Problem/Motivation
- In Drupal, we use hooks as our primary tool for allowing modules to customize nearly any behavior of Drupal core or other modules. It's a very simple yet powerful implementation of the Observer pattern and implicit invocation architecture. For example, any module can add to what happens early in a page request by implementing hook_init() or modify any form by implementing hook_form_alter().
- However, not every kind of extensibility is best modeled by "module A broadcasts an event and all modules react". Sometimes what we want is "module A wants some specific chosen thingie or a specific sequence of thingies to perform a well-defined operation, but for which exact thingie(s) is/are used to be configurable". Any module should be able to extend the system by providing additional thingies that can be chosen from, but at any given time, only the actually chosen one(s) should be invoked. For example, the Image module lets you create image styles by choosing from a set of image effects (scale, crop, rotate, desaturate, etc.). Any module can add more effects to the system. However, a particular image style is configured as a particular sequence of effects, and when it's time to generate an image of that style, the Image module wants to invoke just that particular sequence of effects.
- In core currently, we have at least a dozen such examples, and each one is implemented slightly differently. For example:
- The Aggregator module allows any module to implement one (and only one) "feed fetcher" by implementing hook_aggregator_fetch(). However, this is unlike common hooks like hook_init() or hook_form_alter(), because the Aggregator module doesn't passively broadcast an 'aggregator_fetch' event for all modules to react to; it actively keeps track of which fetcher the administrator configured to be the active one and only "invokes the hook" on that one module.
- The Block module allows any module to implement one or more blocks via hook_block_info(). It provides an admin/structure/block page allowing the administrator to select which blocks to enable and in which regions to display them. When it's time to render a region, for each block added to that region, it invokes the hook_block_view() "hook". Like with hook_aggregator_fetch(), this "hook" is not invoked on all modules, only the module that "owns" that block.
- The Image module allows any module to implement one or more image effects via hook_image_effect_info(), and provides a UI for defining image styles as a sequence of one or more effects. When generating an image in a particular style, for each effect in that style, it invokes the 'effect callback' function included as part of the definition of the effect, rather than a "hook". This has the advantage of not calling a non-hook a hook, but it also results in there being no documentation for the signature and expectations of this callback.
- The Filter module allows any module to implement one or more text filters via hook_filter_info(), and provides a UI for defining text formats as a sequence of one or more filters. When outputting text in a particular format, for each filter in that format, it invokes the 'process callback' function included as part of the definition of the filter. This is like the Image module example, but goes a step further by recommending a naming convention for this function and documenting it as a pseduo-hook.
- The actions system allows any module to implement one or more actions via hook_action_info() and for invoking the action, calls neither a pseudo-hook nor a callback function added to the action definition, but rather a magically named function based on the action id.
- The cache system includes a cache() function for getting back the implementation object (e.g., one for a database backend or one for a memcache backend) configured for the requested cache bin, and then the receiver of that object invokes well defined and well documented interface methods on that object. However, there is no API function for getting either the full list of possible cache bins or the full list of available backend implementations, and consequently, no UI for configuring what to use: the configuration must be managed manually in a settings.php variable.
- Just as there are inconsistencies in how "pluggable thingies" are invoked, there are inconsistencies in how they are discovered by the module providing the configuration UI. In many cases, an info hook is called, but sometimes it's followed by an alter hook and sometimes not. Sometimes the result is cached, sometimes not. Other details vary from use case to use case unnecessarily, and if two systems happen to share the same approach, they do it via duplicated rather than actually common code.
Proposed resolution
A plugin system that provides an API to make all these things consistent where they can be, and customizable where they need to be.
Remaining tasks
The initial patch has been committed. Need to open follow ups for converting systems to use it.
User interface changes
None by this issue.
API changes
hook_aggregator_fetch_info() has changed. This needs a change notice.
Original report by neclimdul
Plugin Documentation [in progress]
http://drupal.org/node/1637614
Slogan
"The goal of the plugin system is to get everyone into the same chapter, not necessarily onto the same page." --David Strauss
Background
So we’ve had the concept of “plugins” as swappable implementations of groups of code for a long time in Drupal. In Drupal Core have a variable_get/include replacement system used for things like cache backends and contrib has things like ctools, views and some other bespoke and clever systems. In Austin last year a lot of people sat down and distilled the concepts down into some core ideas and an architecture(summary). Now that we have a rough implementation its time to start discussing how we polish this off for core.
What does the architecture look like?
First it's important to understand the the slogan a bit. The idea is to provide concepts and tools for best practices. We want developers to be able to open up “plugin” code and conceptually be able to understand and discuss what’s going on even if the implementation is different from the defaults provided in core. Hence in the same chapter, not on the same page.
There are a some of important conceptual definitions that are useful as building blocks. These are the more general concepts that most developer would interact with.
Discovery
Plugin discovery is the idea of discovering Plugin Implementation definitions. It's possibly the most important concept because it distinguishes plugins from just using an interface and a factory. It is core to plugins because it provides the tools for building user interfaces and its definitions are the bridge that get us from configuration to implementation.
So in your UI you use getPluginDefinition() to fetch definitions to drive your UI with things like human readable names. When saving from you UI you store the appropriate key bundled with the configured values. Then at runtime you can then call createInstance($key, $options); and get back your configured instance.
Discovery as an implementation is in itself “pluggable.” It is generally very closely connected to the Plugin Type but can be shared and replaced as needed as long as the interface is respected. While we can implement a common method for core, there are cases where the restrictions around a plugin force it to be implemented in unique ways and having the type able to choose a different discovery implementation allows this with minimal effort. An example would be layouts defining a plugin in a yaml file and listing template, js and css files. A PSR-0 class with annotations or a hook would not make sense and would be unnecessarily difficult for template developers.
Previously we’ve used info hooks and for very high level system this could be an options but ideally we’d like a better method. Currently we’ve implemented a “static” crud based implementation that could be useful for the earliest most limited Drupal bootstraps and there is a annotation based method in the works that will hopefully be the default and common implementation.
Plugin Type
Conceptually a plugin type is the grouping for all Plugin Implementations that satisfy a particular purpose. Practically it is a class that provides the methods for interacting with those plugins. All Plugin Implementations are the members of exactly one plugin type and should be interchangeable with other implementations of the same type(they share an interface). The common example of the concept is the "Cache storage system" is a plugin type. "Database cache", "Memcache cache", etc. are plugins that conform to that type.
Plugin Type objects are the place where the high level business logic of the type is implemented. Definition defaults are defined, discovery and factory implementations are defined and any specific edge cases are dealt with.
Plugin Implementation
A Plugin Implementation, or simply "Plugin", is a self-contained, encapsulated concept. It represents a implementation of a plugin type. Functionally and most importantly it is a definition that defines how the plugin is implemented. It will generally contain a human readable name for UI usage and and other relevant metadata. It will also have a associated class but this may be a default implementation that acts on the definition metadata.
The normal case of a plugin might be a block where the entire implementation is contained in a unique class and the metadata contains the Admin title and some information like cacheability and form defaults.
Another example would by something like a “layout” or “style” plugin that would only need to define template, css, and javascript files. In this case we would have a different discovery implementation that would have a single class for all implementations and the behavior of that class would be defined by the metadata of the layout(registering the css/jss file, returning the specific theme hook, etc)
Plugin Instance
A Plugin Instance is a particular configured Plugin Implementation. It generally exists as a bundling of configuration with a Plugin Implementation. Functionally it literally resolved to an instantiated object but conceptually can exist as a triple of the Plugin Type, Plugin Implementation and configuration.
Plugin Derivative
This is arguably the most confusing concept to grasp. People coming from CTools know this concept as “child” plugins. They’re plugins that share implementation in every way but are defined by some more dynamic system. If you were to accept blocks as plugins, each block like “Powered by Drupal” would be a normal plugin and custom blocks would be derivative plugins. Derivatives are important because, since every sub implementation is listed in the same list as the other plugins, they are able to be provided in the UI as unique items. This is best demostrated by sdboyer in his comment on this issue. In the end is becomes a way of preconfiguring plugins in a very specific way.
Plugin Mapper
This Plugin Mapper is a front-facing object that is the main point of contact for the entire system. Its core job is interfacing with Discovery and proxying best practices around using a factory. Its a PHP Interface that can be replaced with different discovery methods depending on the use case of the plugin.
Plugin Factory
Plugin Factories exist per Plugin Type and have a simple task of instantiating plugin instances. There is a workflow implied by the mapper interface by design but more elaborate layered system like maybe views are welcome to use the interface in more clever ways.
Conclusion
So we took these concepts out of the sprint and refined them some with some more prototypes. So here’s where we’ve arrived and here’s some code! Lets open this discussion up.
Sandbox: http://drupalcode.org/sandbox/eclipsegc/1441840.git/shortlog/refs/heads/...


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
robloachGoing to see what the bot says!
Comment #2
yched commented@neclimdul: It seems the patch is not up to date with the current state of the 'plugins-next' branch ?
Comment #3
eclipsegc commented@yched
I don't think this is "up-to-date" with any branches at the moment, but it's close and was an easier patch to get to allow others to see what's going on. I know my plugin code is definitely different, and we have some merging to do, but I do hope that people can start looking at this and give us some general feedback.
Eclipse
Comment #4
neclimdulNo yched was right, I uploaded an old patch from I'm not sure where... Here's the right one.
Comment #5
yched commentedSo I've been working on an OO reformulation of the Field API ($field and $instance as classed objects; field types, widgets, formatters, storage backends as 'plugins'), relying on the work done by EclipseGc and neclimdul on the Plugins API.
This is still largely in progress, and has a couple "internal" challenges that I won't delve into here. I'll just use this as a feedback base on the current state of the Plugins API.
Short version : it works, and is fairly simple to leverage :-)
Make your plugin types visible to the Mapper, check if the provided factories are fit for your use case, or build your own. Done.
This being said, I mostly side-track the current Plugins API code by using my own factories rather than the DefaultFactory currently provided :
- because the routing logic ("which specific [cache backend|text filter|widget] implementation should be instantiated") is not read directly from CMI in my case.
- because I have a "philosophical disagreement" about using CMI to store info about "available implementations for a given plugin type", and very much prefer the info() hook pattern
I'm currently still using the default ConfigMapper, that reads about plugin types from CMI too, but I'm kind of reluctant as well, and I'm considering switching to the StaticMapper (plugin types get explicitely registered to the mapper at runtime).
This "flexibility" is actually what worries me a bit. Right now, the Plugins API provide a series of interfaces, and a procedural plugin() function as a handy single point of entry for client subsystems to use. You're still free to implement very different logic and behavior in the actual Mapper and Factory classes you decide to use for your own subsystem. The current 'default' Plugin API classes do something, the classes used by Field API do something entirely different.
So in the end there's a chance we're left with something not very far from the current "multitude of bespoke plugins-like behaviors across core and contrib" issue.
While keeping some flexibility is good, I do think we should aim at something like "one or two base classes fitting most uses cases", to set best practices.
OTOH, I think "complex" objects like image styles (a series of pluggable image effects), input formats (a series of pluggable text filters), views (a series of pluggable fields, filters, sorts, etc...) will share common needs : routing logic is not read directly from CMI, but held in a classed $image_style, $field, $view, $whatever_thing object that has already been instanciated from a raw CMI definition somewhere. Provifing a base factory for this use case would be interesting.
Possibly : translatable strings in the static method rather than in the cached info registry, for instance.
That would allow us to really work on solving the known issues with info() hooks - or come up with someting better - on a centralized mechanism, instead of letting each subsystem try to figure them out on their own.
This being said, I don't feel that any of the above is a prerequisite to get anything in core. Getting a working base mechanism in soon would let the "X as plugins" tasks start off and help identify the common needs mentioned above.
Comment #6
yched commentedSide note on the current plugins-next branch :
PluginInterface::setConfig(DrupalConfig $config)This is very CMI-coupled. This method is called by the DefaultFactory, and seems only appropriate for plugins instanciated by this factory. Doesn't seem like it belongs to the Interface.
Comment #7
eclipsegc commentedA couple quick notes on your rather lengthy (and insightful) post.
1.) neclimdul and I agree that CMI is probably not the BEST way to do discovery. However it was the path of least resistance for getting to this point. As I understand it, a new discovery methodology is something neclimdul is actively working on, so all your points in this area are basically a reiteration of his logic to me on these points. In short, we agree. That being said, instance information still feels very much like it should be coming from CMI.
2.) On that note, your point about setConfig() is a good one, and if you look in the 8.x-blocks branch you'll find that function's signature has changed to
PluginInterface::setConfig(array $config = array());This should make the system significantly more robust, and any CMI based systems will simply need to pass $config->get() instead of $config. We really need to merge the branches here. :-D
That being said, as a side note, I'd really like to see the removal of info hooks where possible, so a better discovery method will hopefully allow that, but that's also outside the scope of my initiative which is why I'm not actively working on discovery here. Along this same line of logic, we agree about providing the proper base factories that core needs. So I think we're all very much on the same page. As to the flexibility of the system to provide your own factories and even mapper, I think this is a good thing as it should force a very repetitive syntax down on all the potential implementations within the system which SHOULD increase readability of what's going on for anyone who understands the plugin system. And obviously the more it's used the more people will have to understand it. Even if the primary class structures are swapped in favor of others the interfaces bring a consistency to calls that I hope will be a net win for everyone.
Eclipse
Comment #8
dixon_@neclimdul I think your patch in #4 was the wrong one as well :)
The system must be very flexible since we don't know how things will work yet. We have many plugin types for core and a gazillion of them in contrib to write. So if we can get everyone to implement the same set of interfaces first (even if it might mean some duplicate code in them), that will make it easier to improve the system later. This goes in line with:
Comment #9
xtfer commentedWould anyone who knows a bit about this work care to provide a brief summary of how this implementation of the Plugin concept is similar to, or differs from, those in ctools, as it is the current reference standard for plugins and is well known to current Drupal developers? That might help us review the patch further...
Comment #10
yched commented@EclipseGC :
Definitely, instanciation logic very much config. My point above was that IMO there will be 2 main flows :
- "Simple" stuff like cache backend instanciation read routing params directly from CMI, and the DefaultFactory is good for that.
- But for many other systems, the routing params are part of a "thing" that has already been read from CMI ($view, $field, ... already massaged from a raw CMI array to a classed business object), and the factory should not try to read from CMI again. I think a base factory for this "family" of plugins would be good to have.
This is closely related to the "settings CMI files / 'things' CMI files" dichotomy that is being made in #1479492: [policy] Define standards for naming and granularity of config files.
OK, sweet :-)
@_dixon :
Sure, I'm completely fine with "get everyone into the same chapter, not necessarily onto the same page", but IMO we should aim at favoring extensibility by inheritance from a couple structuring base classes that provide well identified patterns and practices, rather than just extensibility by interface ("please everyone, just do whatever you like").
Those base classes can very well come in followups as we move along the "X as plugins" tasks and identify the common patterns.
Comment #11
yched commentedBouncing on my own #5 :
That is actually a need whatever the discovery mechanism is (CMI, _info() hooks, new method). Plugin instances will repeatedly need to access the definition of their implementation (whether you call it $config because it lies in CMI, or $info because it's an entry in an _info() registry).
How this happens efficiently is something that we should try to standardize (keep a separate copy of $info in each instanciated class ? fetching from a shared static list somewhere ?). That would probably reflect in PluginInterface or an abstract BasePlugin class.
Comment #12
eclipsegc commented@yched
So... merlin, neclimdul, myself, DamZ, and bojanz discussed this for a bit at drupalcon and DamZ encouraged us to try class annotations for plugin definition, and reworking our PSR-0 namespaces in order to benefit the discovery system (At least if I understood correctly). Merlin seemed fairly convinced by this, but we have yet to actually do the work (as far as I know) so, I expect this to be the basic discovery mechanism for most plugins definitions. This won't work for everything we have planned but sounds like a really good use case for a lot of the plugin types.
@dixon_
Yeah, you've basically hit on our thought process. To address yched, I'm not opposed to good base classes that are expected to be extended however, forcing that doesn't seem wise, the interfaces are there, and the primary reason you'd want to switch out mapper or factory is because you have a different discovery methodology. Most of the real code in these classes is discovery oriented in some way anyway, so I don't really seem much benefit to inheritance.
@xtfer
Understand that neclimdul and I (we are essentially the authors of this plugin system at the moment) are both ctools co-maintainers, so this is VERY ctools inspired. From that perspective, the majority of code surrounding the plugin system that exists within ctools is focussed on discovery methodology. Really, most of what was written to begin with stepped around that (by using CMI as an easy path) and instead implemented the "easy" stuff. That said, conceptually this is pretty much an OO rewrite of ctools plugin system. As an example, I was thinking through this the other day, and for an initial port of ctools to D8, it would probably be VERY feasible to write custom mapper and factory(ies) that depend on the ctools hooks that currently exist, and I suspect we could get around even needing to upgrade the individual plugins in ctools. I'm not suggesting that we SHOULD do that, but it maps closely enough that I think it's possible. Hopefully this answers your question?
Eclipse
Comment #13
xtfer commentedThanks @EclipseGc, that's helpful.
However, the patch in #4 now appears to be empty...?
Comment #14
eclipsegc commentedhmmm... amusing that that passes heh. I'll check with neclimdul, I'm sure he'll have another forthcoming shortly.
Comment #15
neclimdulHaven't had a chance to really dig into what looks like some good comments but here's another patch.
Comment #16
lars toomre commentedHmmm... Only 11 tests pass?
Comment #17
neclimdulI don't know what 11 tests you're referring to. I have 3 trivial assertions testing the singleton and the basic mapper interface. Help writing tests is welcome and kvanderw has said he'd like to port some of our early tests that from a previous prototype but where lost. I'll be happy to take patches here, patches on the sandbox or as pull requests from where ever you like.
Comment #18
tim.plunkett#16, #17, there was an issue with the testbot where it was only returning 11 passes. The bot has been fixed and the test requeued, so now it shows all 35713 passes.
Comment #19
xtfer commentedAre you thinking of drawing this from CMI as config, or using the docblock... e.g.
Comment #20
xtfer commented- Accidental duplicate -
Comment #21
eclipsegc commenteddoc block as I understand the current plans.
Comment #22
bojanz commentedJust wanted to reiterate that I really support looking into annotations.
I know some people hate them because they are essentially a hack and not a language-level function, but it's a really nice hack :)
You can see how Doctrine uses it with great success (we'd probably steal their parser as well)
And it would allow us to use annotations for other things as well, for example explicit hook registration (since we essentially do it right now as well, the docblock is just not parsed), which would have huge wins (knowing which modules need to be bootstrapped, and not needing to load them all, etc...)
Comment #23
effulgentsia commentedCool work so far. It would be great to get some use-cases into this patch. Perhaps one simple one, like the cache system, and one more complex one that demonstrates the need for "plugin derivatives" and yched's other concerns (image styles?). Blocks and fields could serve the more complex demonstration, but maybe they're too complex and would distract from the meat of this patch. What do you all think about this idea, and do you have suggestions for other use-cases to pick instead of 'cache' and 'image styles'?
Comment #24
pounardSome random notes made by reading the git code:
About the
PluginInterfaceinterface:This seems to highly couple to CMI, I would rather go for no interface at all for plugin themselves and a runtime check on an interface such as
ConfigAwareinterface that would live in theConfignamespace. Plugins have no mandatory per design need to be configuration aware.In
FactoryInterfaceinterface:It seems that the
DefaultFactoryclass does some magic tricks with the array and parameters to pass onto the constructor, it's fine, I'm not against reflection for this kind of things (seems logical since we are spawning objects from meta descriptions) but theFactoryInterfacedoes not document that part of the contract at all.In class
Mapper:I may be wrong, but is possible that the config system doesn't return anything here? There is no error handling at all for this case?
The type hinting is wrong pretty much everywhere (I even saw a
@return stringfor a method returning an object).Aside of that, it sounds fine. I would definitely go for a generic hook based implementation of factories provided along with the CMI based one, it would make a lot of sense, even if we are trying to get rid of hooks, CMI as its lot of drawbacks too.
Comment #25
pounard@#11
I agree that a lot of plugins will need this, but not every one of them, the
PluginInterfacecould be more detailed about this information and how to inject it, or some other interfaces could be derived from that one.Comment #26
eclipsegc commentedYeah, we've already decoupled the CMI specific config stuff from plugin in my branch, but we're still figuring out how to merge neclimdul's stuff and my stuff together (they're actually very close). In my branch there's a PluginAbstract that implements this stuff for you, and I really didn't want to see yet another layer of classes around this, which is why the config is optional. I'm open to arguments against it, but it's optional in my branch, and has the basic logic built for you already, so I'm hoping that will actually work long term and we won't need another set of classes just for configuration.
Eclipse
Comment #27
yched commentedClass annotations sound intriguing, I'm curious to know more. I'm not sure I really see the pros aside from more "self containedness" (a plugin implementation = a single class file, rather than a class file + a corresponding entry in an _info() hook in another file).
OTOH, I can imagine a couple cons :
- not alterable ? Our current info() hooks rely on alterability. I guess an alter() can be invoked as a second step in the discovery process. This means two different formats for the 'primary exposition' (annotations in PHPdoc) and for the alters (php arrays)
- translatable strings ? Varies for each subsystem, but at least for each plugin type that surfaces in the UI, plugin implementations need a 'label' and often a 'description'. I guess the pot extractor can be taught to recognize
t('some string')(or whatever convention) in phpdoc annotations, and the registry somehow resolves the language at runtime. Or we establish a clear pattern that 'translatable strings' need to live in runtime static methods (thus, are not alterable).in the implementation class.
Comment #28
yched commentedForgot to add :
I agree with @pounard that would be a good idea to start off with an info() hook based implementation, so that the work on converting existing subsystems can start early while info() hook replacements are explored.
I'll see if I can move forward on this next week (I should be able to sort out some common ground from the plugins-fieldapi branch, I have 3 hook-based plugin types in there...)
Comment #29
effulgentsia commentedI delved into #15 a bit more, and tried to figure out how to refactor cache() to use this plugin API. My guess is something like this:
A couple questions:
plugin.type.core.cache.xmlfile? What should we put into it other than<class_param>class</class_param>? Would it make sense to make DefaultFactory use a default value for "class_param" (e.g., "class"), allowing us to not need a config file at all for plugin types that don't need to do anything non-default?core.cache.bin.$bin.xmlfile for every cache bin, in order to specify the class to use for that bin. However, currently, cache() provides a fallback mechanism to a default class. Would it make sense to make DefaultFactory check for a default class within the plugin type definition?Comment #30
neclimdulI'm not actually a fan of the CMI implementation because it doesn't ensure the consistency of the system(the can be modified and then don't actually reflect the system correctly. It is currently the only system we have other then cache for this sort of information though so I don't know. Eclipse might have ideas on how to actually use it.
As far as the singleton, I think you only need:
The getFactory method is only for edge cases, the mapper is designed to have proxy methods for enabling the best practice approaches.
I'm working on refactoring some of the code to better encapsulate and merge EclipseGC's derivative code and address the feedback provided. Hopefully I can get that up this weekend if I can work out and small architectural problem in the singleton.
Comment #31
pounardCache causes a problem indeed, I think it's not the best example, because it will always trigger a file load since the first access will happen without the cache system so potentially no active layer up yet. We need a factory able to load data from a generated PHP file for performances, for this particular case.
EDIT: Some sort of emulation of settings.php file, or being able to define plugins in pure PHP arrays in the settings.php file would be a huge win for that.
Comment #32
pounardIf I look at this code:
It seems pretty weird that the 'config' key must be known to the developer for retrieving plugins, the whole goal is to hide and abstract the discover mecanism right?
Comment #33
eclipsegc commentedWell, I think the goal is to be able to loosely define discovery, so:
I know this is a plugin, I know I'm looking for definitions, I know it's scope is core and it's type is cache, therefor I should be able to find all plugin definitions thusly:
plugin.definition.core.cache
That being said my repo for this should actually allow php arrays to be passed as config w/o an associated name, so I think that's very doable and well within the scope of how we want it to work. I agree, a core caching mechanism should have a mapper/factory combo that can check settings.php (or similar).
Eclipse
Comment #34
pounardThe plugin() function is confusing, the user needs to know the Mapper class name if he want to get plugins which are not handled by the default mapper, is that a wanted behavior? I imagined that we could have a smart mapper that would be able to find factories from multiple sources?
And and just thinking of another use case: some plugins might be defined at pre bootstrap time (cache backends for example) before the database or cache systems are up, but some plugins of the same type and scope definitions would come later thanks to CMI or info hooks, we might want multiple factories per scope and plugin type?
EDIT: Some other random notes:
FactoryInterface::getInstance()does not define the behavior in case no plugin associated with given options exist, throw an exception? return null? return false?Re-EDIT, a minor conceptual problem (may be I did not understand some details of the design):
If I understand well, we have:
1..n [Mapper] 1 --> 0..n [Factory] 1 --> 0..n [Plugin]
Actual workflow is:
We can have more than once mapper, each mapper is responsible for n factories, each factory can instanciate a specific plugin type instances, which can be n different plugin objects (with different classes). IMO, each defined plugin in the factories should probably derived from an arbitrary string key instead of an array of options,
FactoryInterface::getInstance(array $options)would become: FactoryInterface::getInstance(string $plugin_key = null, array $options = null) where options and plugin key both becomes optional and both explicit.Natural workflow would become for most cases:
And for more trivial use cases (cache backend):
This because with the actual implementation, callers always have know each class they must use, but IMHO the end user don't care who provides it.
For this to work, we need as I said upper a bit smarter mapper which must be able to lookup in factories from both config, PHP settings file, etc.. IMO the mapper must be storage agnostic.
I'm note sure that what I'm saying is clear or not?
Comment #35
eclipsegc commentedSo a couple of corrections to your code examples:
This is so that we can do something like :
WRT a more generic mapper, the problem is that a mapper MUST know how to load up the plugin_type information (which will give it the factory to use). If we want to standardize on this and not make it pluggable (which I'm frankly sort of indifferent about) then we can have a generic mapper, however just because the mapper works via CMI, or info hooks, or whatever method, doesn't really matter imo. The default mapper should work for the VAST majority of cases, and the factory class REALLY defines how a plugin is discovered. Also, supporting a pluggable mapper means that systems (like ctools) can provide custom mapper and factory(ies) for their plugins and have working plugin in D8 with out needing to convert all their plugin code as well. This would give ctools, views and other plugin systems the ability to adapt to D8 much earlier I think. I've not actually tried this out yet, but I'm thought through the logic problem a few times and I think it works.
Finally, you can see in the block_load() code above that I'm moving toward a system here where we can pass arbitrary array values as though they're legitimate configuration for a plugin instance. These are purely programatic plugin instances in this case, and it allows us to do the nesting of configuration that has been discussed a few times here. Pounard's example of :
is well taken, but then that's not really different from just taking an options array with a magic key for $plugin_key in it. Chances are you'd want a defined key for the whole of configuration anyway as well, and this gives factory providers a little bit more flexibility if they ever want to pass something else through. I've never been strictly "For" this approach, but it's benefits are not lost on me.
In any event, I'm really liking the discussion I'm seeing in this post. You all are coming to essentially the same conclusions we came to on this code before posting it (again it was the easiest code to post) so seeing that process played out a second time is very comforting. I know neclimdul is hard at work on a next revision of all of this, so hopefully we'll have something new to poke at shortly.
Eclipse
Comment #36
neclimdulSo I took the suggestions here, some chatting in IRC over the weekend and some brainstorming and restructured the plugin system.
Comment #37
neclimduloh, I should note, the requested hook implementation and core use are not included yet either.
Comment #38
effulgentsia commented1) Do we need $scope and $type as separate arguments (both here and throughout the various classes in this patch)? Can we reduce to just $type, and standardize client code to use a "." delimiter as appropriate? For example, "core.cache".
2) If the last parameter is expected to be an object, then $discovery_object or $discoverer would be a better name.
3) While config() and plugin() are two totally different systems, they're superficially similar, and yet config() hard-codes the class of the "inner" object (DrupalVerifiedStorageSQL) while having a parameter for controlling the class of the returned object (DrupalConfig by default), while #36's plugin() does the opposite: parameterizes the inner object (ConfigDiscovery by default) while hard-coding the class of the returned object (PluginKernel). Should we make these more similar to each other or is there a good reason for the variance?
Comment #39
effulgentsia commented#38 is questions only, so back to "needs review".
Comment #40
neclimdul1) Its what we'd agreed on in the original sprint and is used in ctools and I personally don't see a reason to not be explicit. Also, its just a implementation detail of the sample plugin wrapper. It would make sense at this point to have plugins wrap the kernel in their own singleton hiding the discovery creation and type/scope logic.
2) Good point, I'll have to change that.
3) Well, since the discovery is what gets passed around and is injected to bootstrap the process it makes sense to have be the "inner" object. I don't immediately see a way to reverse this logic.
Comment #41
effulgentsia commentedThis might be a crazy thought, but has anyone already brought up the idea of piggy backing the plugin system on Symfony's dependency injection container? I just read the section on Tags, and started thinking that's a lot like what plugin types are. The Symfony code already handles configuration-driven factory selection and some interesting interfaces and default code for initializing a newly created "service" with further configuration. Combined with discovery based on tags, it's seeming increasingly similar to what we need from a plugin system. Seems like perhaps the biggest difference between "plugins" and "services" is that services are singletons per "id", whereas plugins can be instantiated multiple times per id, but is that difference enough to warrant inventing our own kernel/mapper/factory/derivative/discovery interfaces completely from scratch?
[Edit: note that by "from scratch" I don't mean to disparage all of the amazing work that's gone into CTools, and this patch so far, it's great stuff. But some of the CTools work had to deal with PHP 4 baggage, and meanwhile, Symfony's invented some great PHP 5.3 code, and I'm just wondering if there's a way to mesh our experience with theirs.]
Comment #42
Crell commentedThe plugin system here draws heavy inspiration from ctools, but shares no code at all. It's all PHP 5.2-based architecture. (The differences to 5.3 are not significant given that we cannot use closures due to the need to save configuration, and closures are not serializable.)
There's really 2 types of things that fall under the "plugins" umbrella, which I've loosely defined as:
1) "dude, get me the configured thingie named 'bob'" (such as a configured image style, text format, or View).
2) "dude, get me the object I should use under circumstances X" (such as the "filter" bin for the cache system, the password hasing backend, the theme system, mail backends, etc. See #363787: Plugins: Swappable subsystems for core for the previous discussion along those lines.)
Historically, Earl and the ctools folks came at the problem from the perspective of solving part of part 1. I was interested mostly in point 2. We met in the middle somewhere as we realized that the problem spaces overlapped about 80%.
In practice, for many, although not all, of the stuff in point 2 the dependency injection container is an alternative approach. For those things that are either single instance (password hashing, mail backend, theme system) or trivial distinction (cache system and cache bins, which could be handled with a simple naming convention like cache.filter, cache.block, etc. with some redundancy), that's arguably a decent way of doing it and, I'd argue, we may want to simply wrap the DIC around the plugins.
I don't see how the DIC would handle more complex cases with multi-part properties to determine the "appropriate" plugin object to use, nor do I see a good way for it to handle the first case at all. Certainly we're not going to stick all Views into the DIC as view.my_view_name. (At least that doesn't make much sense to me at this point.)
What the DIC would do, and I'd say should do, is act as a replacement for the plugin() function itself. That dates from before we had any expectation of having a DIC in place in core. However, if that's going to happen then I would favor dropping plugin() in favor fo $container->get('plugin.kernel') Or somesuch). Some other factories can probably get wrapped in their on their own as well, such as cache.filter which in turn would call to $container->get('plugin.kernel'). Of course, there's still work to do to get the DIC in place and figure out how we're going to handle registration in a non-slow fashion.
The DIC also does not, as far I'm aware, offer a good way to handle the complex configuration that we're going to have in some cases. There may be a way to piggy back on to that, but I'm not sure.
I would actually recommend that we proceed here without leveraging the dependency container, but keep in mind that many things here may in practice get wrapped by and accessed through the DIC. But there's problem spaces here that are outside the scope of what dependency injection offers. Also, as of earlier today much of the code is now a free-standing Component, with no dependencies. Even if most of the access is through a dependency injection container, that's still a really really good thing architecturally.
Comment #43
pounardOk I fetched the new
plugins-kernelbranch, here is some notes and questions:DiscoveryInterface, I like that because it separates the factory from the discovery mecanism thus allowing the factory code to be more reusable, this is good IMO.Drupal\Component\PluginandDrupal\Core\Pluginnamespaces, it's now clearer about what is higly coupled with core and what is not, nice move.MapperInterfacemagic somehow into thePluginKernelInterface, I really don't see the point of keeping theMapperInterfaceout there, it just duplicatesPluginKernelInterfaceandFactoryInterfacefeatures altogether while the frontal object being presented to the user viaplugin()is thePluginKernelInterface. Maybe keeping theKernelbut namedMapperwould actually do the trick (I don't think Mapper is the right name, but I'm not sure Kernel really is too).PluginKernelInterface::getPluginInstance()andPluginKernelInterface::mapPluginInstance()? I actually don't understand the difference between those two even when I read the different method signature. Either they are poorly named either it's wrong by design.PluginInterfacehas accessors for Config, this should maybe change name to Options instead to avoid ambiguity with the config system (and potential later name conflicts), plus options is a common name accross some other frameworks for exactly this.PluginInterface::getConfigValue()really makes sense on the interface itself. Plugins instances will be able to read their own configuration internally, and because we don't know what will be the future instance maybe it just won't have options.PluginAbstractreally worth to exist right now, especially just for thegetConfig()andsetConfig()methods.StaticDiscoveryclass has a wrong name, I would call itArrayDiscoverymaybe, focusing on technical driver and avoiding confusion (static means something in PHP)StaticDiscoveryalso lacks of a constructor which would accept the internal$plugin_definitionsand$type_definitionsdirectly, thus allowing those to be harcoded in a PHP file.FactoryInterface::getPluginInstance()does an hardcoded$instance->setConfig($configuration);call, IMO the plugins might not bePluginInterfaceimplementors, thus it lacks someinstanceoftests. You could also use the$reflectordirectly to do those checks.class_paramarray key in definition is weird, maybe it should be named justclass.PluginKernelInterfaceis the frontend, there is still no object that keeps a scope/type<>mapper? mapping, so there is no single entry point for getting plugins for the end user, this user actually probably don't the internals, and probably don't care about it. If thePluginKernelInterfacejust duplicate methods from bothFactoryInterfaceandDiscoveryInterfacealtogether, I really don't see the point of keeping it, maybe the PluginKernel was indeed best named as the Mapper, but the mapper could be able to keep a collection for (DiscoveryInterface,FactoryInterface) couples keyed on scope/type instead of just carrying one of each and just being a proxy to them.Comment #44
neclimdulLong posts. Wow.
So re: Symfony, we did a lot of searching and our discovery model is very much novel. Tags are different in design and use and mostly from my understanding for boot strapping required services and context switching. This is a very different concern from discovery which is mostly for propping up our UI driven system and enabling config driven systems. Think about all the meta information needed to enable the views or panels UI. Then the reverse is recreating and mapping the configuration exported from that into running code. That is what plugins are really about.
I actually have to disagree with Crell about ctools approach some. Ctools has always focused on fetching discovery information and fetching individual instances of specific plugins and left the composing of complex systems like a panel, view or feed up to the system
so that it can do it in a way that makes sense to it. That's why that is an option in the current model using getPluginInstance instead of mapPluginInstance.
Along those lines, pounard and I had a long conversation about his comments this morning and this mapping logic is what was tricking him up. This more of an extension of ctools' ideas from Crell's plugin ideas so I need to talk to Crell and him about this more.
Comment #45
neclimdulAlso, on the StaticDiscovery, I am open to calling it something else. ArrayDiscovery is weird though because everything talks arrays. Maybe CrudDiscovery or something similar?
Also, I ignored the scope and type in the constructor because they end up not having any meaning because you have to set the type, not discover it somehow. It was actually the reason I left the constructor and those parameters out of the constructor. Maybe that was a mistake and StaticDiscovery should be the special case and ignore them? If that's the case we can go back to passing the discovery class name in and adding maybe a getDiscovery() method on the kernel. Something worth considering for sure.
I don't know what to say about the config methods. We use options in the mapper to mean something else but that might not matter. I don't see a huge problem with the way it is though(other then maybe we frown on abbreviations).
Comment #46
pounardThe config name brings me a red alert, if somehow the config team comes up with let's say a
ConfigAwareinterface, withvoid setConfig(Config)andConfig getConfig()it could then conflict with it.Comment #47
eclipsegc commentedif we're discussing config within the plugin instance itself (i.e. what the PluginAbstract is there for) then I think the notion of a ConfigAware interface is non-essential because all plugins are config aware, they're just not config required. This gives us some basic sanity when working with any plugin, we ALWAYS know how to get at it's configuration if it has any, it also means that we have an interface that does something that we can actually do instanceof checks against.
I'm not opposed to removing getConfigValue() (especially since that could be unified with getConfig() if it were to accept an empty string $key like getConfigValue() does). This mirrors what CMI's DrupalConfig object does and hopefully gives us some consistency of use.
With regard to @effulgentsia's comments on how config() does things, I'm going to propose the config() actually does stuff wrong. The config() function would be WAY more useful if it always returned a DrupalConfig object, but gave us the chance to change the verified storage class instead (being forced to check against sql is bad, I should be able to define say, a pure XML file check). Being able to change out both would be better, but I digress, the point in our case is that Discovery should be swappable, and while other stuff on top of that could be swappable too, as long as the discovery object is doing the heavy lifting work for us, it makes writing more generic factories, and kernel/mapper stuff WAY easier, which is a net win for core, and means the lion share of our complexity exists within the discovery mechanism itself, which was always true, just in the previous architecture it was sprinkled across many classes instead of being focussed down to one class (sorry my fault). neclimdul has cleaned that up, and I think this incarnation of plugins is all the better for it.
Eclipse
Comment #48
cosmicdreams commentedGiven the comment in #47, tagging for the config initiative.
Comment #49
pounardConfigAware may not be essential for plugins, but it could be an helper interface the CMI would create, for some other purposes. It would make great sense actually. I'm just saying since it's not CMI stuff we pass to those "config" accessors we probably should not call them "config" but "options" or "parameters" or whatever else.
Comment #50
pounardI'm not pro making the getConfig() function signature polymorphic, it's more magic, less explicit.
Comment #51
Crell commentedThe config() function lets you specify a subclass of the DrupalConfig class, so that what you get back can have extra methods that make sense in your situation. Views is a good example of a case where you probably would want to have some extra useful methods on your config object. At least that's why I originally argued to allow that parameter. :-) The storage mechanism in CMI is what it is and should never vary by system.
So yes, plugin() and config() do things backwards, because they do different things. And, really, both should eventually go away in favor of an object in the DIC anyway so let's not dwell on such matters. :-)
Comment #52
yched commentedTook some time to look at the new code (and pushed some typo / comment fixes with neclimdul's premission). I did not port the field API branch over to it yet, so the remarks below do no stem from actual use of the new API.
Overall I like the new direction this is taking. Factories being discovery-agnostic and DefaultFactory looking like it's going to fit most cases is a great step forward. Thx for the great work, neclimdul :-)
[EDIT: scratch that, revised in #54] I can't really envision generic patterns around this for now, so what to put in a DefaultMapper class is not clear to me. AAMOF, I'm not sure this really needs to be part of the Plugin system. Since it's basically "translate client business logic to plugin_id & settings, then call the factory", why don't we just leave it up to each subsystem to do their own "translate" part before calling
plugin()->getPluginInstance($plugin_id, $config)?Actually, while it is pretty much established that we need to allow different 'plugin implementations' discovery mechanisms, I don't think I see why we'd need more than a single mechanism for 'plugin type' registration. Can't we just add a 'plugin_types' Event and have each system that exposes a plugin type implement a dedicated listener, and be done with it ?
At any rate, I don't think coupling the two is a good idea. Most plugin providers won't bother going further that the "standard" way of exposing their plugin types (whatever that ends up being), but will pick amongst the 2-3 'plugin implementations' discovery mechanisms we provide, or ship their own.
Comment #53
yched commentedSide note :
- ConfigDiscovery::getPluginDefinition() and ::getPluginDefinitions() call a getDerviative() method that is not currently implemented anywhere
- The 'derivative' logic in both methods looks like it could be factored out. It's also not something that is specific to the ConfigDiscovery mechanism, each Discovery class will need the same - factorize to an abstract base class?
Comment #54
yched commentedAfter actually moving the Field API branch to the plugins-kernel approach, I revised a bit what I wrote in #52 :
Regarding 2), I do see how including a Mapper step is valuable, and is best encapsulated within the plugin() flow than left to the calling side. However, the logic in there will likely be specific to each given plugin type (in fact, if the discovery issue settles on one or two standard mechanisms, the Mapper will probably be the single class most plugin types ever need to override).
So the question is what to do with the DefaultMapper class (currently its mapPluginInstance method is left as a TODO). I guess some plugin types won't have a need for a mapping step, however the current PluginKernelInterface includes a mapPluginInstance method, so there always has to be a mapper. Then maybe just something like this ? :
Regarding 3), I still think that Discovery classes should only involve implementation discovery, and that plugin types would be better off registered independently (event at bootstrap). That would allow the discovery class name to be a property of the plugin type, just like the factory and mapper, while the current code forces the client code to know which discovery class applies to which plugin type, which doesn't feel right. That would also avoid the calling code instantiating one discovery object per call to plugin().
Comment #55
effulgentsia commentedFYI: I have some work in progress in #1519376: [Meta] Extend Symfony's service container and use that for simple swappable systems and plugin access and discovery that I think simplifies the plugin system a lot by leveraging Symfony's service container for #42.2 and for the swappability of the plugin system itself, leaving only the essential bits needed for #42.1. My next step on that issue is to see if it actually works by attempting to convert the image effects system, but commenting here in case anyone wants to provide early feedback on the approach I'm taking there. I think it either addresses or might make irrelevant some of the recent comments above.
[Edit: I converted that issue to a meta issue, and will take what I think are the useful bits of it and turn them into individual patches to the plugins-kernel branch instead.]
Comment #56
effulgentsia commentedI created a patch against the plugins-kernel branch that does this: #1529162: Decouple plugin type discovery from plugin discovery
Comment #57
effulgentsia commentedAny feedback on #1540206: Allow self inspection on instantiated plugin objects? Note that as of #1538712: Merge latest 8.x HEAD into plugins-kernel, "plugins-next" is now the active branch, "plugins-kernel" is dead.
Comment #58
neclimdulThe self inspection issue isn't really a blocker for anyone at the moment but the patch is currently blocked on #1538706: Make derivatives work for getting the blocks initiative supported.
edit: correct issue number
Comment #59
sunFriends, the time for premature optimizations and stuff is over. We need a final patch to commit here. Yesterday. ;)
You can still revise and polish this after it has landed. "Derivatives", magic, whatnot, doesn't matter. Change it later.
What matters way more is to have at least one, simple, example conversion in this patch. Because the mere Plugin API code is extremely abstract. I already tried to wrap my head around this code earlier, but wasn't really able to imagine how an implementation would look like. So ideally, please take the most simple example in core that you can think of and straightforward-convert that into plugins. (I can only guess, something bad-ass-ly hidden that doesn't depend too much on config would be perfect, so perhaps the mail system [or alternative cache backends?] or ...)
In any case, please understand that time is running out. There's tons of other work that's currently hold off on this proposal, not only limited to Web services and Blocks/Layouts. This also affects entity and field API as well as configuration system progress... Or in other words: everything :P All of these efforts still have a very long way to go, so every single day this patch is not in core is a day that is subtracted from their originally planned schedule. ;) We're very soon hitting the stage and point in time in which various efforts will have to make a decision (on whether to wait for this any longer or fall back to ugly old patterns and approaches).
As mentioned, we'll still be able to revise this later on. If you want, you can rewrite it entirely. ;) However, I seriously believe that what you guys came up thus far is a definitive improvement on its own over current core, so I am not afraid of pushing this in and forward. :)
Comment #60
eclipsegc commentedThanks sun, I generally agree except that ever single initiative you mentioned actually needs derivatives, which is why we've all agreed that this is the last improvement we're making before a core patch proposal. I ended up having a couple other initiative issues take precedence yesterday. I intend on working on this this weekend and especially monday (which is a holiday for me) so that we can make that final patch proposal to core.
Thanks for pushing forward here (Alex as well) I think we all recognize how important it is to put a fork in this issue and call it done.
Eclipse
Comment #61
effulgentsia commentedOnce we have derivatives (#1538706: Make derivatives work) in, which I really hope happens by Monday or Tuesday, some next steps are:
I propose we set a target to get the above done and post a core patch here by Friday.
Comment #62
effulgentsia commentedThere's been a slight delay on this due to tornadoes where EclipseGc lives, but we're still trying to get this ready as quickly as possible.
Comment #63
andyposteffects ready?
is cache per language? any reason?
Comment #64
neclimdulUpdated patch with a bunch of work from the sandbox. There was some major refactoring but the concepts are mostly the same.
Change summary
Weaknesses remaining bugs
Big thanks to effulgentsia, yched, EclipseGC, and sdboyer for really doing most of the work and merlin and pounard and probably others I'm forgetting for some great insights ideas and reviews.
Commit summary
94d0d6a Issue #1538798 Make mappers runtime swappable
4b1e519 Follow up to document reflection helper method.
f0ca654 Issue #1613638 by effulgentsia, sdboyer: Use decoration instead of a base class for derivative discovery.
7666372 Clean reflection and apply some of yched's inspection ideas
d789918 Issue #1512602 by effulgentsia, yched Write a hook based plugin discovery implementation.
465a746 Issue #1538692 by effulgentsia: Change PluginTypeInterface to extend Discovery, Factory, and Mapper interfaces.
f3b2282 Move plugin tests to PSR-0
31c7cca Merge remote-tracking branch 'origin/8.x' into plugins-next
d719c94 Remove ConfigDiscovery
08265e4 Issue #1538706 by effulgentsia, EclipseGc, neclimdul: Make derivatives work.
55dce7e Fix #1529162 by effulgentsia Remove drupal_object
e8df699 Some plugin definition defaults code
4a74f87 Move test stuff to PSR-0.
87a059b Move plugins test out of simpletest.
96f06ba Merge branch '8.x' of http://git.drupal.org/project/drupal into plugins-next
47ab2a4 Remove unused namespaces from bootstrap
49febb5 Decouple plugin types from discovery patch
4cf185e Rename (get|map)PluginInstance
bc60f4b fix type hinting
7697153 typo got copy pasted :-)
6580c69 fix typo
ee9c03b type hinting
db5f054 type hinting
4434101 unify some param names, remove stale docblocks
137f4a4 replaces some 'Implements ...' phpdocs
318fb2e fix some typos, add type hinting
0eef45f Rename discovery_class because its an object
db62673 Class_param isn't a paramater. Just call it class.
Comment #65
neclimdulrun tests. also, please review.
Comment #67
aspilicious commentedThere is a ton of doc cleanup to do before this can go in :)
I reviewed parts untill I realised it was too much.
So here is a partial review. When fixing these also fix the other docs ;).
EDIT: I removed my review here and fixed the issue in a branch
23 days to next Drupal core point release.
Comment #68
neclimdulRemove what seems to be some cruft in _drupal_bootstrap_page_cache(). pinged chx about it since I can't find any docs on the previous use of $conf['cache_backends'] but this gets the patch rolling.
Comment #70
neclimdultests are failing because of #1617208: After kernel patch, module_hook_info() returns an empty array when called by load callback, access callback, or hook_init()
Comment #71
neclimdulQuick workaround to fix tests and some docs and todo docs from aspilicious.
Comment #72
effulgentsia commentedThis extra blank line causes #71 to no longer apply. This patch removes it. No other change.
Comment #73
effulgentsia commentedComment #74
cosmicdreams commentedHow does this impact performance? Is it too early to analyze this change's impact?
Comment #75
webchickSo Alex and I just spent about 2 hours on the phone going over this patch. I made a bunch of notes, and will try and extract the most relevant ones here. Sorry, this is kind of all over the place.
First off, I think something that would be EXTREMELY helpful is the creation of a page underneath http://drupal.org/developing/api (with whatever disclaimers about this not being in core yet) with a diagram of how all of these various pieces—plugin types, mappers, factories, discoverers, derivatives—fit together and linking to that from the PHPDoc sections of all of these components. I am completely fine with something hand-drawn and then cameraphone snapped... really doesn't need to be fancy, but the overall context would help *a lot* in understanding this system, because without Alex guiding me through it I think I would've been totally lost.
I really like that this patch already shows a couple of examples of how the plugin system would work in practice—both for "traditional" CTools-style plugins w/ image effects, as well as a replacement for the variable_get('thingy', 'path-to-include-file') method for cache backends. Kudos for that. There is not yet an example of using the derivatives system, but Alex said the use case for that was mainly for blocks, and holding up this patch on converting blocks to plugins doesn't make much sense. Agreed there.
We do have tests that test the derivatives system, but the way they are written is not remotely helpful to understanding the context of why one would use derivatives. "coolaid" (which should be "kool-aid" btw, and maybe we want to switch to "juice" or something non-copyrighted ;)), "beer" and "wine" are basically fine as use cases, but then let's make the derivative strings they check for things like "Lager" or "Pinot Noir" (thanks for Earl for his expert drinking knowledge help w/ these terms on IRC ;)) instead of "Test String 1".
Then, at the risk of opening a huge bikeshed argument, I do have a concern with the name "Derivatives." It sounds scary/overly technical, and I think it might be hard to grok for non-native speakers. Could we just use the name "Child/Children" for these, which are well-understood in computer science?
In general, the ratio of "ugly, weird code removed" vs. "straight-forward code added" here is really good wrt the cache and image effects stuff. There's still a bit of weirdness around the naming of various things. For example, I couldn't tell you immediately what a class called "PersistentVariableDiscovery" does. I also didn't dig too much into the PHPDoc of those classes though, still something for me to do. I did see some spots where we just did a missing/empty/"@todo" PHPDoc above sections and that is of course a no-no, though. ;)
The decorator stuff is really sweet. It allows us to wrap, say, cache-ability around not only a hook-style discovery mechanism but potentially other discovery mechanisms as well.
Passing $this, $this into the Mapper is pretty weird. I understand why this was done—for both the factory and discovery arguments you might want additional context which the full object provides, but it's really hard to tell what a line like:
...is doing.
I still probably need to look at this at least 2 more times to really grok everything, but great job so far.
Comment #76
Niklas Fiekas commentedI've been going backwards through the patch, superficially looking for coding style issues, to get a first idea of what this does. Thanks all! This looks pretty good.
[...] Moved out nitpicky hick-hack as sun suggested.
Comment #77
sunLet's keep those minor documentation issues in #1512588: [meta] Fill in plugin documentation, please. I'd love if you (also @aspilicious earlier) could copy your comments over there and empty out the comments here afterwards, to reduce clutter.
Aside from that, I pretty much agree with everything @webchick said.
However, as soon as the phpDoc, comments, and minimal docs have been hashed out, I'd rather like to push this into core and slap it on everyone's face, and revise whatever possibly needs to be revised (if anything at all) in follow-up issues/patches. That is, because I'm really really getting afraid of the remaining time-frame until feature freeze, considering how much stuff is blocked on this.
Comment #78
Niklas Fiekas commentedI agree. If we hadn't done the "slap it on everyone's face" approach for the Kernel it probably wouldn't even be in, now. Some things have to be done like that, or they'll take forever.
Comment #79
eclipsegc commentedThis should be a bit more complete documentation wise. It's by no means perfect, and I honestly didn't document the mapper since it's not a system I make extensive use of and someone else could certainly document it better. Hopefully though this will help others in reading through what is here.
Eclipse
Comment #80
neclimdulYou guys rock. My eyes kinda glassed over seeing the big docs/coding standard review here and putting them on that issue helps a ton! Love the feedback and I'll see what I can do to digest and apply it this weekend.
Comment #81
effulgentsia commentedFYI: separate core patch for just this in #1323120-106: Convert cache system to PSR-0.
And this in #1617208-6: After kernel patch, module_hook_info() returns an empty array when called by load callback, access callback, or hook_init().
19 days to next Drupal core point release.
Comment #82
sdboyer commented/me echoes most of this feedback. lemme make a couple notes.
i *strongly* second the need for that API page. it's gonna be a fair undertaking, though. could probably be an excellent day's sprint work to just map out the cases and figure out how to describe it all well. my feelings on the importance of this is probably slanted, given that i've been hankering for such docs for years, but this is a deeply fundamental API, and i think there are really just untold benefits to having it all crystal clear.
i've got a patch up that makes the tests for derivatives a wee bit more illustrative of how that relationship works: #1623760: Change test examples to use more illustrative names and strings.
wrt (re-)renaming 'Derivatives' to 'Children' - i griped a bit at the name too, but i've been swayed by the other folks' arguments that 'Child' is not a good replacement (despite it being what we call these things in ctools right now). that namespace is indeed already thoroughly taken by that meaning which is "well-understood in computer science." but, given that basically the whole point of derivatives is not creating "child" classes, i think it would be quite misleading to call them that. now, that doesn't mean 'Derivatives' is the best and final answer...but i do think it's better than 'Child.'
glad you like the decorator :) it's one of those patterns that suddenly becomes wonderful in a more OO-rich environment.
err...providing "additional context" to the mapper is actually not at all why it's being like that. 'additional context' is actually the opposite of the goal. the default mapper's constructor specifies that it needs a factory and a discovery object to be passed to its constructor, and if it is to respect the contract implied by that interface, it *cannot* assume that those objects implement anything except the interfaces specified in the signature, let alone assume that they're both the same instance of
PluginTypeInterface....that said, because we chose to make
PluginTypeInterfaceextend the discovery, factory, and mapper interfaces in order to really make it into the central point of API interaction (per the discussion in #1538692: Change PluginTypeInterface to extend Discovery, Factory, and Mapper interfaces), it's pretty likely to be the case that what you'll be passing in there is the plugin type object. doing it that way has the benefit of allowing a single point of control over what objects to actually use for each of those functions. example: say that client code changed the object being used for discovery on a particular plugin type (assuming that's allowed to happen - it isn't in any current examples). if the old discovery object had been directly injected into the mapper and factory, they would have to be manually updated with the new object. if all their calls pass through the plugin type rather than their own reference in object scope, then there's no need to update them.i'm still a little uncomfortable with *not* having the constructors or any setters specified anywhere in those interfaces (discovery, mapping, factory, and plugin type itself), as it means there's a loosey goosey element in this system, still. we could probably make it work by having them all use the same constructor that takes a DIC...but still.
what's really important, though, is that i am quite sure a good docs page will clear up how these various interfaces fit together, and with the bigger picture + examples in place, apparent oddities like that will make sense pretty quickly. also, it's a bit less of a concern since those interfaces are only germane to plugin *type* implementors, a much smaller crowd than plugin implementors.
Comment #83
neclimdulYeah, Sam nailed the $this argument passing. Yched I think argued that we should pass the type instead but I think passing the individual interfaces makes more sense as it more explicitly defines the things the object is interacting with. This may seem academic but I'm pretty sure its the right way and while this one line makes less sense, I think it better defines the interface of the mapper making its code more clear.
I'm not sure what to say about the constructors. We originally had constructors and more setters on some of the interfaces then we worked away from and removed them, now you're considering if we need them. At least my thinking in the leaning process was to make the interfaces the minimal cohesive interface and then provide additional interfaces/implementations for cohesive concepts. Part of that is minimizing the code to be reviewed, but also proving what methods really are the core of the system. I think we're ok now so we could probably bikeshed on that for a while after we get the initial patch in.
Comment #84
eclipsegc commentedYeah, removing constructors from interfaces in general seems a REALLY good idea in the long run as it'd be better if we could instantiate different individual classes differently (as needed) instead of forcing some one size fits all constructor method on them. I actually think the lack of constructors will probably play as a strength in the long run and not a detriment. I'm obviously very open to hearing counter arguments, but Fabien essentially made this argument about individual plugins themselves, and while I don't think that will ever pan out there, it has obvious implications for thinks like discovery, factories and mappers as those are all implemented by the developer, and not a catchall methodology that has to work across all implementations. This is just my initial thought on this topic, but thought I'd throw that out there.
Eclipse
Comment #85
sdboyer commentedi was gonna advocate for a system that keeps the constructors for the composed objects in an interface somewhere, but after chatting with @EclipseGc, i'm conceding that it's fine to leave them out.
Comment #86
pounardI'm also against keeping constructors in the interfaces.
Comment #87
catchI haven't reviewed this yet, and I'm going to be afk for most of the next 2-3 weeks so while I'm hoping to be able to take a longer look at this patch this week, I can't promise an in-depth review at the moment, will see how it goes.
In lieu of that though, I did quickly run it through xhprof, and got mixed results.
The first hit with the patch, there was 34ms added by reflection's hasMethod() (which is checking for the existence of __construct in the patch). That's called 3 times.
However profiling again, this went down to 3ms. Not sure why - maybe something going on with my machine, maybe there's some caching somewhere of the reflection call in PHP itself?
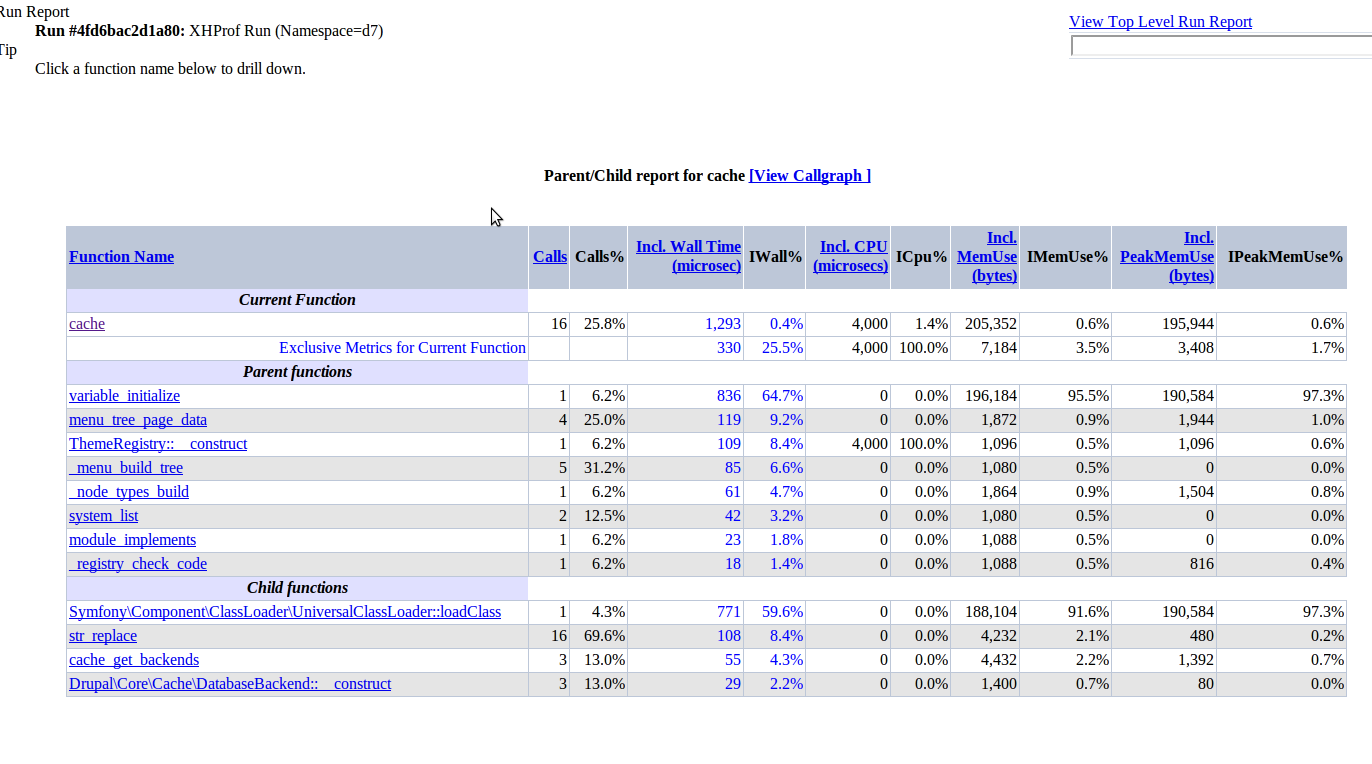
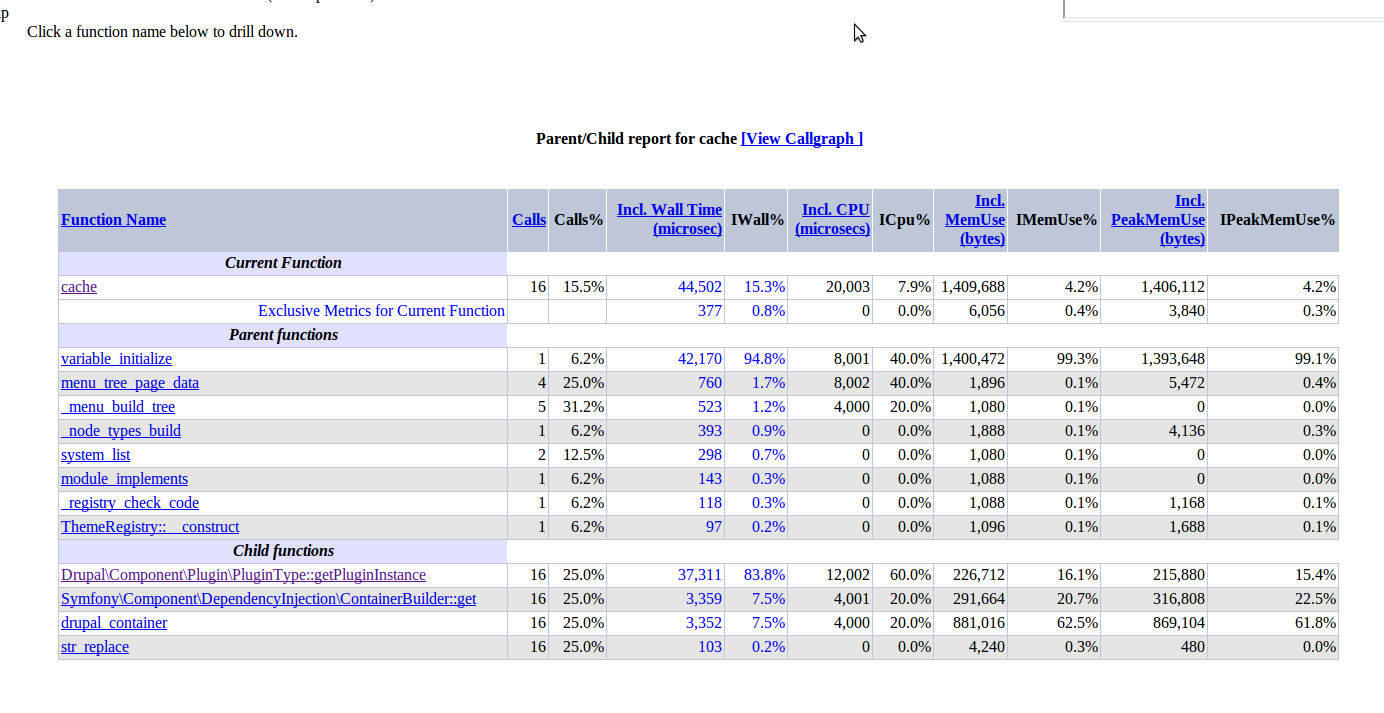
Overall though, even cache-after-again.png is showing a difference between 1.2ms spent in cache() without the patch, to over 10ms with it, as well as 320 additional function calls. Apart from the first profile run which was considerably worse, I was able to reproduce that consistently.
Attaching before/after screenshots that show the difference.
Would be good to investigate this more before a commit. Would also be good to get benchmarks of the page cache to see if there's a measurable regression or not there.
Comment #88
catchOK still not a proper review, but effulgentsia asked me to take a look at the cache-specific sections of this patch if at all possible this week.
Overall there's not many changes to either the cache or image effects subsystems to support this, which is pretty encouraging in general (although in the case of image effects I wonder a bit if we're missing something, didn't look enough to find out though), obviously encouragement is tempered by the performance data above.
Couple of things stood out, these are minor in the scheme of the patch but looked odd to me:
I can see why this was added for the cache conversion, since that's currently using $conf/variable_get(), however variable_get() is going to disappear before too long, so adding an explicit class to support it seems the wrong way 'round. Could we not use $GLOBALS['cache'] (or some other key instead of $GLOBALS['conf']['cache']) then that would detangle the cache configuration from both variable_get() and configuration system overrides which are still using $conf. Had been meaning to eventually open that as a separate issue until I noticed it was being dealt with here.
That would also be more consistent with the $databases array (side-note - is there any desire to move database drivers to plugins too? If so it'd be good to be able to use the same discovery mechanism for both I'd think).
This change seems completely unrelated?
The caching strategy for plugins seems OK, and good that it's centralized - nice to see the code removed from image effect discovery. I'm a bit concerned though that we could end up with huge cache entries if there's lots of plugins defined for a specific type (maybe blocks?) which could end up pulling us into another schema/theme registry situation again. Although if the discovery all happens in one place then the optimization could likely happen in one place as well if it turns out to be needed.
Not much there but need to take a break for now.
Comment #89
eclipsegc commentedSo, as a quick thought here, perhaps the cache implementation would benefit from having a custom factory instead of leveraging the default factory and it's Reflection stuff. Then something specific could be built to the cache system's needs and maybe speed up this process some. I guess I'm going to need to get xhprof up and running and start profiling some of this myself. Still if I read what you're saying appropriately here, a custom factory might not fix a lot. Is that a proper interpretation?
Eclipse
Comment #90
neclimdulYeah, cache probably needs a bespoke set of components, its using the default implementations to provide visibility into how they can work. The variable method was also used to generalize the system and keep as close to the core implementation of a "plugin" system standard. Middle ground of invasive and descriptive while showing the flexibility. Would a follow up be appropriate or should we go ahead and address it here?
The image_hook_info is there to allow the image_effect_info hook to work correctly in a general hook_info discovery. As it stood, image.effects.inc would not be included and so the tests would fail. This and #1617208: After kernel patch, module_hook_info() returns an empty array when called by load callback, access callback, or hook_init() where needed to get the image tests passing as plugins and not be special little snowflakes.
Comment #91
yched commentedIf the default factory introduces a significant performance regression, that's not only true for the cache system, other subsystems will likely suffer from this too - "Fields as plugins" means instantiating potentially hundreds of plugins on a listing page (1 "field type" plugin + 1 "formatter" plugin per field).
Fixing this with a one-off, optimized factory for the cache system sounds like a strange way to fix this. Then every subsystem that is "critical enough" (insert your own criteria here) needs to come up with its own specialized factory too ?
If the default factory is too slow, then we should fix it.
I've expressed my concerns about relying on runtime reflection (as opposed to symfony's compile-time reflection) in other issues in the Plugins queue.
If the issue is mostly about hasMethod('__construct'), however, then should this be described by an explicit property in the plugin definition instead ? ('has_constructor' => TRUE | FALSE) ?
Comment #92
catchYes I don't think doing this just for cache is sufficient. It looks like there's three cache bins queried on the front page, so that's three turns at hasMethod() (although on exactly the same thing each time I think). Other systems like fields are going to see many more checks than cache. Specifying whether there's a constructor in the plugin definition or similar sounds worth looking into.
Comment #93
eclipsegc commentedThere's an effort to move the default factory to call_user_func_array() right now (I think we can expect a patch tonight) and we'll move the current factory into a "ReflectionFactory" class or something. I'll admit I was playing with Reflection and that code just ended up useful. I was warned numerous times it might be a performance hit, but we hadn't actually benchmarked it yet. Happy to see these mid stream changes being made once we have some hard numbers though, and I agree that a "critical enough" argument is bound to lead to more factories than we'd like. Still I think the argument can (and probably SHOULD) be made for caching, and we can clean up our defaults in the mean time to be less of a performance consideration.
Most of the criticism we've seen thus far is around performance, are there any other thoughts that stand out at this point?
Eclipse
Comment #94
effulgentsia commentedRe #91-#93, feedback welcome on #1630874: Several cache related changes based on catch's review, though I hope that neclimdul commits that and posts an updated core patch that includes that to this issue before tomorrow morning. We can keep refining that type of stuff after this initial core patch lands, but IMO, to the extent that a cache system performance regression is a blocker for this initial patch, we need that solved to unblock this issue and all the work that depends on it. Performance optimizations of ReflectionFactory (or whatever we want fields and blocks to use) can come later, either as independent follow-ups, or as part of the Field API to plugin conversion patch that will follow this one (once yched has a chance to finish getting that ready).
Comment #95
effulgentsia commentedThe image effects conversion in this initial patch is not complete. As a follow-up, we'll want to convert each effect into a class instead of the 4 discreet callbacks they are now. But I don't think it's worth bloating this patch with that. As the image effects conversion in this patch shows, it is not a requirement that each plugin is a class (plugin definitions are mere arrays that can contain whatever information makes sense for that plugin). But I do think that at least in core, we'll end up wanting to use classes instead of collections of random callbacks to the extent that we can without compromising performance.
Comment #96
neclimdulYeah like effulgentsia said, we can make custom factories. I've always expected that to be the solution to micro-optimising the instantiation process. That's what factories are about.
The current patch does this but it also makes a lighter DefaultFactory. We talked briefly in IRC and decided to make the DefaultFactory just pass the supplied configuration to the constructor and made a ReflectionFactory that does all the call time reflection. If you don't want the configuration just ignore it, if you don't use configuration, you'll just pass in an empty array.
This should give a couple options for implementations in core and contrib while also providing some easy options for benchmarking and review. Enjoy!
Comment #98
neclimdul#96: plugin-system-1497366-96.patch queued for re-testing.
Sorry for the noise, tests pass locally so trying this again to make sure its not a hiccup.
Comment #100
dries commentedHigh level review
Overall I feel this patch still adds a lot of complexity. Overal, it is well architected, but it doesn't take away from the fact that it is a lot of code. On the flip side, it also provides a lot of flexibility and re-use. For example, in Drupal 7 we only have "hook discovery". With this new system, we open ourselves up for many more discovery mechanisms to be implemented. This has advantages and disadvantages. I will say that I have not seen this level of abstraction/generalization in other platforms like Java. It is going to be fairly foreign to developers coming from other worlds. There is not an easy answer, but I'd encourage us to keep looking for simplifications and to challenge ourselves if this level of flexibility is truly needed or best for Drupal.
In general, I think the naming/terminology could use some work. It is often overly verbose compared to what I'm used to in the Java world. I included an example in the detailed code review below.
More detailed review
I don't fully understand the Derivative work yet. It is very abstract and somewhat wonky. I'm thinking it may be useful to remove the Derivative stuff from the initial patch and to bring it back when we start the block work. Like that we have a concrete use case to look at. I see there is a test but it doesn't really help me understand it. Long story short, I think the Derivative stuff needs more work on documentation, terminology and real use cases.
The ReflectionFactory does not seem to take into account that there can be multiple constructors with different arguments. Maybe PHP classes only allow for one constructor.
I feel like we are going over the top with the naming.
I'd call this 'Plugin' instead of 'PluginAbstract', and I'd call 'PluginInspectionInterface' 'PluginInterface'.
I don't think 'Inspection' is an appropriate name for a base class that provides some simple setters and getters.
Can we not call this 'PluginInterface'? The Inspection seems both unnecessary and somewhat misleading.
I'm not super fond of the names here. While the difference between 'createXXX' and 'getXXX' is clear (factory vs mapper, new vs reuse), it may be too easily overlooked by developers. I can't think of better names though.
This can only be CMI-fied after CMI does not require database access.
I like the use of the decorator pattern here. It provides very elegant decoupling and re-usability.
We should add a @todo to remove the image_effect_definitions() function. It's too small of a helper function now.
OHG, this is a terrible, terrible path that is about to turn off a lot of developers. We need to do some path clean-up in a separate issue. Not related to this issue.
Comment #101
cosmicdreams commented@Dries can you be more specific about why the path is terrible x 2, how the autoloader should fixed in order for the path to be improved, and what the perfect path should look like?
Comment #102
pounardPHP method polymorphism is based upon optional parameters, so it is also the case for constructor. PHP allows only one constructor per class.
Comment #103
moshe weitzman commented@cosmicdreams - the path is terrible because it has so much repetition. It has
2x modules
2x plugin_test
4x test
3x plugin
Also, despite all the abstraction and complexity in this patch, we aren't addressing a known, long time issue. The image styles system is *still* owned by system.module. Wouldn't it be wise to make plugins into first class extensions like modules and themes? An extension class which gets subclassed into modules/themes/plugins sounds wise to me. I'm sure drupal.org could be fixed up to support that by the time D8 goes into alpha.
Comment #104
dries commentedRe #101: let's have the path discussion in #1469102: Gather feedback about DX of Drupal\user\SomeClass existing in deep directory core/modules/user/lib/Drupal/user/SomeClass.php. It should not be tackled in this patch.
Re #102: if PHP only allows for one constructor per class, than there is nothing wrong with that code. Thanks for clarifying.
Re #88: catch, the image_hook_info() function is now necessary because of we are now using HookDiscovery. It will call 'hook_info'.
Comment #105
cosmicdreams commentedDoes the above mean that we are postponing Plugins and further work of Blocks Everywhere until we implement an alternative naming system for PSR-0 autoloaded libraries?
If we cleanup this issue in regard to the other changes that have been identified can we still get this committed even though it implements PSR-0 naming standards?
Comment #106
eclipsegc commentedyeah, so the awfulness of that path seems to have more to do with the testing framework than it does PSR-0, it is complicated in part by PSR-0, no doubt, but definitely a separate issue. I would love to see that path be nicer too.
@Dries,
With regards to Derivatives, we would very much like to see it go in in this patch. Neclimdul, effulgentsia and myself have discussed this point, and we're willing to concede it if need be, but a few thoughts from my perspective at least.
1.) If documentation is the problem, then I still consider much of this patch as needing better documentation, so I can completely agree with that.
2.) If lack of an implementation is the problem, then I'll point out that derivatives are leveraging the decorator paradigm just like the cache decorator, and that this doesn't add complexity to any implementation that doesn't actually need derivatives.
3.) Finally, Blocks is not the only implementation that might benefit from this, and the hope was that it could go in with the plugins patch in general, and that other developers might begin using it and helping to streamline its flow further.
In short, we held this entire patch up for derivatives because we felt like other subsystems could utilize this as soon as it landed, removing it until blocks have landed defeats a lot of the method in the madness here and could delay future improvements that Derivative might get by being available sooner. Now that we have it, I'd much prefer to see it go in with the rest of the system if possible. If this can be done through better documentation, then I will be happy to spend my tomorrow purely documenting this patch, and derivatives in particular, further.
Eclipse
Comment #107
neclimdul@dries Thanks for the extensive review. Some good thoughts and we should figure out how to sum up some of the future paths you outlined. I guess @todo's will probably do.
As far as the removal of derivatives because, I'm not very keen on this as a lot of work has gone into getting them to where they are. I can sympathise though with the difficulty in understanding them because its a complicated problem, the docs are still very terse at best and non-existent in the common case and the tests are abstract. However, they end up being pretty important to a lot of implementations and I'd prefer we make the push to document and start educating people now on the problem they solve if possible. If we don't we're going to put it into dependency limbo on which ever system needs it first. I also don't want to shove it down the communities throat without understanding what we're getting so if removing them is absolutely what we have to do to get this in I'll accept it.
So now I'd like to address the comment about abstraction and looking for simplification. TL;DNR I think we're addressing a problem most of the world doesn't have at least at our scale leading to some extra complexities.
As far as code and concept simplifications, we've spent the better part of a year, some legendary g.d.o discussions, and some epic sprints getting this down to its bare minimum so I'm not sure there's a lot to do there. Each object ends up having a very fine tuned task that matches real world cases and I think that is well demonstrated by how the implementations provided where able to pick and choose to optimise specific parts for their usage while barely interacting with the original code. In fact I think it generally cleaned it up.
As far as complexity at a higher level of whether a system like this is even needed, I think the answer there lies in the sort of pluggable interaction that is sort of the most novel and core part of Drupal. And by this I don't mean turning on a module and having some functionality, I mean turning on a module and having new functionality show up in another system without that system knowing anything about the new module. For example, Views exists, years later I decide to make a new field type, I can integrate at a deep level with it with a minimal amount of code. We've done this for years though form alters and hooks and api hooks and other weirdness. The plugins provided here are the distillation of the tools and concepts needed to support a very common part of that interaction along with the experience ctools has formed solving some more esoteric and complex versions of the problem.
Those tools mostly boil down to:
So that a big response to a single sentence but I hope it explains why I would actually warn against trying to take anything else to the chopping block and why we've gotten to the state we're in. We have refactored several times taking bits out and putting things back end and this is basically the minimum viable product IMHO.
Comment #108
neclimdul@moshe I think making plugins first class citizens requires some serious thought but I also can't think of anything that's stopping it. In fact, that's basically how cache plugins work now. But then image effects come from hooks so are provided by modules exclusively. So having first class citizen on D.O could actually make things pretty confusing so we should be careful and have a full discuss about that in a separate issue.
And that's the correct description of what's happening with the hook_hook_info. Image effects where pretending to do this before with a straight include, this just opened up the functionality to other modules and uses the correct core mechanism as part of using a standard hook plugin discovery.
Comment #109
sdboyer commented@Dries, et. all - i want to take a stab at clarifying derivatives.
The must-have case
while there are many interesting things for which the derivatives pattern can be used, many of those cases can be equally-or-better served by taking another approach that does not require derivatives. i don't know how good we've been at delineating between these cases when discussing them, which has only muddied water that's already well on its way to colloidal suspension status. so, there is (at least) this one essential case for which derivatives are the best pattern:
that's abstract, so let me unpack it with an example. yes, it's blocks, but i'm hoping this illustrates the principle well enough.
first and maybe most important is that this case only applies if we are building a UI. this means that the traditional examples we've talked about with plugins (e.g., cache backends) are NOT useful examples for thinking about derivatives. so, don't :)
consider the menu trees - "Main menu," "Management," and the rest. core provides some, modules provide some, and users can create their own. there's no way for the author of the block plugin that provides the menu listings to know beforehand all of the menus that are out there. without derivatives, that plugin cannot expose individual "blocks" for each of the menu items. it can only present a single block to choose from, which the user then configures to be tied to a particular menu. (that might even count as a regression, as we currently provide a block per menu).
with derivatives, however, the single plugin can multiplex all of the menus known to the system, and present each of them as first-class options in a UI. this has nontrivial UX implications. i've hacked up Panels' Add Content modal to demonstrate. note that i've removed the overall 'add block' UI, which is being hotly discussed, as the overall context into which these items fit is immaterial - what matters is how smart the plugin can be about providing information to the UI. i've stripped it down to just the list of block(s) the user is choosing from to add. (remember, both of these cases can achieve the same functional outcome).
With derivatives
with derivatives, the single block plugin can show individually selectable block items for each of the menus known to the system. it reuses the names of the menus for the block name, and reuses the description text for the menu as the tooltip.
Without derivatives
without derivatives, 1 plugin must equal 1 item in the list. so we can only show one block item for all menus, and then need to rely on a select list on a subsequent configuration page for the user to decide which of the available menus to use. the only way to achieve the derivatives UI would be to use code generation to dynamically create (which entails read, update, delete) plugins for each of the menus.
the big UX fail, though, is that the derivative-less plugin now must hardcode the user-facing text itself. and the very best we can hope for is wording that succinctly describes the content of the block with respect of its overall role in Drupal's complex architecture. that, in my experience, is one of the biggest fail-piles we've run into with Panels: reliance on wording that more or less necessitates the user understand the underlying mechanics in order to make a correct choice.
Background
architecturally speaking, there are two things that ctools primarily used derivatives for (we call them 'children' there):
there are some notable exceptions - page_manager's page.inc, for example, is itself an entire subsystem written as a complex plugin + children - but in terms of general architectural patterns, the two bullets are mostly it. the first case is basically invalidated by going OO - inheritance is a far more elegant, language-native way of sharing that code.
the second case is where some of the muddiness comes in, though. sometimes we might use derivatives to solve a problem like the above blocks example, but just as often we'd use the derivatives pattern to invoke other systems' discovery hooks. now that plugins are going into core, there should no longer be any 'bridging' layers to other systems' discovery hooks, as those systems should now be doing that natively. i'm guessing that people have intuited that part of the use case is going away, and since discussions have mostly focused on non-UI plugins and/or ones that do not draw so heavily on user input, it's been easy to lose track of the fact that not ALL of the use case is going away. hell, i forgot about it this morning when mulling this over; EclipseGc had to remind me.
finally, let me just reiterate EclipseGc's point from #106:
it is clear to me that this use case is essential, even if we may not get to it for a little while. however, since we've adopted the decorator approach, there is no additional cost to letting derivatives in with the initial patch. we might find a more intelligible name than 'derivatives' later, but the pattern itself won't change.
in fact, given how essential derivatives can be to some cases (and still at least useful in others), i would say there's more risk in NOT including in the initial patch. people will learn plugins without derivatives, potentially implement things awkwardly that should've used derivatives, then have to refactor them later. better to do it all in one fell swoop.
neclimdul also suggested that we maybe refactor the derivative tests to use some dynamically sourced user data, such as the menus in the above example, in order to make the test more illustrative. would that help?
Comment #110
sdboyer commentedor, put more eloquently:
Comment #111
yched commentedPluginIntrospectionInterface -> PluginInterface gets a +1 from me, as I already expressed in #1540206: Allow self inspection on instantiated plugin objects.
I don't see the need to support the case for "plugins that would *refuse* to have getPluginId() and getPluginDefinition() methods".
PluginAbstract should be called PluginBase rather than Plugin, according to #1567920: Naming standard for abstract/base classes
Comment #112
neclimdulI sort of hinted at this in the linked issue but I didn't use PluginInterface because that implies that its something that plugins /must/ implement but its something plugins /can/ implement to be more useful in most cases. Cache backends are exactly the case of a plugin that will probably never implement this interface and furthermore there is nothing in the plugin system that actually makes use of the methods in this interface. So there is literally no requirement for a plugin other then it being a class. Because of this I tried to name it something else that was descriptive of what the methods where providing which is inspection into the code and state of the code that instantiated the plugin.
I've been waiting for the Abstract/Base issue to finish up to change the name.
Comment #113
pounardI think this abstract the #110 post very well
Comment #114
effulgentsia commentedBy the way, for anyone "follow"ing this issue, you may also want to subscribe to all issues in the sandbox project, where we'll likely be discussing further details on how to get this core ready, if you want to participate in that.
Comment #115
dries commentedThanks Sam, for your comment in #106. Your explanation helped me better understand the need for Derivatives. Somehow we should take some of the information in your comment, and turn it into documentation for the Derivatives system.
Based on the additional feedback from both neclimdul and EclipseGC, it is clear that the team behind Plugins believes it cannot be simplified further. I'm not I fully bought into that but I'll give this patch some more thought/review. Stay tuned.
Comment #116
dries commentedI looked into the Derivative work some more as I want to fully understand it. I made progress understanding what it does. Here is some more feedback:
It think the name
DynamicPluginwould be better thanDerivative.Based on what I know, right now, it helps me to think of it in terms of
StaticPluginandDynamicPlugininstead ofAbstractPluginandDerivative. The nameDynamicPluginhints at when I'd want to use this plugin which improves discoverability.I think these methods are a good examples of how things can be simplified. Let's take the menu blocks as an example. My understanding is that we'd have something along the lines of:
menuBlockLister.getDerivativeDefinition(42). I think this could be simplified tomenuBlockLister.getDefinition(42)or evenmenuBlockLister.get(42). Using the word 'Derivative' in that API function exposes complexity that is often not necessary to understand.Similarly,
getDerivativeDefinitions()could begetAll(). Example use:menuBlockLister.getAll(). It is pretty clear that that would return a list of all menu blocks. I don't need to know that these are derivatives. UsingmenuBlockLister.getDerivativeDefinitions()instead makes me wonder what this is all about, what derivatives are, etc, etc.It would be really helpful if we could use something more meaningful here. The current examples are cute and funny, but don't make it easier for people to understand how Derivatives work.
Comment #117
neclimdulAwesome. First of, when I saw "simplifications" I read take things to the chopping blocks which is probably evident from my comment. Thanks for taking it the other way. :)
I have some reservations about the DynamicPlugins name because when I read dynamic I'm thinking does something dynamic when it runs not defined by a source of dynamic information. Its something worth think about though especially since I'm heavily biased by experience.
You're totally right about derivatives in the DerivativeInterface method names. Its fairly clear to me comparing it to DiscoveryInterface that this was done to distinguish the methods from getPluginDefinitions and follow a similar pattern. I think get/getAll is too far as it doesn't tell what you're getting. Would just trimming down to getDefinition(s) work for you? Its a good thing naming things is easy.</sarcasm>
Totally, We keep saying that I'm not sure why there is not an issue for this. Wait... now there is! #1638050: Provide real world values for derivative test
Comment #118
eclipsegc commentedOn the topic of naming stuff, I'd prefer we not name it getDefinition(s). If we're going to rename it (and I'm completely ok with us doing so) I'd prefer getDerivative(s) as this won't even use the same words as getPluginDefinition(s) and will hopefully be a little less confusing, although I see there's a method by the same name in the DerivativeDiscoveryDecorator so... perhaps I'm barking up the wrong tree.
Also, as a side not to that, the DerivativeDiscoveryDecorator is the only one who should ever have to actually call getDerivativeDefinition(s) and only the most complicated of plugin needs would want to bypass that and call getDerivativeDefinition(s) manually. I don't know if that changes the perception of these methods at all, but they're not likely to need a developer to actually call them regularly, the plugin system tries to hide the details of that from the developer and leave them only needing to write the actual derivative class that will inform their plugin.
All that to say I am +1000000 to renaming this if we can find something better, the bigger problem is actually naming it better.
Eclipse
Comment #119
aspilicious commentedEclipseGC I don't think you got the point Dries raised. Derivatives sounds super artifical... He suggests to drop it and you say ok lets rename but still use derivative everywhere. At some point developpers (all of us) should step back at their code and think: "Will people understand this when looking at the docs and the names of the classes/functions". And sometimes we realise it's not the case and than we should use names that maybe are not 100% technically correct but help 90% of the other people. It's a trade off we must make. And developers tend to use the technical correct names and others should pull us to the other direction untill we are all happy ;).
Thats just my opinion.
Comment #120
eclipsegc commentedI think you misinterpreted my comment (and I can see why). when I said getDerivative(s), I should have appended "or equivalent". The point I was attempting to make was that I didn't want the method names to be getDefinition(s). I'm completely ok with other suggestions here, and I'm not really hung up on the word derivatives.
Comment #121
effulgentsia commentedFor anyone wanting to discuss alternate naming of "derivative", please comment on #1645828: Find alternate terminology for "derivative" or clarify why derivative is best.
Comment #122
dries commentedI spent some more time on the plugin system with Alex and Angie. While I like what we have done, I still have issues with the developer experience. I'd like to talk about how we can evolve the APIs and terminology so that it becomes easier for end-user developers to read Drupal's code.
Let's take a look at the cache system changes in the patch:
The good news is that we got rid of a custom plugin system (i.e.
cache_get_backends()). The bad news is that readability and discovery of the code regressed:get('cache')->getPluginDefinitions()isn't nearly as self-explanatory ascache_get_backends(). I think everyone will agree with that.Ideally, I think we'd be able to write something along the lines of:
This code is self-explanatory and doesn't expose developers unnecessarily to the concept of "plugin definitions".
Same thing with
image_effect_definitions(). Here is what the current patch does:Again, great that we remove that much code, but
$plugin_type->getPluginDefinitions()is just too abstract. Instead, as a developer, I'd really like that code to read:In the proposed code, it is clear that I have a library of effects, and we're returning a list of all the effects in the library.
Both of these examples deal with getting a list of all definitions (i.e.
getPluginDefinitions()), but the same is true for creating an instance (i.e.getPluginInstance()). Let's look at an example.Taken from the patch:
Instead, I'd propose the following:
The proposed example provide a better API; it is more self-explanatory and more intuitive, without actually taking away from the flexibility of the plugin system.
In other words, while I like what we have developed, I really think we should take a step back and look at it from a end-user's point of view. The end-user in this case being a developer. If we can accomplish this, I think we have built a powerful system that properly abstracts a lot of the complexity.
Comment #123
neclimdul@dries So I'm a little nervous and unhappy at the prospect of re-architecting the system after over a year of research, design and development by numerous people. I also think I actually disagree with most of #122. Because of that and the fact that the discussion keeps moving further from the current architecture with each post, I've stashed the longer response I wrote and think we should wait to discuss this in our meeting we have planned next week where we can more effectively hash out the details.
Comment #124
webchickFWIW, this is exactly why we can't research, design, and architect systems off the grid for a year+ :(
Comment #125
yched commented@webchick : this wasn't exactly off the grid (not in the sense the initial Field API D7 patch was 'off the grid' back then) . It's been in the open in a dedicated sandbox and issue queue where various people could and have provided feedback and refined the architecture for the last six months.
Comment #126
neclimdulFor the record. We made every effort to engage the community and have then come work with us.
Comment #127
eaton commentedJust out of curiosity -- given the amount of d.o. and g.d.o. discussion that's gone on around it, the active back-and-forth between different groups with different preferred approaches to the plugin system, and the publicly accessible, hosted-on-d.o. nature of the development work that's been going on, what would constitute "on the grid?"
Not being snarky, just think that would probably be a good discussion to have in a secondary thread. With a community as large as ours it's impossible to actively keep everyone engaged in a year-long discussion. If these steps have been insufficient to maintain transparency, we need to figure out what's required.
Comment #128
dries commented@neclimdul Before we talk about re-architecting anything, do you agree or disagree that the proposed API changes in #122 would simplify things for developers? (Some of the changes could be simple search and replace operations.)
Comment #129
sunAs a rather silent follower of everything, it actually appears to me that we can still investigate @Dries' suggestions post-commit — they do not actually touch the fundamental architecture, but rather focus on the developer-facing interface instead.
I may be mistaken, but it looks like what @Dries basically suggests is to introduce an additional abstraction layer/class/API in order to expose a concept of plugin-type-specific "Library" to developers, which may be used instead of low-level plugin definition methods. It doesn't look like that would actually change the fundamental design.
That said, because that's not really clear to me, let me do a run-down of what changes @Dries seems to have in mind:
(Note: I'm putting a lot of words into @Dries' mouth here without actually asking him. I'm trying to dissect what he actually tried to say. @Dries should correct me where my interpretation is wrong.)
new Effect;does not clarify to the developer that he's actually dealing with a base plugin for image effects, which provides a library of registered effects, instead of a single plugin instance. He therefore suggests that such plugins use a more conciseEffectLibraryclass name that clarifies the abstract base nature of the plugin.His suggested terminology would mean to use it for all abstract/base plugins; e.g.,
CacheLibrary.drupal_container()->get('cache')does not clarify that the container is returning some kind of a cache backend library and factory for cache backends/plugins. He therefore suggests to register a service name that clarifies what you actually get back.I'd personally like to amend that and would like to see a common
plugin.prefix for all plugin system services registered in the container; e.g.,drupal_container()->get('plugin.cache'). As a developer dealing with the DI container, I'd like and need to know when I'm dealing with a plugin system based service and when not, since I'd expect all plugin system based services to return the same API, but for all other services I'll have to check what their individual API is.Combining this with 1), a DI service name of
plugin.cache.libraryreturning an instance ofCacheLibrarywould ultimately be self-descriptive.->getPluginDefinitions()just seems to be too verbose for @Dries. He therefore suggests to replace it with a short->getAll().->getPluginInstance()equally just seems to be too verbose for him. He therefore suggests to replace it with a short->get().->get()to take a single identifier for the specific instance to return instead of an options array. I'm not sure why we're passing an array there.I originally wanted to state that we need to pass an array, since that is the plugin's actual configuration, but I think I was wrong with that thought, since the instance retrieval/selection and passing configuration into the particular instance are probably two separate things; i.e., more along the lines of:
Note: I did not actually check how plugin config/options are handled in the code, so I might be totally wrong here. That said, at this point, I've the impression it makes sense for me to actually stay on the high-level API/DX discussion, without diving into the actual code, since that helps (me) to validate how intuitive the overall system is.
Honestly, I don't see any of these issues as hard blockers for this patch. As mentioned earlier, I'd much rather prefer to see this landing earlier than later — on the grounds that we can still revise individual parts in follow-up issues. I followed all of the sandbox issues and can confirm that all architectural discussions happened open-minded and with a core-queue-alike feedback and peer-review process. Additionally given that all involved people who worked on this have years of experience in this field, I have no doubt at all that the proposed architecture and code is the very best we could possibly come up with. In short, it's not November Rain yet, the overall architecture seems to make sense, and as soon as we work on this further within core and integrate it with other major D8 changes, we'll find issues that need to be resolved in follow-ups anyway.
Comment #130
neclimdulIn a word no. I think that how we embed plugins in the container could probably improve. But I think the changes outlined to the system itself generally cause a loss of clarity in responsibilities and confusion of the concepts outlined in the summary that are detrimental to developer experience.
Comment #131
eclipsegc commented@Dries,
I agree that most of what you've done here is totally just grep work and organizing calls to the api a little differently. We've seemed to favor the function()->method()->method() notation in our work whenever we didn't need some transitory object later in the process. I see what you're suggesting and agree that you've named functions in such a way that it should be easier for the average developer to understand what's going on. With the exception of the renaming you're wanting to do on method names, this seems more a personal preference in the implementation, there's nothing that keeps the implementation from being done the way you've illustrated now, and I don't honestly have a problem with it. My bigger issue is what we actually name the various methods, and I think that our current naming schema was picked with some precision in this particular case, because it's plugin definitions you're getting, not plugins, not plugin types, not configuration, but definitions, and we really felt there was some potential to get confused. Also, with things like caching, I've seen discussions of get() methods there before, I I could see it being very confusing if we have multiple classes in the same workflow with the same method calls. We erred in favor of specificity here, and I still feel very inclined that direction. More generic method names are something I generally dislike as a developer, and I guess I'm projecting that preference on fellow developers here.
Eclipse
Comment #132
eclipsegc commentedHaving cross-posted with sun a bit here, I want to clarify that getAll() and get() should correspond to getPluginDefinition(s) respectively, and getPluginInstance() is another thing all together (as is createPluginInstance()) and again, we were very meticulous in this naming convention so that there might be some obvious differentiation between these things.
Eclipse
Comment #133
neclimdul@sun
1) works for me
2) I could go either way. I'm not sure if the reason that's confusing is because we're not used to the new norm or if its actually true. Easy follow up though and if so go with something consistent with 1)
3) 4) I have a couple problems here I was hoping to just talk through with dries but here we go. ->get() on the type doesn't tell us what we get. It could be a configured and instantiated, a definition, something specific to the type, a factory, who knows. That leads us to getDefinition. I like this more but it could be used for a type definition ala ctools so not really my first choice. So now we end up with getPluginDefinition(). That's the logic that go me to the current function name.
5) You're falling into the confusion I mentioned. if get() is getPluginDefinition() then it does take a single argument because we're talking about a plugin definition. If we're talking about a key that identifies a instantiated plugin that's the MapperInterface's getInstance method(which is arguably confusing), and then if you're talking about options in terms of configuration information hopefully loaded from cmi that's passed into the plugin classes constructor that's FactoryInterface's createInstance method.
Personally I think you're right about the blockers. As I see it #1638050: Provide real world values for derivative test is the only real blocker and that's just me sitting down and implementing effugentsia's feedback. The component naming discussions in the sandbox can be moved to the core queue and marked as follow ups. That said there are strong feelings about the names of functions and DX and I feel like some confusion still about the responsibilities and components of the system. I don't want to just shut up even if I do want to resolve it.
Comment #134
aspilicious commentedReread this again...
1) You can *get* everything
2) Thats why we choose getPluginDefinition().
That doesn't make sense... If it returns *anything* than getPluginDefinition is even worse because sometimes it wont be a pluginDefinition.
If it does always return a pluginDefiniton get is ok too because than it will return always the same...
Comment #135
eclipsegc commented@aspilicious
the plugin type class (which is who we're calling through when you see getPluginDefinition() calls) can return many things, not that method itself, thus the specificity as to what you're getting. (i.e. this method will always return a plugin definition)
Eclipse
Comment #136
merlinofchaos commentedOn rewriting:
Into:
There are only actually 3 changes here.
1) It splits a single deep nested method call into two lines and creates an intermediary variable that isn't actually necessary. I'm not quite sure why this is an improvement. It's two shorter lines, but they are functionally identical. We could achieve a better result by retaining a cache_get_backends() wrapper which would be just as readable before, but of course add a function call. That also has the downside that it hides an implementation detail that is actually valuable because it's a common pattern people will use.
2) It removes detail from a method named getPluginDefinitions() and calls it just getAll(). To a developer not familiar with the system, I don't think it's actually clear what it is you're getting here. The method isn't descriptive, and the plugin system can return several different kinds of data depending on how you need to access it. There isn't one Overall Super Duper Way of accessing plugins because the overall set of use cases are very broad. The intent to not expose developers to plugin definitions is not one I agree with. Plugin definitions are the equivalent of info hooks and we certainly don't hide that information from users of entity systems. It's pretty mandatory data to do anything with it.
3) It renames the 'cache' namespace in the DIC to 'cache.backends'. I don't actually have an opinion on this, other than potential namespacing concerns but I don't know if that's an issue here.
Likewise, I have the same issue with the image comments. I think renaming Effect to EffectsLibrary makes some sense, potentially (though I'm not familiar enough to be completely certain). However, hiding the detail that what you're getting is a list of plugin definitions seems like we think our developers shouldn't know what plugins are. In my world, developers work with dozens of different plugin types. And that's just for the developers who've embraced CTools. If this system is in core, plugins are going to be everywhere. In my opinion, hiding implementation details about them is only going to confuse developers, not aid them.
Meanwhile:
$cache_objects[$bin] = drupal_container()->get('cache')->getPluginInstance(array('bin' => $bin));Dries proposed to change that to:
This is actually actively wrong. Why? The array being sent to getPluginInstance is configuration for the instance; the fact that the configuration has only a single key may be a bit confusing here but I assure you that many many plugins will require much more complex configuration than a single key. That simply isn't going to function except in very limited cases.
I am not opposed to a change from getPluginInstance() to createInstance() -- that feels like a reasonable DX move to me but I would like to hear more about the decision on that because I believe this has already been considered.
Comment #137
neclimdul@aspilicious I think you took my comment the other way. getPluginDefinition(s) only returns plugin definitions. get(), based soley on its name and existing on the Plugin Type tells me nothing and could logically return any of those options. I hope that clears up what I meant.
Comment #138
webchickMy comment in #124 was unfair and I apologize for it. It was frustration from these discussions when people not involved with the system look at it for the first time with fresh eyes and say "This is really confusing, I think it would make more sense to people like me if we did it this way instead." and people actively involved in its development say "Well, no. This is what we already decided, so we're staying the course." That's not exactly what's happening here, though, so I shouldn't project. A separate discussion on how best to handle widely-impacting subsystem architecture in a digestible manner given the size and scale of our community sounds indeed like a useful discussion to have, though.
I can somewhat channel Dries in #122. It's not about breaking things into more lines of code (that was done merely to separate the "stuff that's part of the DI crap" from "part that's part of the plugin system"), and the pseudocode shouldn't be taken as actual direction. It's much more about the readability/learnability aspect of the code: how closely that code resembles the task it's actually trying to accomplish, in terms of describing what the overall task is that's trying to be achieved.
Any mid-level PHP programmer can take a look at something like:
...and basically figure out what's happening there. There's a function called cache_get_backends() which returns an array of backend class names keyed by $bin; either grab the specific bin's cache backend class, or if not found default to 'cache', then instantiate a new class of that type in the $class_objects array.
On the other hand...
...is definitely not something that a PHP developer with no Drupal experience can make any sense of whatsoever. The drupal_container()->get('x') stuff is at least a common dependency injection container pattern used in other software, so once you figure that out you can mentally map that over. But getPluginInstance() exposes underlying architecture that's irrelevant to the fact that what the software is doing in English is "Grabbing the correct cache backend for the given bin." The PHP no longer reads like the English version of the code, and instead requires the reader to understand an extremely abstract, Drupal-specific concept to really grok what's happening there.
It's different from the info pattern, because the info pattern is defined somewhere else; it's not exposed to people who are reading the code in-line and trying to grok what it's doing.
The position of the plugin system folks is that these getPluginInstance() and the like things will soon be everywhere, and so this will eventually no longer be a weird one-off thing, and this will just be part of learning how to read Drupal code, like learning to read render arrays are. Dries is essentially positing whether or not it's a mistake to expose that level of implementation detail to the casual reader.
I think it's well worth getting a lot additional feedback from developers who did not work on this system, but will be expected to be able to consume it and conform to it, as to how usable it is from a DX POV. I've asked Kris to make a post to g.d.o/core to help facilitate this once some additional "orientation" docs are done. I also tend to disagree with the assertion that this fundamental question of learnability is mere syntactic sugar that can be drizzled on after commit. I think we need to sort this out in advance, because it's key to bringing more people on to help with conversions and other areas of the blocks and layouts initiative.
Comment #139
pounardIn fact, speaking with lsmith I realized how much using the right words is important:
drupal_container()->get('x')is not an dependency injection pattern, but a service locator pattern, the real dependency injection pattern assumes that you inject typed objects into another (typed is the most important word here). Then the problem is not true anymore because the developer knows exactly what he's manipulating. The case where you fetch the instance yourself by querying the container is not the way it's meant to be used, and it's sure is confusing for developers!Take no offense, this is just a note for putting the right words into the right place. I think that the plugin API is meant, later to inject the plugins into the dependents, and not the opposite way of doing thing: the dependent is not supposed to fetch the plugin. In that specific case, everything is claryfied by the instant, because the user (as in the end developer) will receive a typed instance he configured without worrying on how it got there.
I don't know if this is part of the actualy API, it sounds like Drupal will continue to use the DIC as a service locator because of the current architcture which is not heavily oopified, but I surely hope the final goal of this API is to inject, and not just allow fetching; case in which all those questions raised by Dries wouldn't even exist.
Comment #140
neclimdulThanks webchick. Its natural that 100 comments into an issue with a number of sub issues and all the pre issue effort there'd be frustration at late comments. I'm sorry I expressed them in such a way as to discourage discussion because I really do appreciate the feedback. I would appreciate if we had that discussion.
Comment #141
tstoecklerIn reading the last ~20 comments one thing in @sun's response/interpretation to/of @Dries' comment and also in webchick's comment stands out to me:
@webchick #138:
I totally agree with that. The thing that bothered me with that syntax from the start (but couldn't articulate until now) is that
does not tell you that this has anything to do with plugins. I would expect that
$whoAmIcontains information about cache backends in some form, similar to our currentcache_get_backends(). So thegetPluginInstance()comes out of nowhere for me, and throws me off.That is why @sun's (#129)
makes sooo much more sense to me, even though it is such a minor change. I now expect that
$whoAmIcontains information about plugins, which are related to caching. Even without knowing anything about our specific Plugin API, the word "plugin" implies there is some abstracted/generalized handling for this sort of (pluggable) information. And as a developer, the word "instance" is probably also known. So now, callinggetPluginInstance()totally makes sense! All the more so, if I know anything about our Plugin API, which, to a certain degree, we might expect of a Drupal 8 developer.So I think @sun's proposal to namespace all plugin types in that manner, even though it is trivial code-wise, would be a huge DX-boost on its own, irrespective of the other proposals here and maybe would alleviate some of Dries' concerns.
Note 1:
If we were to go with the proposed syntax I would actually propose
instead of
so we don't duplicate the word "plugin". I specifically wanted this comment to be about the container namespacing, though, in order to not discuss multiple bikesheds simultaneously. :-)
Note 2:
I realize that I am basically rephrasing/re-wording @sun and @webchick, but I didn't see this point pointed out specifically and in-detail above. I apologize if anyone feels this post is merely bloating and duplicating the discussion, that was not my intention.
Comment #142
fenstratBig +1 for that syntax.
Comment #143
effulgentsia commented@pounard, I don't think I understand what you're suggesting / asking, so here's some sample code that might help make this more concrete for people, especially new people coming to this issue per last paragraph of #138.
I'm gonna take aggregator module as an example here, because since it starts with "a", it showed up first in my IDE when I started looking for an example. It's a nice example, because it actually uses 3 plugin types. Just one simple module using 3 plugin types is an indication of just how frequently developers (including developers who don't necessarily spend a lot of time in the internals of core's subsystems) will need to work with plugin types and plugins.
The "before" example code below is a stripped down version of what the HEAD code actually is. It's enough to demonstrate what's essential in this issue, but if you want to study the real functions, they are aggregator_admin_form() and
aggregator_refresh().
For the "after" example code, I took the liberty of renaming what in #96 is
getPluginDefinitions()togetDefinitions()andcreatePluginInstance()tocreateInstance(). Also, instead of using a 'plugin' prefix for the "plugin type" objects in drupal_container(), I'm using 'plugin_container' as the prefix to make clear that the object is something that contains plugins, but is not a plugin itself. An alternate prefix could be 'plugin_type', but I think there was some feedback in the above comments about "plugin type" being a confusing term, so here, I'm exploring the term "container". None of these terms are necessarily final. In fact, part of the feedback we want is if/how to improve them.Before (HEAD):
After (what we'll want to convert to once the plugin system is in core):
Diff:
So I think the question is: how do some representatives of "typical" Drupal developers feel about the above change, and what (if anything) can be done in the "after" code to make it better?
Addendum:
For those of you who don't like the long chaining in the above aggregator_refresh() function, here's the equivalent code without chaining:
Addendum 2:
Some of the comments below raised concerns about the drupal_container() usage in the above code, because there is still ongoing debate in other issues on how we should really be dealing with dependency injection. So, here's a code snippet that shows the above code without drupal_container(). The point here is that aggregator_refresh() needs access to 3 plugin type objects (assigned to local variables named *_factory, because while plugin types are more than just factories, in this code, they aren't used for anything other than as factories). Whether that's "dependency injected", "service located", or hard-coded as in the below code is a separate issue than what you do with the plugin type object once you have it.
Comment #144
neclimdulSo, I could take or leave the whole container thing. I expected we'd just call cache() and it'd do some static caching or something. The service container seems a better way of doing it though so we went with it.
I'm also open to shortening the names where they make sense. Its the hidden architectural changes in some of the examples that i'm trying to push back on. I don't think the definition name changes makes sense though as I hope is clear. I do think the factory and mapper methods could be shortened. I don't remember what issues now but we moved from mapInstance() to getInstance() to getPluginInstance() to improve clarity. My personal thoughts. createInstance is probably better than createPluginInstance(). and mapInstance or resolveInstance would be better and getInstance is probably better then getPluginInstance. I think get is too easily confused though and we /do/ need to expose that aspect of the functionality to make it clear. Why to call that function instead of createInstance.
It seems obvious the former is exposing more complexities and is more confusing so maybe I'm not understanding what you're saying. We're exposing how the information is stored, that you have to look in the cache key to instantiate the default, man I just wanted a object to handle the bin i don't care about drupalisms like that.
That it is stored in the container is just a better, arguably more testable global. We are making the cache plugin type a service you can use to interact with the cache system. The type object is an object to interact with the cache system. Once you understand what the container is and that we're storing a cache plugin type object there its pretty straight forward.
And as a developer when I'm going through code in a system or even language I'm not familiar with and see some chained code, the first thing I do is look at the last method in the chain and try to resolve from it, its arguments, and the surrounding code what's going on. getInstance and getPluginDefinition to me solve this and are a better developer experience for me.
Comment #145
neclimdulThis got removed by accident from my last comment but the cache system is also a terrible system to use to review this. We probably should have left it out but its there specifically to show how we can deal with edge cases and that seems to have been lost in the discussion. We'd be much better off discussing the image effects which are a more vanilla implementation. Now I see a lot of comments have shown up so I'll try to catch up.
Comment #146
neclimdulRe: drupal_container->get('plugin.cache') I want to disagree in we're adding the same unnecessary concept dries was asking to remove. Also, plugin is not what we're talking about. cache is not a plugin its a plugin type. I'd either go with what I suggested of naming "cache" something more in line with what the system is if we're going to rename it or use plugin_type. I think container is confusing because we're pulling it out of a DI Container and we're not returning a container.
Re: the service question, normally in the service container you'd list all the implementations and request them. That's to say you'd do something like:
We've identified this doesn't work for a vast number of our systems though because of things like default versions, fallback implementations, etc. That's why we're interacting with the plugin type directly still.
Comment #147
Crell commentedI think there's an important historical and architectural detail here that pounard hinted at that needs to be made clearer.
The plugin system was architected well before we decided to pull in the Symfony2 DependencyInjection component. Much of its design was based on the idea that we wouldn't have a DIC, therefore the plugin system would be our next-best-thing for injecting at least parts of Drupal, for beginning the process of pulling apart our spaghetti, and for creating a "beachhead" for future work toward an injected future. (At least, that's a large part of my motivation behind it, as anyone who's followed my blog has probably figured out by now.)
Of course, then we went ahead and decided to go all the way to a high-end DIC now, much to my pleasant surprise. :-) Of course, that means many of the benefits that the Plugin system was supposed to get us we now have an alternative for, and we haven't fully thought through how the plugin system and DIC intersect. For some of the intended Plugin use cases, like pluggable password hashing, I'm not convinced that making them plugins is still the best course of action, and simply making a proper injectable object that we can stick into the DIC is simpler, easier, and more DX friendly.
Now, that's not to say that I don't still think that the Plugin system is a critical feature for Drupal 8, and needs needs needs to happen. Even for objects placed in the DIC I think it is still valuable in many cases, particularly for the standardized configuration support it offers. But the extent of things that need to be plugins is a bit smaller than it was before we had the DIC available to us.
Pounard's point from #139 bears repeating as well. Right now, the drupal_container() function is not being used as a DIC. It's being used as a Service Locator, or Broker. Now, that was to a large extent my original intent. I honestly didn't think we could get away with going all-out DIC objects, so a service locator was a good compromise step that gets us some, but not all, of the decoupling benefits we wanted. Then Drupal surprised me again, and it looks like in many places we are driving toward a full-on DI approach, which means that, if we do it right, extremely few developers will actually call drupal_container(), and we may even be able to remove it. I hope so, but that depends how much we get done.
That means that, in practice, there are three possible patterns, in decreasing order of how often we will want to see them.
1) A given object needs some object (which happens to be a plugin), so it specifies it in its constructor. It's then "someone else's problem" to figure out how to get it there.
2) A given object needs access to a plugin, but doesn't know which one yet. It therefore specifies a dependency on the object that will, when instructed, return a plugin.
3) A given object is passed the DIC, because it really doesn't know what it is going to need. It can then request from the DIC whatever it wants whenever it wants. This is the Service Locator model, and aside from Controllers (nee page callbacks) I don't think we'll want this to happen very much at all.
All of that is to say that the DX issue we're discussing here I believe should not, in practice, be a common case at all! (And if it is, I will be very sad.)
As an example, then, these mechanisms would correspond to:
Option 3:
Option 2:
Option 1:
In option 2, passing the cache factory into the object is the DIC's job, and the Foo object doesn't even know that a DIC exists. Wiring up the DIC entry identified by "cache" or "plugin.cache" or "plugin.factory.cache" or whatever we call it is a DIC configuration issue, not something that would appear in actual code.
In option 1, note that the Foo object doesn't even know which cache bin it's using. This is, again, a good thing. Writing up that it gets the "page" cache or the "filter" cache or whatever is a DIC configuration issue; just a somewhat more complex one, since we then need to code the factory logic into the DIC. The Symfony2 DI component though, has support for doing precisely that.
In fact, for a case such as caching we probably can wire up both cases: plugin.factory.cache is the factory itself, and then cache.page, cache.filter, etc. are DIC entries for individual cache objects. The Foo class (service?) can then say that it requires cache.filter... and that's the end of it. cache.filter is wired up to instantiate the filter object out of the plugin.factory.cache service. I don't know the full details of how we'd implement that off hand, but that is certainly an option.
Which plugins we put into the DIC as individual entries (like cache.filter) and for which we just put the factory into the DIC is a decision we should make on a case by case basis.
Really, then, my point (yes, there is a point) is that the DX issues we're discussing here, while valid to discuss, are a red herring; we want to optimize for options 1 and 2 above, primarily, and my sincere hope is that code calling drupal_container() is an extreme legacy edge case. Playing around with how that call chain would look is not a good use of time, because that call chain will not be used very often.
All that said, I am 100% OK with exposing the basic concepts of plugins to module developers (as webchick said above, if you don't understand info hooks and arrays you're not going to get very far in Drupal either), and in this case favor more self-descriptive method names rather than generic get() methods that leave you guessing (or tracking down doc blocks) as to what you'll actually get back. getInstance() is much more sentence-ish and self-documenting than get(). Also, createInstance() is simply incorrect, as in many cases if a plugin has already been created a new instance won't be made. (Eg, we'll only have one instance of the cache.filter plugin object period.)
Comment #148
neclimdulI was talking to crell on irc after he posted this. By CacheFactory in option 2 he meant the cache type object and by Cache in option 3 he clearly meant the CacheBackendInterface which is not in the patch but already in core. He just skimmed the patch and responded to the container points. FWIW I think he is correct. The service stuff is mostly used as a convenient more testable global in this patch and we'll learn to use it better.
Comment #149
eclipsegc commentedlook, caching was done within the DIC so that we'd have consistent access to it. After drupal_container()->get('cache') has been called once, that same command returns the same object instance over and over and over again. That's not necessary for most plugin types and won't be the way you will typically see this. Typically this would be more likely to be seen like:
Can we stop talking about the cache example and confusing the discussion with DIC?
Eclipse
Comment #150
effulgentsia commented#42 explains the 2 different kinds of plugin use-cases. #147 suggests that we may want to move the 2nd kind of use-case (e.g., cache backends) out of the plugin system and make them into direct services in Symfony's DIC. This is something I had suggested back in #1519376: [Meta] Extend Symfony's service container and use that for simple swappable systems and plugin access and discovery, and at that time, it didn't pan out due to our eventual goal of wanting to compile Symfony's DIC. However, we can certainly resurrect that idea if we need to. In any case, I'd like us to focus the current discussion on the #42.1 use-case (plugins instantiated a potentially open-ended number of times with each one getting a potentially different configuration or context). To help bring clarity to that, I updated #143 from
createInstance($fetcher)->fetch($feed)tocreateInstance($fetcher, array('feed' => $feed))->fetch().As #143 shows, there are 2 fundamental methods to a "plugin type": an admin form calls
getDefinitions()and the code that needs to use the plugins that were selected in that admin form to do something callscreateInstance().In #96, plugin types have two other methods as well (not used in #143) called
getDefinition()(in situations where instead of all definitions, you only need the definition of a single known plugin) andgetInstance()(to handle situations like cache backends where you do reuse the same instance). In #100, Dries also commented about having both getInstance() and createInstance() as being awkward. One way we can deal with this is to move the getInstance() use-cases like cache backends out of the plugin system. Another way we can deal with this is to pick one name (e.g., getInstance()), merge the factory and mapper interfaces (e.g., make the mapper into a factory decorator), and thereby hide the detail of whether getInstance() returns a new object or reuses an existing one from the caller.While I'm very interested in how we want to deal with the above paragraph, I think it's best if we focus for now on just the 2 methods getDefinitions() and createInstance(), and ask if it's understandable that a single "plugin type" object has those 2 distinct things it does, how we can make those names clear and approachable, as well as how we can make the whole concept of a plugin type (or container/lister/whoozywhatsit) clear. Essentially, we have a registry and a factory rolled up into one object, and even someone as smart as Dries is getting tripped up on that.
Comment #151
cosmicdreams commentedFriends,
We need to timebox this discussion. We can't endlessly discuss how we're going to name these things and the effects of those choices. We need an explicit deadline and commit to that.
Comment #152
neclimdulThanks effulgentsia. I missed that point and I think you did a pretty good job of explaining how we got to the two methods.
Just to help clarify plugins are a tool for a lot of use cases not just DI. The methods are there to be used as make sense for your plugin system. Because of that createInstance() is correct and I'd like to enumerate the role I see the 2 methods having in interacting with an emphasis on DI.
createInstance()
createInstance() is an interface for direct access to the factory for when you expect you will be creating an instance. This is specifically for when embedding in a DI Container or when manually controlling when plugins are instantiated. That's to say, when the logic for instantiating the plugins is not in the mapper(also for the mapper itself to call). A fresh example done off the cuff since I've not actually looked at what it would take to do password plugins:
getInstance()
getInstance() is for when you have any logic around instantiating plugins. This is most commonly going to be fallback or default plugins. This is important to DI because as effulgentsia was saying, you can't put this sort of logic in a DI container. At least not in a container that can be compiled. You need a method to handle it and that method is getInstance(). Embeding this in the service container is definitely where our roughest edge is because it is a drupalism(though I'll argue with valid use cases) and it will need time to shake down and smooth over but I think that's not blocking the API itself.
Why not have one method do both?
So I think the follow would probably be can't different plugins just use getInstance() differently. I think not because a) the signature is different for the methods b) the developer expectations are different and c) you can use both fairly effectively in different parts of you code. All that means we need both methods at the same time.
Comment #153
neclimdulYes to timebox. I'm already struggling to resolve how the discussion can be resolved to a patch. I will discuss this with Dries(next week when we have a call scheduled) and we'll see if we can resolve his points or if we leave it open and timebox it or some hybrid of the two. There are post commit things we need to move on to (blocks, other systems, etc) and we need to get this in so we have time to do them properly before freeze. Naming changes can, as I understand it, happen for several months after that if we come up with good cases. The container call I think is the remaining point so I'd be happy if we narrowed the discussion to that for the time being.
Comment #154
effulgentsia commentedOne other thought I'll bring up for discussion. Maybe the way in which we're rolling up these two things into one "plugin type" object isn't good? For example, instead of:
Maybe we want:
I think the reason we currently have the concept of a "plugin type" object that wraps these two is so that in cases where we want to inject that object rather than "service locate" it from drupal_container(), it's just one object to pass instead of 2. I think another reason is that some plugin types may want additional custom business-logic functionality, and a specific "plugin type" class/object can be expanded to have those methods too. But, despite those reasons, I wanted to get the above code in front of people for discussion.
Comment #155
neclimdulThis is why we roll it up into a type. That and because we want to provide a best practice sort of place where types can specific logic like putting defaults on plugin definitions.
That said, you could register the type object in each of those locations if it makes more sense and soft enforce the individual interfaces. I think its a bit weird but I understand the logic behind it. Also, if your type is heavily integrated with the container and you don't have that type logic you could use the container to fetch the components for your type and use them directly out of the container or something. That'd be a divergence from the best practices we try to wrap into the type but there's definitely nothing stopping anyone from doing if it makes sense.
My point is its all possible without changing the system we have and "The goal of the plugin system is to get everyone into the same chapter, not necessarily onto the same page."
Comment #156
pounardJust some questions bothering me, and to be sure I fully understood some details (totally not linked to the timeline problem raised by Dries notes):
If that so, using Zend Framework 2 DIC as comparison point, they actually implement something similar (but a far more advanced and flexible): in their DI you can put definitions (type = class + dependencies definitions), and configure instances (instance = alias = name + type + some specific options and dependency overrides). This is what they later inject into the components (each component is a defined type (or alias, the same), and each dependency is too (either a type or an alias)). I think that SF2 DI behave more or less the same (I'm not sure from the configuration standpoint, but the goal is to alias configured instances of components, then inject them).
I understand why you want to keep this API decoupled from DI, but in the end it looks like its behavior and business is almost exactly the same as the DI component. Did you think about a way of proxying plugins in a generic fashion into the DIC? (ZF2 can have multiple layers of DIC so you can actually mix things up, at least it looked like last time I checked the latest beta, but I don't know for SF2).
Off topic question: I didn't catched if the plugin API handles dependencies or not?
Comment #157
eclipsegc commentedok, again, WHY are we discussing DIC? The plugin system actually doesn't have any relevant ties to it.
DIC is especially good for saying: "I need X, and X is dependent on Y and Z, please instantiate or reuse existing instances of Y & Z and then give me an instance of X, or if X is already instantiated give me that." The plugin system has nothing to do with this. DIC was used for the cache plugin type so that it would not need to be loaded multiple times through out the system, it has nothing to do with the broader topic of plugins in general. We should really focus on the image effects example until we can reach some consensus on the approach we're taking for individual implementations before we begin discussing cache's implementation again.
I've asked before, can we please stop discussing the DIC in this thread? It's an irrelevant distraction to the greater topic.
Eclipse
Comment #158
neclimdul@pounard
no, its (type, type_specific data). the type specific data isn't even options to the plugin necesarrily. it could be 'bob' and 'bob' resolves to (type, definition, options) at request. What's more important is its not a static resolution, if bob doesn't exist or a resource bob requires doesn't exist you might actually get fred. That is not something DI does. Or rather when it does its front loaded or handled manually because you can generally rely on a more controlled environment then Drupal provides.
Create plugin instance is much more inline with DI and since its /just/ a factory you can embed it directly in the DI like I believe I said.
They're complimentary systems not conflicting systems. Also, discovery is the /most/ important and novel part and not something DI can or will ever do.
Comment #159
effulgentsia commentedBased on IRC discussion with cosmicdreams, I added an "addendum" to #143 that shows the code without long inline method chains.
Comment #160
effulgentsia commentedTo further elaborate on this. If we look at Symfony's DI components purely as reference material, we see a Container class that is meant to be used at runtime. It has a whole lot of interesting methods, but the only one that has a corollary with the plugin system is
get()which returns an object/service instance. This method just takes a string $id as its only param; it doesn't support passing $configuration or $options in order to get different runtime objects representing different configured instances.However, Symfony also includes a ContainerBuilder class, which is intended for use during compile time only, not during run time. drupal_container() currently uses ContainerBuilder instead of Container, because we have not yet figured out how to do service compilation for Drupal, but we still have hopes of figuring that out, at which time, we'll change drupal_container() to use Container only. Anyway, ContainerBuilder does include getDefinition() and getDefinitions() methods, which at least at a conceptual level has some similarity to what neclimdul refers to above as the plugin system's most important feature: discovery. But, what ContainerBuilder returns from these methods are definition objects that control instantiation only; they don't include things like 'title', 'label', 'description', because Symfony doesn't come with a UI for configuring services, it expects a developer to write YAML files. But in Drupal, we don't want to require someone to write YAML files to make an image style or a View. We consider that to be part of site building, so we provide a UI. But, ContainerBuilder does support a type of discovery mechanism in the sense of running CompilerPass objects, which can find Symfony "bundles" and create low-level service definitions out of higher level ones.
So yes, at a pattern level, the plugin system has some similarities to dependency injection and service location and Symfony's container building, but just like Symfony's ContainerBuilder is a custom implementation around that pattern that's useful for (compiled) Symfony applications, the plugin system being proposed in this issue is a similarly custom implementation around that pattern that's useful for Drupal's site building tools.
Comment #161
effulgentsia commentedI added an "addendum 2" to #143 based on this request.
Comment #162
eclipsegc commentedI've spent a fair amount of time trying to document some of the basic concepts included in the plugin system, how they work and how a developer might use them together to begin building a custom plugin type. Hopefully these docs can help inform this discussion further and shed some light on various areas of the system that are not immediately obvious. These are totally a work in progress, as both the code changes out from under the docs, and as I am only human and have likely made errors. In any event this should definitely communicate the essence of the plugin system as it currently exists.
http://drupal.org/node/1637614
Comment #163
pounard@EclipseGc Thanks for the answer and documentation, I won't ask anymore about DI in this issue then.
Comment #163.0
pounardadding plugin documentation link to the summary.
Comment #164
neclimdulTalked with Dries and we decided to make a different set of implementations. Here are 2 refreshed patches.
1) Just a refresh without the cache or image effect implementations.
2) 1) with functions renamed to remove Plugin..
Hopefully these will help any reviews. Will follow up with another patch with likely the image backends or something. Discussions in the sandbox issue queue.
Comment #165
sunComment #166
Leeteq commented(Cross-referencing duplicate issue: #1059972: Very simple plugins subsystem )
Comment #167
dawehnerIn general it is a bit hard to first see why you need both some kind of base plugin class
but also a pluginType class, but sure this makes sense once you dive in deeper.
It was also a bit confusing that you at least have to implement the constructor
to set the factory and the discovery of your plugin type.
Neclimdul told me, that most factory/discovery classes might need some kind of arguments,
so this is okay. I'm not sure about that, but i guess this could be documented a bit better.
Converting an existing plugin was more or less easy except some implementation details.
I'm wondering whether there is a real life usecase for staticDiscovery
Great documentation, especially helpful for converting existing systems
Just wondering, whether t() makes sense at this place?
It is a bit confusing to distinct between $options and $configuration. Maybe the difference between $options in the constructor and $configuration here should be documented. I guess renaming $options to $configuration would help a bit.
I guess for something which contains sub-plugins like a view you should write your own mapper, because you might have instances of the same plugin with the same options but on different views at the same time.
If there is no getter/setter every plugin (i guess most of them have configuration) would write the same method. Maybe having one for convenience would be some kind of DX.
It would be cool to have an example implementation at least in the tests for this.
I'm wondering whether there is a real life usecase for staticDiscovery
Great documentation, especially helpful for converting existing systems
Just wondering, whether t() makes sense at this place?
It is a bit confusing to distinct between $options and $configuration. Maybe the difference between $options in the constructor and $configuration here should be documented. I guess
Comment #168
neclimdulI think you double pasted out of dreditor.
Possibly. It could be used really early to solve problems like bootstrapping the system. @effulgentsia was able to use it in his cache type to very trivially wrap the settings.php $conf values into discovery values.
Definitely not. In fact under the rules of the component directory it is not allowed. Good catch.
That'd be mappers being a bit confusing. Options in getInstance is actually an important distinction. The design is something more like this.
Notice that there is no configuration. The mapper implementation used by cache system knows how to resolve those options into a plugin and some configuration. then it can instantiate that plugin with that configuration.
I'm not 100% views would use this but yes, most systems would need their own mapper. A big system like a view would have the configuration and plugin id for the sub plugins its instantiating so it should just call createInstance really because there's no resolution necessary.
I really wanted no methods required on plugins. I don't think there's a lot of DX gained from these methods /unless/ your system is passing a plugin around in an admin interface. Something like cache or aggregator fetchers or likely even image effects gain nothing from being forced to have these methods.
I'm glad you asked because I needed to post this to the issue. One of the outcomes of talking to dries was deciding to remove cache and image effects from the patch. We're working on attaching a simple and complete implementation with the patch still though. That's actually turns out to be tricky without getting into changing architecture to move things into classes but we found this one. #1672776: Convert Aggregator Fetchers to Plugins Reviews welcome.
Think I got them all :) Thanks for the other nice comments.
Comment #169
eclipsegc commentedSeriously great review here, and neclimdul nailed everything, I have nothing to add except "Thanks dawehner"
Eclipse
Comment #170
dawehnerHe for a short time i wondered why i wrote so much :)
So this are some kind of properties on the plugin connected with a certain instance, so its like instanceConfiguration.
I was especially wondering about the static cache on the mapper, but this makes absolute sense.
What would happen if you don't define the methods on the interface but just on the actual base class? Not sure whether this really makes sense, but sure this is not a big issue.
Comment #171
bojanz commentedOkay, so I jumped into the plugins system for the first time, using #1675048: DX: D8 Plugin writing and #1672776: Convert Aggregator Fetchers to Plugins for reference.
I use ctools plugins in contrib and approached this mostly from a "user" perspective.
Some of my comments might be more appropriate in those two issues, but since this issue provides the big picture, I thought it would be
better to post them all here. Let me know if you want them moved.
In general, I'd be fine if this was committed today.
- I like getDefinition and createInstance(). Removing the "plugin" part of the names made it a bit less verbose, while still being clear enough.
Just having methods called get() and friends would be super-confusing to me. I feel that it's important to distinguish between the definition (which we usually called "info" in d7) and the actual instance.
- I was prepared to find Derivatives scary, but #1675048: DX: D8 Plugin writing made them easy to grasp. My one concern was that getDerivativeDefinitions() selects from the db without any kind of filtering, which could lead to loads of data being transfered, but one can easily implement more targeted methods on the class that implements DerivativeInterface, and then proxy to them from the PluginType.
Considering that they will be used for blocks (and possibly reworked actions, I guess) it is good to have this in the initial "big picture" patch.
- While it makes sense to me that I should somehow "declare" a plugin type, the naming and usage of the PluginType classes in the two issues
made me a bit confused and uneasy. Unsure how the problem should be addressed.
Here's what I saw:
from the first issue, and from the second:
"Messenger" makes me think it's the actual plugin (and the patch in this issue did the same with "Effect').
"FetcherType" also throws me off track, making me think there are multiple types of fetchers, instead of telling me "this is the god object that proxies to both discovery and factory.".
And the variables they are assigned to are always slightly imprecise, since they attempt to describe it as a discovery or a factory mechanism, not both.
Earl had an idea in #1672776: Convert Aggregator Fetchers to Plugins to name the "god object" -> Manager or Arbiter, which would bring clarity but require some reachitecturing.
Perhaps the solution is to just be more verbose:
This brings the question of do we want to mention "plugin" at all in the end user API.
And of course there's always the idea of just splitting the PluginType into two objects (as effulgentsia suggested in #154).
I'm not sure what other logic might live in the PluginType classes, so that might or might not be practical.
Comment #172
rovoIs the Plugin system to replace/combine the current Modules system and Features Module?
Comment #173
neclimdul@bojanz Looks like some good stuff! Thanks!
@rob_dean Neither really. CMI is more on track with replacing Features. That said, it will integrate closely with CMI. If you're familiar with Panels or Views, both have Plugin systems very similar in concept to what is provided here. Each filter, field, context, content_type(panels block), access rule, etc is a Plugin implementation. The same functionality that provides easy UI creation though type/id/configuration triples mapping to implementation makes Features(or ctools export.inc) style deployment much easier.
I'd read though the Plugin Type and Plugin Implementation descriptions in the summary and see if it makes more sense now. Feel free to find me on IRC too.
Comment #174
eclipsegc commentedNo. Features is largely focussed on "exportables" which is really more the domain of CMI. Modules are still a requirement for what we want to do within Drupal and are really use-case-less. Plugins are individual use cases that allow a single repeatable type of code, conforming to certain expectations, the ability to provide solutions to that use case.
Comment #175
rovoThanks neclimdul and EclipseGc, makes a lot more sense now.
Comment #176
effulgentsia commentedThis is an up to date diff for what's in the plugins-next branch of the sandbox. It's the same as #164-2, but includes the aggregator module's "fetcher" logic converted to the plugin system. Since per #164, cache system and image effects changes are no longer part of this issue, the aggregator fetcher is our one and only starter use case: remaining system conversions will be deferred to follow-ups.
This thread is long and appears to have many more people following than reviewing, so for anyone who's refrained from leaving comments here, but who wonders about or can provide feedback about the basic DX of how this will impact modules, please take a look at just the aggregator module changes in this patch, and leave feedback on #1675048: DX: D8 Plugin writing and/or #1676202: DX: D8 Plugin Type writing. Since once this is committed, we'll start converting lots of plugin-like systems (image effects, text filters, blocks, fields/formatters/widgets, actions, and many many more) to use it, I really can't stress enough how valuable it is to get reviews from a broad mix of developers on those issues.
And of course, for anyone who wants to provide additional reviews of the internals of the system on this issue, that also continues to be most welcome.
Comment #177
effulgentsia commentedThis:
- Renames PluginAbstract to PluginBase
- Renames PluginType to PluginManagerBase
- Renames PluginTypeInterface to PluginManagerInterface
- Similar Type -> Manager for classes within aggregator and test modules
- Removes Type as a subnamespace from aggregator and test modules
- Moves mock plugins used by unit tests into $module/$type subnamespaces
- Related docs cleanup
- Removes unused and stale DefaultMapper
Look at the plugins-next branch in the sandbox if you want to see commit by commit.
Comment #178
eclipsegc commentedThis should include all of effulgentsia's changes as well as an update to the tests that causes them to fail when the DefaultFactory and the PluginBase are used together incorrectly. Also fixed DefaultFactory and PluginBase so that they CAN work together as previously, they could not. This fixes all the bugs I know about in the system currently (not to say it's bug free, just that I don't know of any others). I'm awaiting an RTBC on this unless anyone has objections (or testbot fails).
Eclipse
Comment #179
aspilicious commentedIf this is nealy rtbc I want to point out 2 minor things
1) There are 5 little doc todos left, can someone fix those.
2) I grepped for "type" and I found a lot of type references in the docs (in this patch). Are you sure you converted all the docs to the new name? If not that could lead to confusion.
Comment #180
eclipsegc commentedWill double check both of these things "type" as a notion isn't going away, just as a Class/interface name. It's still a plugin type, it's just handles by a manager.
Comment #181
podarokThere is also one
// TODO - Do we throw an exception or just skip and let sub classesin patch
Comment #182
effulgentsia commentedThis adds a test for the fix in #178 and resolves the todos. Incremental commits can be viewed on http://drupal.org/node/1441840/commits.
Comment #183
effulgentsia commentedRe #179.2, these are the two places where I think we want to change type to manager. Would be great if someone else could double check how the terms "type" and "manager" are used throughout to make sure each is used correctly per #180.
Comment #184
eclipsegc commentedadding scotch tag
Comment #185
effulgentsia commentedJust wanted to add here that I re-skimmed the comments from #100 and later, and believe that all feedback has been incorporated or responded to with the following exceptions. If I failed to capture something in this list below, please identify it.
- Dries in #100 and yched in #111 suggest renaming PluginInspectionInterface to PluginInterface. This is not just a rename request: it would carry with it a decision to imply (maybe even enforce) that all plugins must implement it, whereas currently, no such requirement exists or is implied. In #112, neclimdul argues against this. I've gone back and forth on this, especially in light of Crell's statements in #147 about us possibly not needing or wanting to use the plugin system for non-UI-configured plugins. For now, I agree with neclimdul and #182 keeps it as PluginInspectionInterface. If people want to discuss this more, I suggest doing so in a follow-up or re-opening #1540206: Allow self inspection on instantiated plugin objects, but I see no reason for that to block this initial patch from landing.
- There was a lot of discussion in this issue about what the relationship should be between Drupal's dependency injection container and plugins, plugin managers, and plugin components. However, we still have a lot of other core issues (e.g., #1599108: Allow modules to register services and subscriber services (events)) to work through before drupal_container() is sufficiently usable in any advanced way, so #182 steers completely clear from anything having to do with drupal_container(). We'll have follow-ups for that when drupal_container() becomes sufficiently ready.
- There was also a lot of discussion about derivatives, especially the terminology. That continues to be unresolved, but everyone I've talked to about that, including Dries, is willing to continue those discussions in follow-ups. #1645828: Find alternate terminology for "derivative" or clarify why derivative is best is still open, so we can continue hashing that out, but without blocking this issue.
- There are still some unresolved DX concerns around mappers and their relationship to factories. For example, is the getInstance() vs. createInstance() distinction clear, and is the $options vs. $configuration distinction clear. #182 makes no use of mappers at all, though MapperInterface continues to be there, because we expect the concept to be needed and useful for Blocks and other systems. I expect follow-ups to be needed to refine the DX of mappers.
- I haven't yet read all the reviews in #1675048: DX: D8 Plugin writing and #1676202: DX: D8 Plugin Type writing, so there might be stuff from there we want to cover in this issue. If there is, I'll add another comment here unless someone beats me to it.
Comment #186
neclimdulThe Plugin writing discussion mostly seemed to contain "this would be clearer" comments that can easily be followed up on. Nothing that was terribly broken.
I haven't read the Plugin type discussion as deeply but I think the issues brought up there have been addressed as well. They seemed to be mostly naming or minor bugs as well.
I'm tempted to mark this RTBC but it seems improper since its largely my design. I definitely feel its at least good enough to start using in core and have it moved out of our sandbox.
Comment #187
aspilicious commentedWell nobody else had concerns on this and 111 people o_O are following this. They had time enough to respond.
Everything is documented on d.o. and in the patch. No todo's left.
So I'm moving this rtbc so Dries can have another look :).
Feel free to bump it back again if there are serious problems with this patch.
Comment #188
webchickThrowing this back into the Dries pile.
In the interest of Full Calendar Transparency™ it's likely that the earliest opportunity Dries will have to take a look at this is Wednesday. Tomorrow he's flying, Monday/Tuesday is the Drupal Governance Sprint. Though on Wednesday, we will hopefully be interviewing Drupal Association Executive Director candidates, so I can't totally guarantee that timeframe either. :\
But rest assured, this is at the tippity top of his "to review" list when he has D8 time.
Comment #189
dries commentedI decided to go ahead and to commit the Plugin System to 8.x. Thanks everyone for all the hard work. I'm looking forward to all the follow-up patches. :-)
Comment #189.0
dries commentedUpdate summary for everything except mappers and factories.
Comment #189.1
effulgentsia commentedUpdated issue summary.
Comment #190
Crell commentedzOMG!
Happy Bastille Day, everyone! :-)
Comment #190.0
Crell commentedUpdated issue summary.
Comment #191
effulgentsia commentedYay! I was actually working on an updated issue summary when Dries committed this. I posted it anyway, as it might help for posterity and future docs.
This needs a change notice for hook_aggregator_fetch_info() and hook_aggregator_fetch() changes, and maybe for the system itself.
Comment #192
aspilicious commentedAdd a change notification for the system with a link to the d.o. docs.
Comment #193
neclimdulJust want to add, big thanks to yched, aspilicious, and sdboyer who had commits in the sandbox; everyone who contributed in the sandbox issues and g.d.o discussions; the sprint last year at Four Kitchens that was huge in locking in the design; and all the people that have generally just provided feedback. This was a mammoth effort and there was a huge team of people that have contributed over the last year. Congratulations guys!
Comment #194
Niklas Fiekas commentedYay! Thanks to all who contributed!
It's ok if not, but maybe it's not too late to revert this one and actually merge the branch for all the messages, history, context and credit.
Comment #195
tim.plunkettOnly if the feature branch were properly rebased first. Useless merge commits are useless.
Comment #196
Niklas Fiekas commentedRight.Just something to consider.Or rather: Depends, but it doesn't look that bad.
Comment #197
Crell commentedWe've done non-rebased merges multiple times now in D8, including Config and WSCCI Kernel. It's sad to see that not happen here.
Merges are not inherently useless; they're actually filled with useful information.
Comment #198
webchickIf you want core maintainers do things outside of the norm, you need to provide explicit instructions; copy/paste commands work best.
Comment #199
tim.plunkettHow is a commit like http://drupalcode.org/sandbox/eclipsegc/1441840.git/commit/94d877e full of useful information?
Comment #200
neclimdulYeah I'll take the blame for the goof. I meant to discuss the commit/merge process but then it went from review to committed quickly. Thanks BTW! I should have mentioned it earlier or in my last comment and I didn't. I wouldn't blame Dries or the core committers as they didn't know. That's why I was thanking everyone here.
Comment #201
neclimdul@tim.plunkett merge commits can be useful we just generally do them poorly(using the automated commit message). Lets discuss core processes elsewhere though.
Comment #202
fagoNote: When looking at the committed code I stumbled over the following issues:
#1699774: Remove unused aggregator.fetcher.inc file
#1699782: fix handling plugin exceptions
Comment #203
sunChange notice: http://drupal.org/node/1704454
This change notice will combine/summarize all further plugin conversions, and it looks like there are still going to be some major follow-up changes to the plugin system (and/or individual implementations) before the release, so I recommend to keep it at that for now and advance on it when appropriate.
In general, I think that the link to the handbook page in that change notice is going to be the most important. It might turn out that we're going to rewrite the entire system...
Comment #204
sunComment #204.0
sunAdded 2nd level UL