you from this current effort. I really like how this is taking shape. Keep up the great work!
Comment #144
stevectorThis patch has a start on tests to verify that the forward revision does not display at node/%nid.
l need to coordinate with with the work in #1612014: Create an interface for revisionable entities on variable/method names.
Comment #145
fagocreated #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text
Comment #146
jstollerSentiments are leaning toward calling an entity's primary revision (i.e. the one referenced in the base table), the "active" revision, rather than the "live" revision (as currently indicated in this patch). "Active" is a nice generic term that applies across all entities, plus "live" implies "published", which isn't always the case. I personally support this decision, but if you have an alternate opinion then please state it in #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text.
If the "active" terminology is adopted, then this patch should be modified to include it. For instance,
$node->isLiveshould change to$node->isActive.Comment #147
agentrickardPerfectly OK with that change, but it could be a follow-up.
Comment #148
jstollerPer #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text, I've updated the patch from #144, replacing all occurrences of "isLive" with "isDefault" and updating the comments to match.
Comment #149
Taxoman commented#148: what happened to "Active"?
IMO, "Active" is a more suitable term than "Default" in this context.
Comment #150
alan d. commentedI think that more verbose names should be used. I totally do not care if it is active / live / revision / version / coolest name from the latest fad, but isDefault as a global entity property is woefully poor at explaining what the property is for. I read this as this entity is in a default state, and in drupal that means that it is populated with default values. :(
so "is[Whatever state name is chosen][Whatever physical name is chosen]" please, which appears to be one of "is[Active|Live][Revision|Version]" from my limited time following these threads; i.e. isActiveRevision or isLiveVersion
Big thanks on the hard work here :)
[edit] After reading the other thread, ok so maybe isDefaultRevision, but personally do not like the default, but it looks like that is turning into the consensus from the other thread, and being read as "this is the current revision that will be used by default".
Comment #151
agentrickardNot quite. It is being read as you did not specify a version so you are being given the default one. And there is a reason for that, since "current" may not be an accurate term in a git-style revision branching scenario.
And this patch opens the way for that kind of complex revision branching.
Comment #152
jstollerI suggest we keep further discussion of terminology to the other issue, so we don't have to rehash everything here.
Anyone care to review the patch? The sooner it gets committed, the sooner we can return to talking about more comprehensive workflow solutions.
Comment #153
alan d. commentedI was referring to "isDefault" as there is absolutely no context to the property meaning.
i.e. After the patch, look in taxonomy.module, we have this new magic property.
This is coding practice rather than the debate about the naming. "isDefault" in a data structure like an entity could have many meanings, and the first meaning to me is that this is in a default state before being populated with data and saved. So by prefixing the Whatever, you have made it abundantly clear that we are in the revisioning system somewhere.
However, this is only my 2c from the occasional glace at the patches coming through, don't let it slow up any work here. :)
Comment #154
zhangtaihao commentedI can relate to both sides of the debate. Using words like "default" avoids misreading of "active" and "live". However, "entity is default" is now completely devoid of meaning, and it still doesn't avoid semantic conflicts particularly in domains where "default" has its own meaning anyway.
While I agree that, for performance and compatibility reasons, the concept of a "default" flag is essential, hijacking the entity property namespace seems a little uncalled for. I would suggest that the real question is, assuming these flags describe some aspect about the entity, why they must describe the entity using the same semantic/lexical constructs as "published" (which is how we've ended up in this situation).
Comment #155
agentrickardPlease don't rehash the debate on this issue.
Comment #156
sunYes, let's keep all discussion about the "default" part of the terminology over in #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text, please.
However, I wholeheartedly agree with @Alan D. - as far as the class property/method is concerned, there definitely has to be sufficient context in its name to clarify that it's meaning a revision and not something completely different. This discussion belongs in here, because this issue is about actual code and the other one doesn't take code into account at all.
Apparently, @Alan edited his comment in #150 to inject a corrected proposal (don't do that ;)):
isDefaultRevision
+1 on that (in case we go with "default"; otherwise s/Default/Whatever/)
Comment #157
jstollerI have no conceptual problem with changing isDefault to isDefaultRevision. Does anyone object to this?
Comment #158
stevectorI am fine with isDefaultRevision.
Comment #159
agentrickardFine. Move along! NOTHING TO SEE HERE! ;-p
Comment #160
Crell commentedPsst. Check the related terminology issue. It may be isDefaultVersion(). *runs*
Comment #161
cosmicdreams commentedThrilling! #148 has a patch that passes. What more needs to be done?
Comment #162
jstollerI changed all occurrences of isDefault to isDefaultVersion and rerolled. I suggest we get this reviewed and committed ASAP, then open separate issues to discuss further changes.
Comment #163
Crell commentedThis should be accessed through a method. It should not be a public property.
This is why it should be a method, not a property. Just bake it into the entity interface and be done with it. No more if statements.
Comment #164
alan d. commented@Crell, you mean to use this? I wish naming was sorted, as it hard to follow this in places...
Comment #165
Crell commentedIf that's the appropriate method to be using, yes. I lost track in there somewhere. :-) But it seems like that method should be renamed and repurposed for isDefaultVersion(). (Someone who helped develop EntityInterface correct me if that's wrong, but it seems to make sense.)
Comment #166
cosmicdreams commentedtried to work up a patch here, but #163 refers to a class and #164 refers to an interface. I don't know what logic the method in the #163's class would need to operate but it seems natural that the function return a boolean.
Comment #167
alan d. commentedWelcome to the wonderful new highly coupled world of OOP
This means that the interface "EntityInterface" is the contract that all implementing classes need to follow.
Entity has this contract, so any class that extends Entity also gets this contract.
So these different parts that all refer to the same thing. The method in Entity was what (we think) defines this functionality. So calling $node->isCurrentRevision() would return the value of $isCurrentRevision as coded in Entity.
[edit]
So this part of the patch can be removed ($isDefaultVersion), and anything setting that needs to set isCurrentRevision instead. But I am guessing on the functionality here.
Comment #168
jstollerIf I'm following this correctly then, based on what we've discussed here and at #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text, the entity class needs to be updated to change isCurrentRevision to isDefaultVersion. Yes? Should that be done in a separate issue, or should we add it to this patch? Does this patch need to be moved to its own issue?
Comment #169
webchickVersion has not been agreed to so I've no idea why were changing it Here. Stick to what needs to get changed.
Comment #170
Crell commentedwebchick: Then why is #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text still RTBC?
Comment #171
jstollerIf you prefer isDefaultRevision to isDefaultVersion, at least until the revision/version debate comes to an end, then that's fine by me. But in any case, isCurrentRevision needs to go. That change in terminology has more broad support. So how do we do it?
Comment #172
Mario.Bros commentedI tried WorkBench, and it allows you to make a draft of a published node.
The published node is not affected, it will show the new changes only when you decide to make live your draft.
Very useful.
Comment #173
jstollerWell, this is far outside my comfort zone, but in an effort to keep the ball rolling I've attempted to update the patch, converting entity->isCurrentRevision() to entity->isDefaultRevision(). Please review carefully and feel free to jump in and fix it if you have the skills.
@Maryo: Yes, Workbench is great! However, it needs to use some rather unpalatable hacks in order to implement that functionality, including saving every node twice. This patch aims to negate the need for those hacks, making it MUCH easier for Workbench Moderation/State Machine/Revisioning/etc. modules to do their job.
Comment #175
jstollerNow I'm really getting out of my depths, but it looks like the Field module tests are creating test entities based on a generic class, rather than extending the Entity class, so they're not implementing the full EntityInterface. Does that make sense? The tests seem to be failing because these test entities don't define an isDefaultRevision() method.
Comment #176
plachFYI, #1658712: Refactor test_entity schema to be multilingual is introducing a full-fledged test entity class extending the base entity class. It might turn useful to fix this issue.
Comment #177
fagojstoller: see #1616930: Fix the field_test entity type - that's need to be cleaned up first.
Comment #178
berdirfield_test entity is a crazy mess and a left-over from the dark days where entities were still called objects.
The real blocker here is actually #1551140: Remove stub entities, replace entity_create_stub_entity(), which the fix field_test entity type is also blocked. I need to get back to that but I also need more feedback there, please review and help!
Comment #179
jstollerIt seems that #1551140: Remove stub entities, replace entity_create_stub_entity() is blocking #1616930: Fix the field_test entity type, which is blocking this issue. So, do we put in a short-term fix to get around the test errors and commit this, or must I be patient?
Comment #180
jstollerI rerolled the patch against head, fixing a new conflict that prevented the old patch from applying. I also added temporary workarounds for the issues Field test is having, with @todo notes to remove them later.
Comment #182
berdir#1374030: Remove entity_extract_ids() now that we have proper classed entity objects is now in, this issue should therefore not be blocked anymore.
Comment #183
jstollerHere's a re-roll of the patch from #180 against head. There have been a number of changes to Core and the old patch no longer applied. No additional changes have been made in the patch, so this will likely fail with the same errors.
Comment #184
jstollerTest the patch, just for fun.
Comment #186
cosmicdreams commented#183: forward-revisions-218755-183.patch queued for re-testing.
Comment #188
jstollerI found some references to node->isCurrentRevision() hiding in node.module and changed them to isDefaultRevision().
Comment #190
jstollerWell, that seems to have fixed the fatal errors, but it's still failing the FileFieldRevisionTest and NodeRevisionsTest. I can keep tilting at windmills here, but if someone who actually knows what their doing wants to take a look at this, I'd be much obliged.
Comment #191
gábor hojtsy#1616930: Fix the field_test entity type is now committed, so there should be no external things blocking this work, unless we believe it is not possible to move forward here unless we have a consensus on terminology at #1643354: [Policy, No patch] Overhaul the entity revision terminology in UI text. I think we should be able to get this pass at least and have a patch ready which should still allow us to change terminology later if we need to.
Comment #192
gábor hojtsyRerolled since the patch did not apply right away. Let's see what we can do to make it pass as well :)
Comment #194
jstollerRemoved workarounds, now that the field_test entity has been fixed.
Comment #196
jstollerThe last patch no longer applied after #1761040: Rename Storable, Entity, and Configurable to Entity, ContentEntity, and ConfigEntity was committed. I also took a wild stab at fixing one of the earlier test errors.
Comment #198
gábor hojtsyLooked into this. What seems to happen is that as per the original behaviour (before patch), the revert action in the file test reverts to a previous revision making a copy of it as the latest (active) revision. The patch introduces the default revision concept, and when the revert happens, the revision is still copied to be the latest revision, but it is not made the default revision. I think the intention of the revert action is to make it so, so I'm looking into fixing that behavior with the revert.
Comment #199
gábor hojtsyThat's right, if we save the reverted revision as the new default (which is to be expected) then it all works fine. At least the 7 file revision fails were due to this missing piece.
Comment #200
gábor hojtsyAlso minor whitespace fix on a comment in the postSave() method of the node storage controller. No other change.
Comment #201
gábor hojtsyNew screenshot (going to include on the summary).
Comment #201.0
gábor hojtsyAdding a link to 1522154
Comment #202
gábor hojtsyFully updated issue summary to help people review. Looks like we need some more docs (I believe testing is covered) and we should possibly be ready to go for commit? (There is really not a lot of time left for Drupal 8).
Comment #203
jstollerAs a matter of principle, I do not think it is safe, or even desirable, to assume a reverted revision should be the default revision. In my workflow, I would want content editors to be able to revert to a previous revision, but that change will still need to be approved by management before going live. Making a revision the default when reverting should be an option, just as it is when editing a node normally. I would rather update any tests relying on a reverted revision being the default, so they explicitly set that property when saving the reverted revision.
That said, I want to see this patch committed ASAP, so if we have to fix this in a separate issue later, I'll live.
Comment #204
mradcliffeWouldn't your work flow then be to create a new revision for approval?
I think it makes sense that reverting is strictly reverting a live revision to a previous revision. Like in wiki systems.
Comment #205
mradcliffeApplicable doc pages:
Comment #206
jstollerIf reverting is a live transition to a previous revision, then we shouldn't be creating a new revision at all. We should just be marking the previous revision as the default revision. In practice, reverting is a way to create a new revision that's identical to an older revision, giving me a starting point from which I can then edit a node. Perhaps we're not talking about the same thing, since I'm looking at this from the UX/UI side, but when I click a link to revert to an older revision, I expect to be taken to a node edit page, preloaded with the content from that older revision. When I save that node (with or without additional changes), I want it to be saved as an unpublished draft, unless I specify otherwise.
Comment #207
gábor hojtsy@jstoller: changing what a revert means could be its own issue IMHO, unless you want to start this debate from the #206 comment onwards :) In Drupal, the current behaviour for reverts is that Drupal creates a new revision as a copy of an older revision. I think this makes sense (vs. just setting a previous one as default), because it provides bookkeeping as to what happened. It is true that the new isDefaultRevision will not provide history tracking like the revert functionality does now, and the above discussion targets that at contrib.
The current revert behaviour is indeed like as it is because it was not possible to revert to previous revisions without copying them to be the latest, so a clean re-implementation of the functionality on grounds of the new isDefaultRevision feature would be to just change which revision has this flag. It would give little insight as to whether a different one was default before, but there is no tracking for other property changes either. I think this might be best discussed in a followup if we want this to land in Drupal 8 :)
Comment #208
gábor hojtsyAlso, do we believe the code needs more documentation or just the d.o docs need to be updated? Would help with figuring out outstanding issues.
Comment #209
agentrickardThe patch acheives the goals for this issue. Everything else is UI/contrib. One very minor string change in the test case:
Should use "revision" in all cases.
Otherwise, RTBC.
Comment #210
gábor hojtsyFixed those pieces of text, "forward revision" only appeared in the test in NodeRevisionsTest.
Comment #212
gábor hojtsy#1702080: Introduce canonical FileStorage + (regular) cache affected some of the files we arre changing, eg. making the isCurrentRevision flag protected. Rerolled for that. Looks like this is crossing ways of where others actively working, so tagging accordingly.
Comment #213
webchickHm. The only obvious piece I can see as missing is the ability to set the default value of this checkbox on a per-content type basis. I'm not sure that it strictly needs to happen as part of this patch, but it would address jstoller's concerns, and would be consistent with the other publishing options.
Comment #214
agentrickard@webchick Can we push that to a follow-up to get some traction here?
Comment #215
webchickSure thing.
I'll leave this for 24 hours or so, since it's a fellow Spark team member working on this patch.
Comment #216
sunLooks good to me. Very happy to see substantial progress on revisions — I hope we'll continue to improve them further until feature freeze.
Comment #217
catchwebchick asked me to take a look at this because I'd had strong opinions on this issue overall. I don't think vast amounts has changed here since the last time I looked, which is a relief 'cos that wasn't too scary.
I agree with 'default revision' in the API, but does this adequately explain what happens if you uncheck it?
What happens after you submit this - do you still get redirected to the node/n page even if it's not the default? What about sending people to the revision instead in that case?
Do we have anything when viewing a revision that's not the default to make that really, really obvious and an easy way to promote it? Or is that a follow-up?
Also this should mean that the revisions UI is showing a 'revert' button near newer revisions, which doesn't make sense, I didn't notice a string change in there - it should probably be 'make default' instead of revert?
Comment #218
jstoller@catch, the idea was to get this in and then polish the UI/UX in a follow up issue. I personally am not at all happy with that checkbox, but I figure the API changes are more pressing. Do you need any of your issues addressed now, or can they wait for the followup?
Comment #219
webchickHere's a ~4-minute walk-through of the functionality, since that was easier than taking an ass-load of screenshots:
https://dl.dropbox.com/u/10160/default-revision-review.mov
The two biggest WTFs (and arguably commit blockers) are:
- After editing a draft revision, you are redirected back to node/X which still has the published text. Clicking "Edit" similarly loads the text from the published revision, not the text you just edited. This is totally discombobulating.
- Worse, there is actually no physical way to further refine said draft revision. Your only choices are to either delete it or publish it immediately, which essentially defeats the entire purpose.
I believe that there is probably value in getting the API change in alone, but without a sensical UX around it (which likely makes sense to start discussing in an issue that's not already at 200+ comments), this functionality currently seems to do more harm than good. Should we remove the UI entirely from this patch and make it an API-only thing for now? I dunno. Let's discuss.
If we were to commit this as-is, here would be the follow-ups I can spot:
- (critical task :\) Provide a better UX for editing draft revisions. You should see the text you just edited after you click the save button, and it should be given some sort of visual affordance for "draft mode." When you click "Edit," you should edit the text of your most recent revision, along with a visual affordance to let you know this is happening, and give you the option of editing the currently published revision instead. (Note: If we don't commit any UX with this patch, I think this would become a major feature instead and not count against thresholds.)
- (normal feature) Allow editing of revisions from node/X/revisions. Any revision should be able to be the base of a draft, really.
- (normal task) Change "Set as default revision" to "Set as published revision." Even better, actually, might be inverting the checkbox label / value. Make the label "Save as draft revision" and default it to false. If a contrib workflow module wants to add fancier draft options, they can hook_form_alter() the label/default value to something else, or replace it entirely. Not core's problem.
- (normal task) Add "Set as published revision" / "Save as draft revision" checkbox to the content type edit form, so that you can choose to put some content types through a default draft workflow.
- (normal task) Re-label "revert" in node/1/revisions operations column to "publish" for "future" revisions. Also adjust the text there to include this new capability. (e.g. "Revisions allow you to track differences between multiple versions of your content, revert back to older versions, and publish draft revisions.")
What say you?
Comment #220
webchickFor those in a hurry (and aren't we all), ~2:30 on has the salient points. The rest is context for people coming into this patch fresh.
Comment #221
fagoThis functionality should not be built UI first, it should be API first and get an UI on top. I.e., any API tests of this new functionality are missing - we really should add them to make sure it works as expected on the lower level first.
The same functionality is about to be added to d7 entity module at #996696: Support revisions in Entity API, where we already have some API tests. With some small adaptions it should be possible to take them over, see http://drupal.org/node/996696#comment-6438770
Having a method isDefaultRevision() that can be used for setting seems weird to me. Why not add setDefaultRevision($value = NULL); instead?
Comment #222
gábor hojtsy@fago: for the set/get this is really not the result of this patch, it was there before (and in fact recently changed via another patch). So let's not argue that here. We are merely adjusting terminology because current would be misleading.
@webchick, @fago: I agree the UI is not at all fully baked and especially agree that we should not go and do a UI exercise here. I'll look at #996696: Support revisions in Entity API for tests, but my initial hunch was that we can keep the UI based tests but only show the field for the test (via an alter). That would test that it also works on the UI if there is some control for the flag.
Comment #223
gábor hojtsyComment #224
gábor hojtsyAll right, now (a) removed the UI (b) testing the API instead of the UI. I understood that as we should save the new revision with the API not the UI, but I do use the UI to test whether the revisions show as "front facing" or not. Since we use the API to test saving, we lost some excess in the tests. Yay. I think loading back the same revision that I just saved (and got back in my test anyway) is not really productive.
Removing the UI portion from the summary, or better noting that we DO NOT add a UI here.
Comment #225
gábor hojtsyA patch should help :D
Comment #225.0
gábor hojtsyUpdated summary for current terminology, UI
Comment #226
mustanggb commentedI may be completely missing the mark with what I about to post as I'm a first time visitor to this issue, so salt pinchers at the ready.
I think it's fairly safe to say that drafts should be editable whereas reverts should not. However from a quick look at the patch the only determination of whether a revision is forward or not that I could see is based on it's vid in comparison to the default vid. That is, if it's higher than the default then it's a draft, if it's lower then it's a revert.
One potential use case that this could cause an issue with this is if one user has created a draft with the intention of coming back to edit it. In the meantime another user either performs a revert or publishes a change of their own. Now when the first user returns to edit their draft it has a vid lower than the default and is considered a revert, even though it has never been published. As a revert there is no-way to edit it without publishing it first.
Now you could get around this by when publishing a draft bumping up the vid of any other drafts and slotting the new one in-between. Then notifying users that try to re-edit their drafts that a new revision has been published since their draft was created.
However I wonder if there might be a better way to determine whether a revision is a draft or not, for example {node_revision}.status = 2 or {node_revision}.draft = 1.
Comment #227
mustanggb commentedComment #228
gábor hojtsy@akamustang: the user interface exposure of making new default revisions in this patch was removed given the debates around this, so the interaction should be worked out in another issue. This one is open for 4.5 years and we have not managed to get a basic backend to support revisions that are later then the front facing revision. The aim of this patch is merely to support that.
Comment #229
agentrickardI just want the code in core so we can work through the UI. Without committing to the API change, this issue will die in committee.
Comment #230
yoroy commentedAnd we wouldn't want that :) Opened #1776796: Provide a better UX for creating, editing & managing draft revisions. for the UI part.
Comment #231
agentrickard@yoroy++
Comment #232
sunThanks for removing the UI/checkbox part. I agree with getting the API into core ASAP and working on the UI (and possibly other API improvements) in parallel.
That said, @webchick made a nice list of todos in #219 -- we might want to move that list over to #1776796: Provide a better UX for creating, editing & managing draft revisions.
Either way, time to move forward here! :)
Comment #233
webchickOk, awesome. I'm sorry for torpedoing this at 219 comments in, but really appreciate the quick turnaround. We can reconvene over at #1776796: Provide a better UX for creating, editing & managing draft revisions. for next steps!
Committed and pushed to 8.x. YAY!!!!!!!
I also added a little entry to CHANGELOG.txt under "Improved entity system":
I'm sure that needs further tweaking, but agentrickard and Gábor weren't around to ask.
Awesome work, everyone!!
Comment #234
jstollerI would like to personally thank everyone who helped with this. Just 4 years, 213 days, 18 hours and 31 minutes after posting this issue, there is now a patch in core. It's a great start and I am absolutely ecstatic! Yay! :-)
As promised in #137, now that the default revision patch is in, let's return to discussing the implementation of a more full-featured system for supporting revisions in arbitrary states, enabling more comprehensive workflow support.
Given that this issue is so old and was sidetracked by the task to create a (related, necessary and very important) patch for the last 128 posts, I thought it would be best to move the larger discussion to a new issue. I took the liberty of opening #1777388: Support arbitrary workflow states.
Comment #236
webchickRetroactively tagging "Spark"
Comment #237
chx commentedremoving Avoid commit conflicts tag
Comment #238
chx commentedtry #2
Comment #238.0
chx commentedRemove screenshot, no UI anymore.
Comment #239
elijah lynnComment #240
jhedstromComment #241
fabianx commentedPinging people following here:
jstoller opened #2477419: Codify mechanism to set a forward revision as the default revision to support the 2nd use case to _do_ something with forward revisions properly with test coverage, etc.