
Active
Project:
OpenAI / ChatGPT Integration
Version:
1.0.x-dev
Component:
OpenAI Embeddings
Priority:
Normal
Category:
Task
Assigned:
Reporter:
Created:
6 Feb 2023 at 17:19 UTC
Updated:
12 Mar 2024 at 11:47 UTC
Jump to comment: Most recent, Most recent file

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #2
kevinquillen commentedSo the previous one I found:
No matter how I pass the arguments to it, comparing "Test Article" input against a vector that was generated as "Test Article" or "This is a test article" at best only reaches 0.50000x score value - shouldn't it be much higher?
Looking at the test file:
https://github.com/mlwmlw/php-cosine-similarity/blob/master/test.php
It too looks like it expects the inputs as words and not floats.
Comment #3
kevinquillen commentedTrying to use the NlpTools as this:
throws this exception (which I do not understand at the moment):
based on the docs, it does not look like it works with a vector of numbers like we get back from OpenAI: http://php-nlp-tools.com/documentation/similarity.html
Comment #4
kevinquillen commentedMight be on to something here.
With this class: https://github.com/suryamsj/Cosine-Similarity/blob/main/function/CosineS...
I get this back. In this case, I am comparing a vector of "Test Article" assuming user input (search, wherever). This node that was scored has a title of "Test Article" and its body mentions the phrase "test article" among other words:
A 1.0 hit is what I would expect for an exact match and a high-ish score (body) otherwise.
The class needs to be converted into English (for docs purposes) and if we could put some test cases in to prove it is scoring correctly given an input, that would probably get us moving here.
Comment #5
kevinquillen commentedMade short work of that... I asked OpenAI to translate the Indonesian comments into English:
If this is indeed correct, I can adapt this class into Drupal.
Comment #6
kevinquillen commentedI am not 100% certain of this, but in the end I think this feature will necessitate an integration with a data storage that supports vector search, like Pinecone or Milvus. Unless there is a reasonable way to search with MySQL that is performant, I am unsure this will work at scale (100+ entities).
Some readings:
- https://www.pinecone.io/learn/vector-database/
- https://docs.pinecone.io/docs/query-data
- https://frankzliu.com/blog/a-gentle-introduction-to-vector-databases
- https://milvus.io/
Without a vector search, this does not leave many avenues for local storage to accomplish this. You'd be stuck loading several records just to loop and compare, where something like Pinecone can do that heavy lifting a million times faster.
Comment #7
kevinquillen commentedhttps://docs.pinecone.io/docs/openai
Comment #8
kevinquillen commentedSolr 9 appears to have dense vector search added, but it only supports a vector 1024 in length whereas OpenAI returns one that is 1536.
https://solr.apache.org/guide/solr/latest/query-guide/dense-vector-searc...
Comment #9
kevinquillen commentedI think what is worth trying here is to build a thin API client to interact with Pinecone and see what happens:
https://docs.pinecone.io/reference/describe_index_stats_get
Fortunately, the API is very lean.
https://docs.pinecone.io/docs/query-data
We already have the vector data, so it should be a matter of slotting in an HTTP client for query/comparison. We can store entity id, bundle, etc like so:
https://docs.pinecone.io/docs/insert-data#inserting-vectors-with-metadata
Comment #10
kevinquillen commentedSeems like I am on the right track with this approach, whether or not Pinecone is used. I would need help with dynamic client design (i.e. multiple client, multiple settings, multiple config) but we just need 1 right now.
I wrote a rough client just to interact with Pinecone. Here is an example:
it responds with the top 5 hits for the vector:
That is... very cool. But this is example data.
What I should do now is insert the queue worker data into Pinecone instead of the local Drupal database. If the upsert there is successful, I should save the remote id in Drupal instead (similar to how Search API tracks items).
Comment #11
kevinquillen commentedComment #12
somebodysysop commentedYes! So, I'm assuming that the ID I see is the vector ID in the Drupal database?
If so, then we use SQL to get the entity id and type. I know we are just prototyping now, but it is at this point, in the final model, that we will run access permissions (core and group) against the returned entitles to assure that the user actually has permission to access them.
It would be more efficient to do it before the pinecone call, but I don't see how we can accomplish that until we know what entities are going to be returned.
In any event, Excellent Work!
Wait! I just thought about it. We can eliminate the entities the user does not have access to view BEFORE they are submitted to pinecone! Oh yeah! I've done a lot of work with group permissions so I can certainly help there.
This is exciting!
Comment #13
kevinquillen commentedYes. I should probably diagram it out, but:
1. "Entity" is saved
2. Job item is created
3. Queue worker processes the job
4. Data is saved (to db)
This is all working today. What I think we need to do instead, is:
4. Data is upserted to Pinecone, and the remote id record is saved to the db
5. Complete the client
Then, it would be a matter of integration modules (like one that bolts on functionality to Views) to provide input UI, take the input, vectorize it with OpenAI, then use the Pinecone client to do a search like I did above and get topK number of items back. From there, it would be that modules responsibility to ensure access levels are checked. This is very similar to how Search API modules work.
I also think we should save input that is vectorized from users, because the vector never changes (unlike a ChatGPT response), and that would really make this faster.
So then, its (user interface) -> vectorized input -> vector is queried against Pinecone -> response -> (module does something with the response).
The black and white response in my previous comment is the HTTP response from Pinecone using an example data set they provided. Ideally, our packed object would be in the metadata, which is possible to do:
https://docs.pinecone.io/docs/insert-data#inserting-vectors-with-metadata
There would be our entity id, bundle, etc, all items needed to run an entity load.
Comment #14
kevinquillen commentedI'm wondering what happens if you ask to embed a giant block of text. I am thinking a body field on a content type that is a ton of text. OpenAI max token limit is 8196 for embeddings. I am also wondering if that will take longer to respond to queries. Hmm..
We also need to strip_tags and trim all strings before embedding.
Also a good read, and I think what we are trying to achieve here: https://www.pinecone.io/learn/metarank/
Comment #15
kevinquillen commentedI committed some initial progress here to proof out this idea.
https://git.drupalcode.org/issue/openai-3339686/-/blob/3339686-integrate...
This is the client for Pinecone. Their API is very simple.
I amended the queue worker to send this data to Pinecone:
https://git.drupalcode.org/issue/openai-3339686/-/blob/3339686-integrate...
Almost instantly, its in Pinecone:
Given the breadth of options (Pinecone, Milvus, Typesense, etc) that someone could use to store vectors, I am not sure any of that code belongs in this module. A long term solution would be a connection manager or deriver that lets a module define a connection, then tell the embeddings module to use that connection object. I do not know how to do that yet, but also do not want to impede progress.
The next step is to find a scenario to query against something - any thoughts?
Comment #16
kevinquillen commentedThe 'id' key in Pinecone is the entity UUID from Drupal. It's possible we don't need any additional metadata at all.Bah, scratch that. I need to use a unique id per row since we are indexing fields on entities and not the total entity worth of text. They require the id field, it is not an autoincrement.
https://docs.pinecone.io/reference/upsert
Comment #17
somebodysysop commentedIf you mean a site with test data to try it against, I've got a couple of those. You'll need to walk me through installing what you've got and I'll give it a try.
Comment #18
kevinquillen commentedI meant, how can we prove this idea has legs - maybe a page in the admin that has an input field and lets you 'search' for matching content?
Comment #19
kevinquillen commentedOn the id front, the id can be a string in Pinecone, so I whipped up something quick to satisfy that.
Kind of awkward Pinecone doesn't handle/generate its own records. But this should suffice.
Comment #20
kevinquillen commentedInstead of embed 'on the fly' when someone performs a search, perhaps a better idea would be to try this first:
https://github.com/RichDavis1/PHPW2V
Take the user input, word2vec it with 1536 dimensions. If the math/output is right, it should be good enough to compare to what we got in OpenAI/Pinecone without incurring HTTP API call time and API usage hits.
Its hard to say though because they don't go into much detail here: https://platform.openai.com/docs/api-reference/embeddings
But we can always take a sample input string and tweak the arguments to word2vec and see if they get close.
edit: looks like that lib only saves to a file. Darn. Ok, I won't try to prematurely optimize it then, we will cross that bridge when we get there.
Comment #21
kevinquillen commentedI whipped together a quick demo of searching input in Pinecone:
One thing I noticed is that if you embed several fields on a node, you have to filter out duplicate node ids from the response or you will see it over and over many times. I have no good idea on how to mitigate that yet. I also noticed that even for a direct hit, superfluous words like 'and a the in' etc can influence other results much more.
Comment #22
somebodysysop commentedWow. Fantastic work! Thank you for making this happen!
I am looking to integrate this with Search API Attachments. If I can retrieve the file content and associate the file id with parent nodes or paragraphs, how can I plug that information into your existing model? If I am reading this correctly, file data could be added to existing vector table using the file id as entity id, 'file' as entity type and node/paragraph id as parent id. Once vectorized, it can be searched and retrieve just like the other entities.
Or, should I create a new issue for this?
Comment #23
kevinquillen commentedI spent a little time on this this weekend looking into a path forward here.
I took a survey of 10 or so known 'vector databases' (Pinecone, Milvus, etc). I thought I could make a plugin object and plugin manager for all the connections that could be built. This may be a possibility:
Where we don't care how you do it, as long as you do it (textbook interface). Beyond that, integrators would be on their own, but we need them to at least ensure the plugin does these four things. I cannot make it more specific than this - different databases have variable list of arguments and in some cases they don't use a vector of floats at all as the comparison.
Comment #24
somebodysysop commentedGreat idea. But, I'd just stick with the one or two or three I know work for sure. Makes the documentation and support a lot easier.
Comment #25
kevinquillen commentedYeah - I will probably have to shelve that behavior. I've never created dynamic plugins that store their own configuration before (a la Search API backends). I have it mostly there... just cannot get the configuration to save into state like other Drupal configuration.
Basically, if you were to code a new plugin using the annotation I made, it would appear on the form with its own settings (as defined by that plugin) since each service has different requirements in its API.
From this point, the user would select which plugin is 'active' - and that would be loaded dynamically in the queue worker.
I think for now I will have to shelve the work in a branch, until I can finish that or someone helps me figure out how to finish a complete plugin manager / collection / config manager implementation. I have never really done that before.
Comment #28
kevinquillen commentedFor now I have merged in my WIP to dev. The client plugins can be circled back on later, but the work is there.
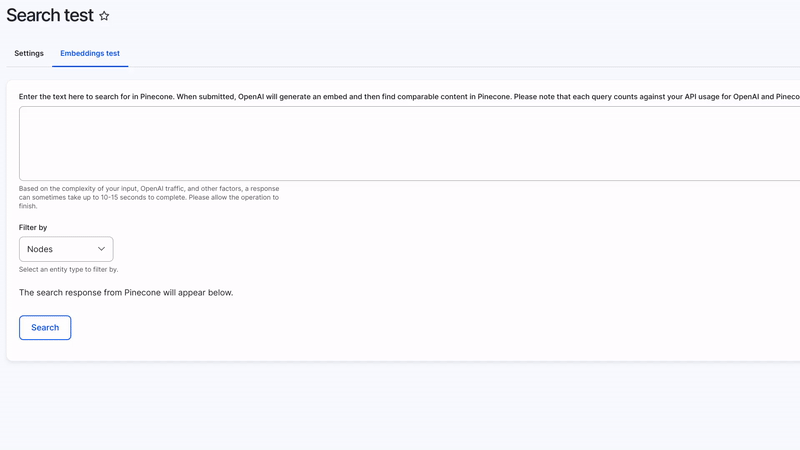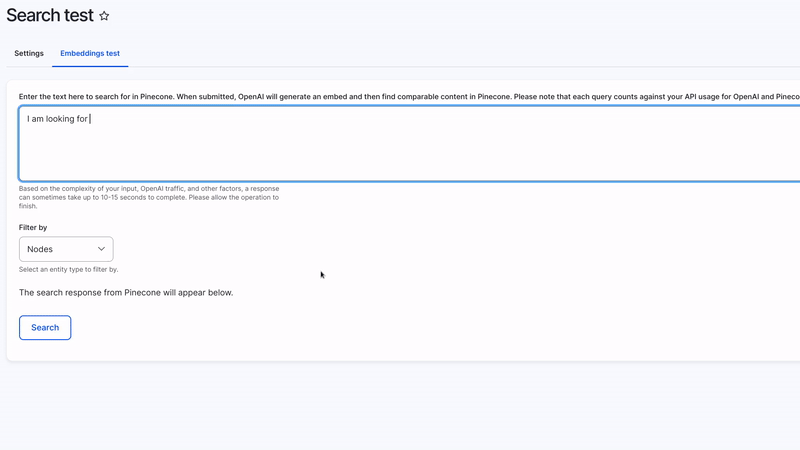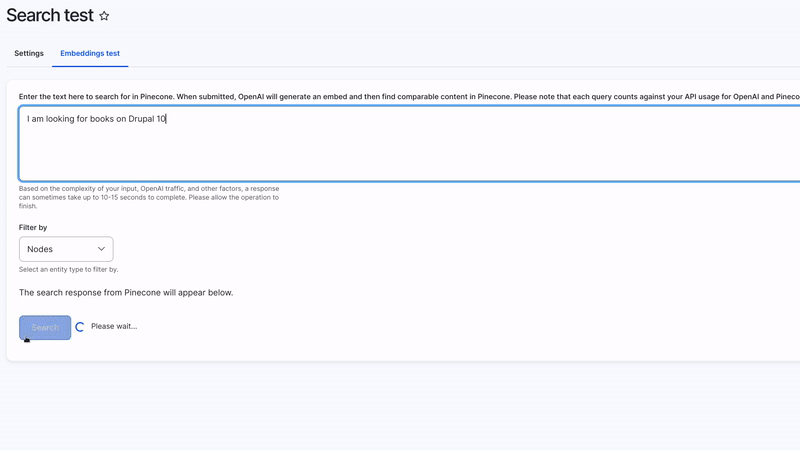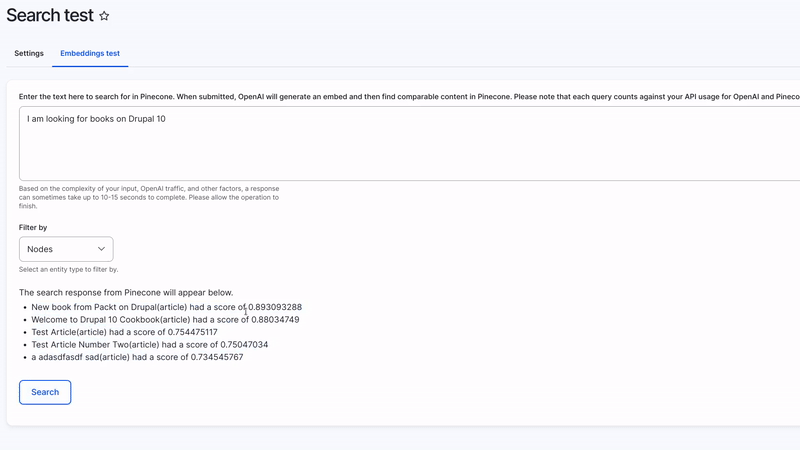
There is a UI now on the embeddings config that lets you try different strings and search against what is stored in Pinecone.
I get odd results sometimes and I am not entirely sure why. For instance, I filled a node with gibberish typos. When I search "Drupal" or "Drupal 10", its returned with a relevancy of .8-.85, which is very high for something that doesn't mention this or anything close to it at all.
Comment #29
kevinquillen commentedThere are two interfaces to try... there is a 'Search test' on the embedding setting section. I added a new POC feature too that tries to figure out if your content is 'too similar' to other content in regard to SEO. If you have a Pinecone account you can try it out.
I am not 100% on if the vectors are being generated/stored efficiently or if I just do not have good content (I really don't have much). Sometimes the results are very similar, sometimes the results have a match that don't make any sense.
I think step one was enforcing namespaces when saving, which I did in #3341713: Add a namespace for Pinecone when upserting instead of leaving it blank. I would need to read up more on similarity search accuracy.
Comment #30
kevinquillen commentedIf I am not mistaken, it sounds like entities should be submitted as an entire string of text instead of individual field values, based off the examples I am reading:
https://github.com/openai/openai-cookbook/blob/main/examples/vector_data...
Comment #31
somebodysysop commentedThis is correct. I've not used the github project you reference, but I have queried the OpenAI models, and the prompt is sent as a string. You can submit a jsonl file which contains a prompt and response, but for the purposes of embedding, we only want to send a string to be embedded. The body of a node/paragraph is typically stored as a single field in the Drupal database. Even if the node has multiple paragraphs, each paragraph will have it's own body field. That, I presume, is what we are sending to be embedded.
Comment #32
kevinquillen commentedSure, but:
"input
string or array
"
Right now the code is getting an embedding per field value, instead of all values as one embedding. I am trying to figure out why I get relevancy scores that are just not relevant at all. For example:
There should not be any results... at least any results scored that high. There is nothing close to "Amigo" in any of those nodes. That is why I wonder if the implementation is correct.
Even if I type in "zzzzzzzzzzzzzz", I still get results that are ranked high.
Comment #33
kevinquillen commentedAlso, in the Pinecone examples, they use stop words in some examples:
https://docs.pinecone.io/docs/semantic-text-search
Like not embedding them and storing that... that would probably help too.
Comment #34
kevinquillen commentedHmmm.... this could be a bug with Pinecone: https://community.pinecone.io/t/cosine-similarity-same-datasets-one-in-m...
Comment #35
kevinquillen commentedNote for later, we may leverage this module to support multiple clients for vector db connections: https://www.drupal.org/project/http_client_manager
Most of these APIs are HTTP based. No need to reinvent the wheel.
Comment #36
d0t101101 commentedNew to the thread, and just signed up for Pinecone to experiment with this too...
This is certainly not my area of expertise, but will say I am a big fan of Apache SOLR. Have used it in numerous Drupal projects and successfully created 'more like this' type of widgets that matched related content almost uncannily well across 100k+ Drupal nodes. A huge advantage is that via the Drupal UI, it can be custom tuned to set weights and influence the score based on particular fields of interest, so for instance a similarity match on Title or Body can have a greater (custom defined) weight then just a Taxonomy term match alone. Also gets into more advanced Geospatial Lat/Lon types of considerations as to how it can score content, has visibility into all of the custom fields, and allows the site Admin to easily influence how scores are generated. How it does all of this under the hood, IDK, but looks like SOLR 9 is adding a lot using neural search capabilities here. I'd personally really prefer to see this type of functionality self hosted in Free and Open Source Software rather than relying on paid 3rd party service wherever possible! At the same time, respect how much time and energy is needed to just 'make it work' :-D
Digging into this, thought these references might be of interest to you with regards to SOLR/OpenAI, if you haven't already come across them. Just food for thought here!
https://github.com/apache/solr/pull/476#issuecomment-1028997829
"dimensionality reduction step"
https://openai.com/blog/introducing-text-and-code-embeddings/
"To visualize the embedding space, we reduced the embedding dimensionality from 2048 to 3 using PCA"
Is it maybe possible to intelligently reduce or otherwise truncate programmatically the vector size from 1536 (OpenAPI) to 1024 (SOLR), to possibly 'pair well'? And then you have the Apache SOLR community behind it to further assist rather than a 'black box' solution! Not bashing at all here; just sayin'!!!
Comment #37
kevinquillen commentedYes, this is mainly experimental. OpenAI returns a vector of 1536 length. There are not much in the way of PHP libraries that do this (embedding) that I could find. Solr has deep vector searching in 9.1, but its length is 1024 (plus, we'd need 9.1 support in Search API Solr). Right now the 'similar title' function of openai_content uses this, but so far I have found it to not be nearly as accurate as Solr on even the loosest comparisons. I cannot tell if I am using it correctly or if Pinecone is not that accurate. Earlier in the thread I had considered finding an external library that could be called with FFI somehow to generate an embedding, but was unsuccessful so far.
If you can really build all the things Pinecone advertises with a vector database on its homepage, I lean towards the direction of perhaps I am not searching it right - but you can see the API, its very simple and straightforward. They do mention that it is generally useful for augmenting search and or 're-ranking', but the examples in their docs appear to work far better than what I was able to try and do. I could also be misunderstanding the use case, or its also possible the data is not being compared correctly (I have seen a couple threads in Pinecone asking the same).
If this can work (not strictly for search) I am still interested in the possibilities around content recommendations and the like. It could prove a low-cost solution in an otherwise generally high cost service (content recs, content personalization). We have the appropriate data, I am just not connecting the dots in accordance with what their docs show. We can poke at this while waiting for Search API Solr to update and deep vector field support is in.
Comment #38
d0t101101 commented@kevinquillen - All points taken; glad to help however I can assist!
Another thought, while building out a small blogger-like website recently with Drupal 10, I didn't want the administrative overhead of keeping the separate SOLR service (or other API) in the mix. Landed on this Drupal module for a very basic 'more like this' functionality, which has been working well thus far for this particular use case. Scalability remains to be seen/validated... In any case, its a very simple approach to a similar problem - connecting related content. This of course wouldn't help 'out of the box' for direct content comparison/matching/searching/de-duplication/etc, and its certainly not taking the sophisticated vector approach for similarities, but does pretty well connecting content assuming the nodes are already classified via taxonomy terms.
https://www.drupal.org/project/similarterms
Otherwise, the underlying DB engine is obviously a key consideration. Mysql has its pros and cons, but is it possible PostgreSQL's 'fuzzy matching' on a per-field basis could boost performance here without the 3rd party dependencies?? Some interesting progress with trigrams/ngrams and similarity search referenced here:
https://www.postgresql.org/docs/current/pgtrgm.html
Comment #39
kevinquillen commentedAdding some links here as notes, clearly we set out on the right track and its 'almost there'. I think some of the work I did in the other thread on improving the summary suggestion will potentially help accuracy of this feature too.
https://www.crunchydata.com/blog/whats-postgres-got-to-do-with-ai
https://vimota.me/writing/gpt3-klaviyo-automation
Comment #40
kevinquillen commentedThis is actually really really encouraging - we had the right idea to begin with. It's just a matter of making it hum now. How exciting!
Also a note for myself - to get around the embedding call limitation (60 per minute) I need to add a sleep() call to the end of the queue worker process.
Comment #41
somebodysysop commentedThanks for sharing. I found the same thing with postgres myself: https://youtu.be/Yhtjd7yGGGA?t=940
They've actually got vector field! pg_vector.
I'm starting to familiarize myself with PineCone.
Come on, MySQL! Don't let us down now!
Comment #42
kevinquillen commentedYes. I have read pg_vector, its a required extension for Postgres to do this. So far, I have seen no indication MySQL/MariaDB offer this, or, will offer this. Some have posted stored procedure routines, but thats.... they are difficult to install via module and usually not allowed at most managed hosts. So far, only Solr will be offering vector search functionality in 9.1 ( but its limited to 1024 length - OpenAI returns 1538).
Comment #43
kevinquillen commentedComment #44
d0t101101 commentedI'm personally a big fan of PostgreSQL overall, and if a possible pg_vector implementation could bridge this gap in your OpenAI module here related to Embeddings (between vectors in Search-centric DBs vs RDBMS), I'd have no hesitation to switching over from MySQL to PostgreSQL everywhere needed!
Other large/established websites might run into challenges of the PostgreSQL DB backend switch and compatibility with other Drupal contributed modules however, so ideally best to support both MySQL and PostgreSQL if reasonably possible. Would obviously be MUCH cleaner and faster to do all computation within the local DB!
Comment #45
somebodysysop commentedI'm finally coming up to speed on PineCone. I take it that your demo is currently using the query API: https://docs.pinecone.io/docs/query-data
If so, I'm wondering if I have run up against the same problem you've been describing here.
When you input a text query and send to OpenAI to embed, how are you formatting the returned vectors in order to submit in PineCone query?
For example:
$embedding is what I am sending to PineCone:
But I am getting absolutely nada back.
My index is set up to do the cosine similarity. I noted that you said you seem to get back results that don't make sense.
I know I'm kind of late on this, but trying to come up to speed.
Are we simply not getting our vectors in the correct format to be read by PineCone? Is this a PHP limitation?
Comment #46
somebodysysop commentedNever mind. I got past that issue. Testing the searches.
So far, using the PineCone cosine similarity queries, the highest results (#1) are pretty good. But, the 3rd result it brings back, I sometimes find things that, like you, I question.
Tell us, again, why you'd rather find a float library for PHP instead of simply using the PineCone query function?
Comment #47
kevinquillen commentedWe don't have to find one (no PHP library seems to exist anyway). I did not know enough upfront when starting this issue. OpenAI can convert text to a vector, then that vector can be stored in Pinecone (or any client a consumer wants to integrate to).
The only question right now is, is it being done right? Like you said, sometimes I get good results, and other times the results don't make sense. I have not been able to narrow that down.
Comment #48
somebodysysop commentedThanks for the feedback. I am working with real regulatory texts and will take a deeper dive into this.
I recall from your "amigo" example: https://www.drupal.org/project/openai/issues/3339686#comment-14923912
Assuming you are using cosine singularity, I am finding that anything under .8 tends to be relatively irrelevant. It's just guessing at that point.
Also, I'm so used to keyword searching, I forget that vector searches are based on semantics. So, theoretically, "amigo" would highly match any text dealing with "friend" or "friendship", as well as a photo image of two old guys sitting on a park bench.
That said, there are cases where I could not figure out why a particular document was included in top 3 results.
So, I'll look more into the available configuration options in OpenAI and PineCone. For example, I've been using CL100K_base as my embedding tokenizer, but it may not necessarily be the best option:
I'll report back what I find.
Comment #49
kevinquillen commentedI think we can stick with the search aspect, but "similar content title" feature probably needs to go away, its not as accurate as I would think.
Comment #50
somebodysysop commentedBear with me. Still working on this. I was able to embed and create queries using PineCone, but when I got ready to upgrade to the paid tier, discovered it was way too expensive, especially as a default search plugin.
I am instead now trying Weaviate. Waiting on them to provision a new instance for me so I can start working with live data.
I think I may have also come up with a resolution to embedding (and thus, vector searching) both web pages and attached pdf files utilizing search api solr. This also opens back up the possibility of using Solr's Dense Vector Search since we aren't limited to OpenAI's tokenizer and vector dimensions for embeddings.
Weaviate has it's own vectorization and query methods, so we wouldn't need a special php library for that. It also supports both vector and text databases.
Still working...
Comment #51
kevinquillen commentedHave you seen this? I don't think general availability to make plugins is here yet, but will be in the next couple of months. I think we have most of the infra in place?
https://simonwillison.net/2023/Mar/24/datasette-chatgpt-plugin/
Comment #52
somebodysysop commentedRe: https://simonwillison.net/2023/Mar/24/datasette-chatgpt-plugin/
It sounds similar to: https://www.intercom.com/ai-bot
There are a number of these services cropping up, and neither the GPT4 Plugins nor the GPT4 API have been released to the public yet.
FYI, I have been part of the team (actually, about 500+ people) testing the OpenAI browser plugin for the past 2 weeks. It is pretty cool, but has a number of pretty severe limitations, the biggest being it's token limits. It is also limited in that it cannot read pdf files, it cannot read pages with large amounts of javascript, and it cannot read pages denied by robots.txt.
The key questions to ask these services:
1. Can they embed both web pages AND pdf attachments?
2. If so, what are the token or page size limits?
3. Do queries include chat history?
4. What are the pricing factors?
My initial reaction is that people with small sites will definitely be able to quickly take advantage of these services. Entities with larger sites consisting of numerous large documents (i.e. PDFs) will not.
Using this tutorial as guidance: https://youtu.be/Ix9WIZpArm0
Here are the two development phases we are looking at to achieve our goal:
Phase I

Phase II

At some point, the GPT4 browser plugin will be able to support 32K tokens (or more). But, until then, the above is what we are looking at in order to be able to prepare large document sites to be semantically searched using AI.
Remember that I mentioned search api solr earlier? I think it might be able to take care of Step 1 of Phase I for us.
My 2 cents.
Comment #53
somebodysysop commentedOK! Took a while because Weaviate's architecture is totally different from PineCone's.
I have created a standalone PHP program that utilizes the Search API Solr index to create a Weaviate vector store. Essentially, this program can embed the entire content (node, comment, paragraph, pdf, docx, txt, etc...) of a Drupal site utilizing it's Solr index.
This is the "ingestion" process overview:
Here are the vital statistics:
Here is a more detailed view of the code processing:
I believe all of these Vector database providers have their own query systems, so we don't need an independent client library for vector comparisons.
There are some issues, and I have a ToDo list of things that need to be added to make it more complete, but it is functional now.
What do you suggest as next steps?
Comment #54
mitchel432 commentedHey SomebodySysop, any chance you could share your work on getting Weaviate to work with Search API Sorl. This sounds really promising.
Comment #55
somebodysysop commentedYes! I know @kevinquillen has done a lot of work on this already (with PineCone), so I was waiting to hear back from him on his thoughts.
My hope is to get this into an open source module that other users could then contribute to and enhance. Unlike most of the current "talk to your pdf" services being offered lately, I believe the Drupal CMS offers the best architecture for organizing and maintaining data for AI-driven semantic search. If @kevinquillen doesn't want to do it, then I'll break down and take a stab at it myself.
Thing is, I kind of don't know where to start with respect to sharing the code. It's been over a decade since I developed and maintained a Drupal module, and a LOT has changed since then.
So, as I indicated in my last post, I'd appreciate some ideas as to how to get this going.
I've still got a lot more work to do before I think it's ready to be shared, but it is working and I am very excited for the future possibilities.
Comment #56
kevinquillen commentedSorry, super swamped lately but I am interested to see this progress. Eventually, I see something like Solr, Pinecone, Weaviate and Milvus (OSS) supported offering full dealers choice of text embedding capabilities as mentioned.
Looking at the diagram, I can formulate in my head (mostly) of how this would come together as a Search API process plugin. At index time, you'd generate your vector values and store them (Solr, Pinecone, Weaviate, etc).
This likely makes the most sense since in most typical applications the edge of embeddings will come from search augmentation. What is in the module now was just showing off the possibility of what embedding is and can do (since its a large topic).
At a 30k foot level I think we are on the right track. Solr 9.1 supports vector storage, but I am not sure if Search API Solr module is 9.1 ready yet. Search API supports many storage formats, but no SQL options support storing or querying vectors (which the current submodule partially solves). Search API can likely provide enough means to get this done.
Roughly, I think a Search API process plugin could be made that is configurable. Basically letting a user select text fields to generate embeddings for, then allowing configuration to select which HTTP service (Pinecone, Weaviate, Milvus etc) to use (or Solr) to store the value. Leveraging https://www.drupal.org/project/http_client_manager to build that out seems reasonable for external sources. From there, its a matter of integrating it into the query process.
Comment #57
somebodysysop commentedSo, I have completed the standalone php query program. This program performs chat completion calls to OpenAI using the embedded Drupal Solr data (that vector store was created with the initial standalone program here: https://www.drupal.org/project/openai/issues/3339686#comment-15011514) as context, essentially allowing me to conversationally perform semantic searches with all the content on my Drupal site. It's taken nearly 3 months to get here, and I am totally jazzed now that I see this thing is actually going to work. No, I take that back. It's working now.
I'm going to start planning out a module to implement both phases: The Ingestion Phase and the Query Phase.
Although I am starting with Weaviate as my vector store, I do like this idea and would like to see it implemented at some point:
I also will need to figure out how to allow users to select the fields to embed from the Search API field table as mentioned above. In my current code, they are manually entered (Ugh!)
But, I think the first step is to create a module from the working code I've already developed to serve as a base platform to begin building out (with a little help, I hope) the requisite features to make this totally usable on any Drupal site running Search API Solr.
This is just a progress update. I will link to the module project once I get it going.
For inquiring minds, here is the query flowchart:
Comment #58
kevinquillen commentedGood work. Process plugins for SAPI are pretty straight forward, as well as prepare document events. One of the core process plugins demonstrates how to touch multiple fields (I think its an HTML boost process) that might provide some insight.
Comment #59
somebodysysop commentedI forgot to mention that Weaviate is an open source project, so you can download, install and run the code on your local machine. It handles both the embeddings as well as vector searches against those embeddings. Hence, it is a viable solution to the key concept of this issue: "Integrate a service or library to compare vectors of floats".
https://weaviate.io/
Comment #60
kevinquillen commentedYou may want to check this out:
https://www.drupal.org/project/search_api_ai
Comment #61
somebodysysop commentedThis is pretty good. I love the clean UI they've put together. That said, I still prefer my approach. Initially, my goal was to do what they are doing. It has changed. Now, my goal is to develop a module which will make Drupal a viable alternative to LangChain for end to end content organization, vectorization, semantic query and maintenance in the AI chat completion space.
https://youtu.be/B5B4fF95J9s
I want to use Drupal as the framework for AI Q&A applications I seek to build in the future.
Comment #62
somebodysysop commented6 months later, finally got a module working based on the prototype. Not ready for primetime, but it's working. The goal for me, and the object of this initial post, was to develop an embedding mechanism which integrates as seamlessly as possible with Drupal's existing content structure.
To that end, I have designed the SolrAI module to automatically sync Drupal content with it's embeddings. Right now, I sync the Solr index with it's Weaviate vector store objects, but the ultimate goal is to sync any content format with any vector store, including internal.
In case anyone else is working on something similar, this is how I did it:
Comment #63
fishfree commented@SomebodySysop I watched your video, that's great, the exactly semantic search! Would you please even publish your code as a Drupal contributed module?
Comment #64
somebodysysop commentedOne day, hopefully. I have been working continuously on the module for the past 9 months (unbelievable). Your post motivated me to sit down and create a general list of features and components. I'm still not finished, and I have barely begun to document it. As I have mentioned earlier, I am using it for my own projects right now: https://www.scbbs.com/ai_projects
SolrAI ModuleSolrAI Module Features
All the features available via Drupal plus AI.
Features
Regular Drupal Features:
SolrAI Module Features (Semantic Search)
SolrAI Physical Components
Original Video and Written Proposals: https://www.scbbs.com/node/845
Comment #65
fishfree commented@SomebodySysop WOW, a so ambitious and powerful project!!
BTW: this issue may be FYI.