
 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.Problem/Motivation
The log-in pages for my Drupal sites are being indexed by google. I'm not sure if this is due to recent changes in how google handles the robots file, or spiders sites, but it seems I am not alone in this problem: https://www.drupal.org/forum/general/general-discussion/2012-06-27/is-it...
Steps to reproduce
1) Google the domain name of one of your live sites
2) see if Google recommends the Log In page in the list of pages beneath the search result for the home page
Proposed resolution
Remove trailing slashes from the robots.txt file (or, add alternatives that don't include the trailing slashes)
From How Google interprets the robots.txt specification > URL matching based on path values:
Example path matches /Matches the root and any lower level URL. /*Equivalent to /. The trailing wildcard is ignored./$Matches only the root. Any lower level URL is allowed for crawling. /fishMatches any path that starts with
/fish. Note that the matching is case-sensitive.Matches:
/fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anythingDoesn't match:
/Fish.asp/catfish/?id=fish/desert/fish/fish*Equivalent to
/fish. The trailing wildcard is ignored.Matches:
/fish/fish.html/fish/salmon.html/fishheads/fishheads/yummy.html/fish.php?id=anythingDoesn't match:
/Fish.asp/catfish/?id=fish/desert/fish/fish/Matches anything in the
/fish/folder.Matches:
/fish//fish/?id=anything/fish/salmon.htmDoesn't match:
/fish/fish.html/animals/fish//Fish/Salmon.asp/*.phpMatches any path that contains
.php.Matches:
/index.php/filename.php/folder/filename.php/folder/filename.php?parameters/folder/any.php.file.html/filename.php/Doesn't match:
/(even if it maps to /index.php)/windows.PHP/*.php$Matches any path that ends with
.php.Matches:
/filename.php/folder/filename.phpDoesn't match:
/filename.php?parameters/filename.php//filename.php5/windows.PHP/fish*.phpMatches any path that contains
/fishand.php, in that order.Matches:
/fish.php/fishheads/catfish.php?parametersDoesn't match:
/Fish.PHP
Remaining tasks
update the robots.txt file
User interface changes
none
API changes
none
Data model changes
none
Release notes snippet
TBD
| Comment | File | Size | Author |
|---|---|---|---|
| #15 | Screenshot from 2021-07-22 18-02-33.png | 227.99 KB | dhirendra.mishra |
| #8 | robots-txt-3167542-8.patch | 1.45 KB | douggreen |
Issue fork drupal-3167542
 Show commands
Show commands
Start within a Git clone of the project using the version control instructions.
Or, if you do not have SSH keys set up on git.drupalcode.org:

{kind=link}
Comments
Comment #2
jenlamptonIn our robots file we have a mix of URLs that look like both paths and directories in the "Paths" section -- most of these end in a trailing slash, like a directory. Only
filter/tipsdoes not include a trailing slash, like a path.Since removing the trailing slash seems to work for keeping the pages out of the google index, I wonder if the adding the trailing slash indicates to google "Block all pages in this directory" but does not include the parent page -- the URL without the trailing slash.
Since this is my leading theory, I've added a new section to the robots page called
Psuedo-Directorythat includes all the items we want treated as though they were directories (all paths below blocked) and moved the items with trailing slashes here.I've also removed the trailing slash from pages that we do not want treated as directories, where we want only the path itself blocked from google. I've added duplicates into the
Pathsection from thePsuedo-Directorysection, where the parent path is also a page we want blocked.Patches for review.
Comment #3
jenlamptonforgot to change issue status: NR.
Comment #5
chi commentedThat has been fixed just yesterday.
Comment #6
larowlanComment #7
chi commentedThis still needs D7 backport.
Comment #8
douggreen commentedI'm re-opening because #3123285: Actually exclude user register, login, logout, and password pages from search results in robots.txt (current rules are broken) addressed the /user/ routes. But we still have the admin, search, and node/add routes which are routes by themselves as well as leading paths, and thus should be listed with both a slash and without one.
Comment #9
douggreen commentedLet's see if a new comment results in testing against the right branch. (I wonder if the testing system didn't recognize that the branch changed in the same comment that had a new patch)
Comment #10
quietone commentedStarting a test for 9.1.x
Comment #12
anybodyRe-running test against 8.9.x. This should be committed to 9.x and 8.x.
Comment #14
rescandon commentedThe patch is not working for 9.3.x-dev
- Installing drupal/core (9.3.x-dev e632ada): Cloning e632ada52e from cache
- Applying patches for drupal/core
https://www.drupal.org/files/issues/2020-09-15/robots-txt-3167542-8.patch (Removing trailing slashes from robots.txt)
Could not apply patch! Skipping. The error was: Cannot apply patch https://www.drupal.org/files/issues/2020-09-15/robots-txt-3167542-8.patch
[Exception]
Cannot apply patch Removing trailing slashes from robots.txt (https://www.drupal.org/files/issues/2020-09-15/robots-txt-3167542-8.patch)!
Comment #15
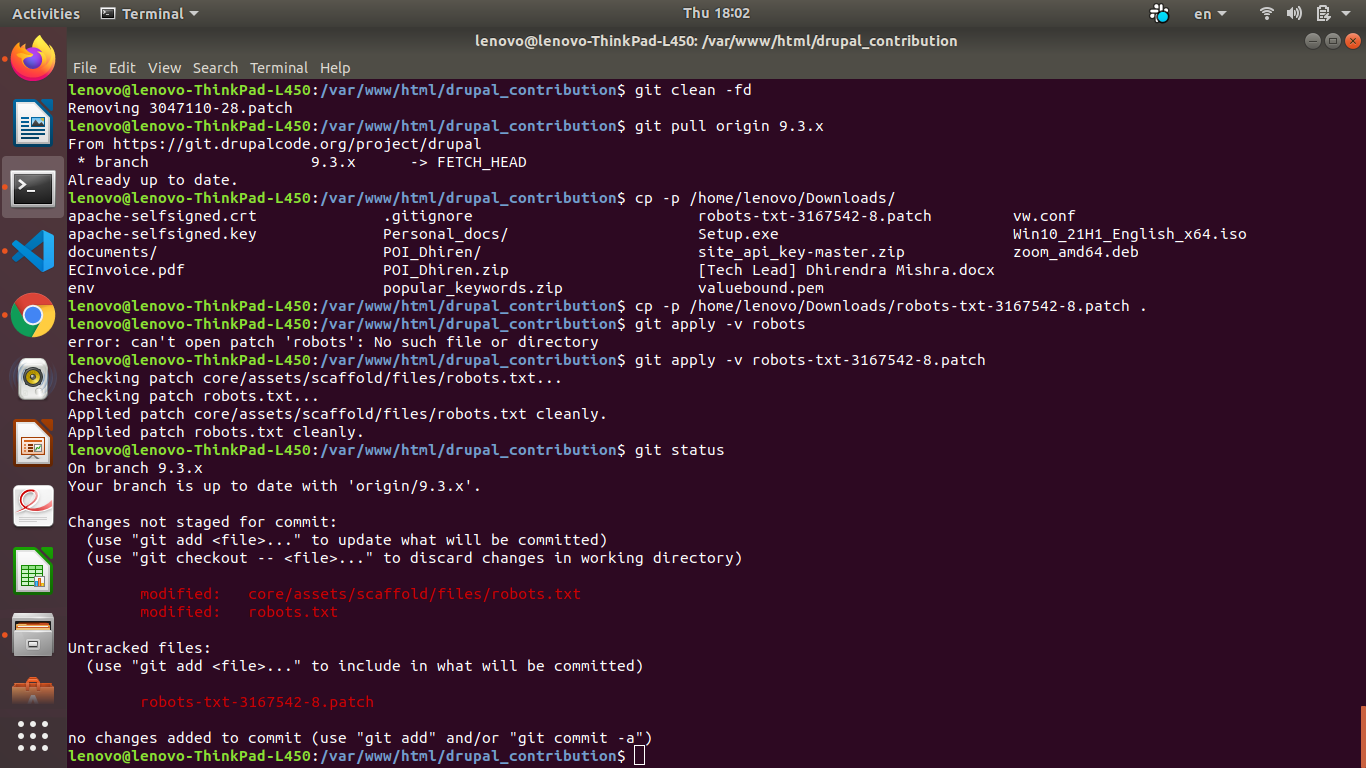
dhirendra.mishra commentedPatch from #8 gets applied on 9.3.x
Please find screenshot below:
Comment #20
abhaypai commentedLanded here from Bug smash initiative.
+1 #8 Patch is applied successfully for version 11.x-dev too and starting test for 11.x-dev version.
Comment #21
anybodyTests are failing for #8. @abhaypai could you perhaps turn this into a working MR against 11.x?
Comment #24
prashant.c@Anybody
Created MR against 11.x by taking the changes from #8.
Thank you.
Comment #25
anybodyThanks @Prashant.c! All tests are passing green, so I think we should get this out of the way! Marking this RTBC.
Comment #26
poker10 commentedAccording to the Google robots.txt description here: https://developers.google.com/search/docs/crawling-indexing/robots/robot... , the
/searchshould match any path that starts with/search. So I do not think we need both/searchand/search/(and similar for the second change). The rules from robots.txt should be the "starts with" rules.The second question is, we have
/admin/in robots.txt./adminpath is valid as well, so why we are not changing this too?Comment #27
smustgrave commentedCan it be documented in the issue summary what paths were chosen and why.
Comment #29
ressaI agree @poker10, we should remove all trailing slashes, and I have updated the MR to reflect this.
I have added the table below in the Issue Summary, is that sufficient documentation @smustgrave, or do we need some more?
From How Google interprets the robots.txt specification > URL matching based on path values:
PS. Personally, I would add
Disallow: /node, since:From https://www.drupal.org/project/usage
/node/100indexed instead of the human readable URL alias/my-aliasis bad for SEO ...... but that's for another issue :)
Comment #30
ressaI created an issue about disallowing
/node.Comment #31
ressaThe table outlining the rules I wanted to add in the Issue Summary got lost, now it's actually added.