
Closed (fixed)
Project:
Drupal core
Version:
7.x-dev
Component:
aggregator.module
Priority:
Normal
Category:
Task
Assigned:
Unassigned
Reporter:
Created:
2 May 2006 at 17:07 UTC
Updated:
19 Dec 2023 at 18:49 UTC
Jump to comment: Most recent, Most recent file

{kind=link}
{kind=link}
Comments
Comment #1
Steve Dondley commentedImportant clarification. This occurs when the feed already has html entities in it. For example, if the feed has a title of:
(It's an Honor)
When it gets run through check_plain, the ampersand in the html entity get converted to an html entity, and it becomes:
So the final output is:
in the title.
Comment #2
Steve Dondley commentedI can't properly display the html entities in the comments. It's all screwed up. Let me try with spaces before the semicolon. You should mentally remove them.
gets converted to
which results in the following output:
Comment #3
Steven commentedI'm pretty sure this is correct behaviour. Most feed fields contain regular, unmarked up text. Double-escaping like that in the source feed is only valid if the field contains escaped, marked up HTML text (such as the body).
In any case, this needs to be solved at the parsing stage, not the output stage. Drupal takes feeds in various formats.
Finally, using strip_tags() on output as a validation measure is disallowed. It should only be used as a conscious filtering op (such as done for taxonomy terms in title attributes).
Comment #4
Steve Dondley commented> Most feed fields contain regular, unmarked up text.
Well, Google uses htmlentities. They are a pretty major supplier of feeds.
Comment #5
Roadskater.net commentedyes google news is pretty important and i like it, and it would be nice to have at least a checkbox available in aggregator setup to specify whether to unescape the title. i know nothing about this, and can't do this myself, i'm sorry to say. i had other google news related problems (duplicate news items) so i'm open to suggestions from those who may have good reasons for thinking google news is not important, or not best. thanks for anything anyone does to help us. please share if there's an adopted fix. thanks.
Comment #6
kastaway commentedDoes anybody have brainstorming ideas of how to work around this? I'd settle for just dropping the entities from the RSS feed, which would be better than the current mash of ascii characters on the front page of the site.....
Comment #7
matt westgate commentedRather than
strip_tags(), you'll want to usefilter_xss($item->title, array())around the item title. It's been shown on the security mailing list thatstrip_tags()can be bypassed in terms of XSS exploits.Comment #8
rosenblum68 commentedI downloaded newest version of 4.7.3 aggregator.module, and it still has the problem. I has to modify the file in multiple locations (using advise for filter_xss) to get it to work both in the block AND the "more" summary page... just a heads up. http://wellweight.org
Comment #9
edmund.kwok commentedChanged strip_tags to filter_xss as suggested and in two other places, block_item and summary_item, including the original page_item.
Btw, issue also applies in HEAD, http://drupal.org/node/63459, marking that duplicate because this was reported first. Also, changing version to cvs to get more attention.
Patch is for cvs version.
Comment #10
edmund.kwok commentedPatch for 4.7 cvs.
Comment #11
ahoeben commentedIn this issue (which got sidetracked), I suggested cleaning up the title before it is inserted in the database. This has the obvious benefit of cleaning it up only once, making my patch a lot smaller than the one proposed here.
The argument against cleaning up the tile before insertion in the database is that it is not the Drupal way to do so. For example, when adding a title to a node, the title is inserted into the database as is (after making it database safe); no removal of tags etc. The rationale behind this is that when the user goes to edit the node, he would expect his/her original input and not a parsed/filtered version of it. There is an obvious need to keep the original input, for consistency to the user.
In the case of the aggregator module however, there is no need to store the original input, which is machine generated and which will never be edited. So I'ld say: filter before insertion in the database, and be done with it.
Comment #12
jacauc commentedWill this patch be part of drupal 5.0 core?
I am running drupal 5 CVS on a test site, and I still see
& # 3 9 ;(spaces inserted there to prevent it from being parsed)Comment #13
drummTags need to be stripped from titles.
Comment #14
edmund.kwok commentedReleasing this issue back into the wild. I'm not sure what's the best way to fix this..
Comment #15
msmiffy commentedI see that this problem still exists in 5.1. Any sign of a permanent, main-stream resolution? I'll just go hack the code for now as this is UGLY.
Comment #16
jacauc commentedI agree 100%
Comment #17
csevb10 commentedI repatched this for Drupal 6.
There's an aggregator_filter_xss so you can actually filter the feed content independent of the site content which seems like a slightly better solution than invoking the filter_xss directly. I patched the same 3 areas as before.
What does everyone think of this as a viable solution moving forward?
Comment #18
csevb10 commentedComment #19
agentrickardI'm going to make a run at closing the Aggregator queue for D6.
Personally, I like http://drupal.org/files/issues/aggregator-striptags.patch and agree with ahoeben from #11.
This is machine-text, so keeping the "integrity" of the original title string is not relevant. Stripping the entities seems perfectly fine during the parsing stage.
Comment #20
catchNo longer applies.
Comment #21
ezra-g commentedSince it was only one line, in D5.3 I just made the quick edit, removed the items from the feed, updated the feed and had the same #39 business.
Comment #22
underpressure commentedWhat is the status of this problem? I use Google news and get this ugly output as well.
Comment #23
alpha2zee commentedDrupal's architecture needs to be changed to allow admins complete control over filtering of both input (what is stored in the database) and output (the final, displayed HTML). Further, this filtering should be customizable as per every content type (newsfeed, user comment, and so on). E.g., machine-generated newsfeed titles (database stored) can be filtered for XSS, appropriate HTML tags, etc., during the input stage to avoid the overhead of similar filtering everytime the title is output as web page content.
Also, appropriate code/principles should be used from better (than Drupal's Filter module) filtering scripts like htmLawed and HTMLPurifier. Though the mentioned scripts can be used in plugged-in modules, they then either cannot have certain functionalities (like, to address the newsfeed-entity issue), or re-do some actions that Drupal's core does anyway (increasing the processing time).
Comment #24
cburschkaWhat is the valid standard in XML -
"or " or & #39;? I don't know how much more attention people pay to feed validity than website validity - would it be enough to require validity and reject quirky feeds, or do we lose a lot of functionality?Edit: I note that whatever filter is here on d.o. is one whose code I would probably yell upon seeing. You do not unescape & amp; # 39; twice to make '. You just don't.
Comment #25
alpha2zee commentedLines 289, 1179, 1267, 1352, 1367 and 1394 of the drupal/modules/aggregator/aggregator.module file (version timed 1-10-08 22:14) have code like:
... check_plain($item->title) ...
Looks like replacing all those six check_plain occurrences with aggregator_filter_xss should take care of the issue.
Comment #26
jdefay commentedI implemented the changes suggested by ahoeben above in his patch in post #11. Then I tried changing all the check_plain references to aggregator_filter_xss, but still got funky characters in Google News feeds on my site .
ahoeben's patch seems to clean titles that show up in feed blocks, but not in the Drupal aggregator category view which was still giving me funky single quotes in feed titles. It looks like the funky symbols are still being stored in the database, and ahoeben's patch fixes them when they are displayed in blocks.
Since the funky stuff was still getting displayed I wanted to remove them before they go into the database & thus make ahoeben's display patch unnecessary. So I added htmlspecialchars_decode() in the aggregator.module aggregator_parse_feed function.
It works great, whenever a "& #39;" shows up in the title of my news feeds, it's replaced with a single quote and then inserted into the database for later use.
Here's the line before:
$title = $item['TITLE'];
Here it is after:
$title = htmlspecialchars_decode($item['TITLE'], ENT_QUOTES);
Comment #27
TimAlsop commentedCan somebody let me know what patch/changes are recommended for a Drupal 6.3 environment ? I am happy to modify code, but wanted to know which code changes to make so that these special characters are changed before the google news feed items are written to the database.
Comment #28
dominich commentedFor me on 6.3 it's as the above post. I have a google news feed displayed in a block on a site, and the title links were showing &blah; style text - much in the same way that Firefox RSS feed reader does for sites like Slashdot et all interestingly.
Anyway - all I had to do was as jdefay says:
add htmlspecialchars_decode() in the aggregator.module aggregator_parse_feed function.
Here's the line before:
$title = $item['TITLE'];
Here it is after:
$title = htmlspecialchars_decode($item['TITLE'], ENT_QUOTES);
jdefay rox.
D
Comment #29
TimAlsop commentedI tried this, but when I update feed I get:
Fatal error: Call to undefined function: htmlspecialchars_decode() in /data01/mysite/public_html/drupal/modules/aggregator/aggregator.module on line 738
Is there something else I need to do so that this function is available ?
Thanks,
Tim
Comment #30
TimAlsop commentedI just noticed that the
htmlspecialchars_decode()function is only available in PHP >= 5.1.0. I am using PHP 4.4.4 which is supported by Drupal 6.3. Unfortunately I am unable to upgrade PHP because my site is hostsed on a server managed by my ISP and uses cpanel. So, the version of PHP is out of my control.Is there a PHP 4.4.4 function which will do same/similar, or do I need to suffer this until PHP 5.1.0 or later is available ?
Thanks,
Tim
Comment #31
TimAlsop commentedI found some suggestions at http://uk.php.net/htmlspecialchars_decode
So, I have now changed code as shown below:
I don't get any error now, so I will see if I get any news items with special characters included. I will report my findings in next few days.
Comment #32
bradnana commentedThis bug still exists as of D6.6 in core aggregator.module. Any plans for a patch to be brought into core?
--Brad
Comment #33
GetActive commentedIt also/still happens on the "domain.com/user" page where the title is generated dynamically below the login form.
Comment #34
domesticat commentedI can confirm that @jdefay's patch (#26) works well for >PHP5; I've been using it for months. I have not tested the other version, nor can I vouch for whether or not doing this is 'the Drupal way.' (I just know that my users need the feeds to work properly!)
Comment #35
problue solutionsthank you jdefay in #26, after much useless information your advice has finally solved my problem :)
Comment #36
cvining commentedjdefay,
I just looked at your site, which has a Google News Feed here: http://jason.defay.org/aggregator/categories (titled 'UCSD In the News').
How did you get that to work? When I setup something similar, all the ampersands (&) are stripped out of the links, which breaks them. Example:
http://news.google.com/news/url?sa=T&ct=us/0-0&fd=R&url=http://www3.sign...
http://news.google.com/news/url?sa=Tct=us/0-0fd=Rurl=http://www3.signons...
Any suggestions? Thx.
-- Cronin
Comment #37
jdefay commentedHi Cronin,
I just looked at the Google News Feed 'UCSD In the News' you mentioned on my site and noticed it does in fact have the ampersands in the links. Are you seeing something different on my site?
I just upgraded to 6.10 and haven't reimplemented any of these patches described in this thread. So I can't say for certain if the patches will actually strip the Google tags or not.
What I can say is that I got frustrated with the way Google feeds were causing frequent problems with the Drupal aggregator. I switched over to Yahoo news feeds and am getting consistently clean results. It's too bad because I like the Google news service better and would prefer to use it over Yahoo. I just didn't want to deal with headaches anymore.
Jason
Comment #38
jdefay commentedAll,
Since Cronin asked about it, I decided to go in and re-implement the simple patch I described in my earlier post to this thread.
I added the htmlspecialchars_decode function back into the aggregator.module, removed all the old items from the news feed, then refreshed it. Viola, no more funky characters in the news feed titles.
Since several new updates/releases of Drupal have happened since my original patch, and all of them still contain the old problematic PHP code, perhaps someone can volunteer to help me get this fix added to the next version of Drupal so we don't all have to keep re-patching every time a new release comes out.
Please feel free to respond to this thread and/or email me if you can help make this happen.
Cheers,
Jason
Comment #39
jdefay commentedTim,
Have you had any errors on this yet? If not, your aggregator patch seems to be a better, more backward compatible, improvement over mine.
I implemented your version and tested it on my site. It works great so I'd appreciate it if any of you who are reading this & willing to help would do the same and report back here.
Cheers,
Jason
Comment #40
jdefay commentedOops, I shouldn't have changed the patch status since it looks like the original patch isn't the one we trying to implement. I'm setting back to 'code needs work' until someone can create and submit a patch that meets the Drupal patch standards. Here is what I'm proposing someone help me do:
Write a valid patch that replaces line 737 through 741 with the following:
As soon as that patch is up and tested I'll work on getting it into the queue for the next Drupal release.
Cheers,
Jason
Comment #41
domesticat commentedBeen using this patch for a while with no issues; would be glad to see it get in the next version.
Comment #42
cvining commentedJason,
"I just looked at the Google News Feed 'UCSD In the News' you mentioned on my site and noticed it does in fact have the ampersands in the links. Are you seeing something different on my site?"
No, your site looks fine. But my site (http://www.zts.com, see the section "Google Web Search Filtered for Recent Thermoelectric Content"). Check the links: "&"s are stripped out, and broken. I checked and they are stored in the DB that way too.
I just upgraded to drupal 6.9 (a day before 6.10 came out!).
Any thoughts on what's going on? Thanks for the replies.
-- Cronin
Comment #43
jdefay commentedSounds like the patch isn't working for some reason. Have you done all of the following?
1. Checked to make sure you have PHP version 5.1.0 or greater installed on your server
2. Changed line 741 in the aggregator.module from
$title = $item['TITLE'];to$title = htmlspecialchars_decode($item['TITLE'], ENT_QUOTES);3. Removed all previous posts from your DB and re-imported them.
You might also try out the patch I just created below. Please give me feedback on the patch, it's in need of QA testing!
Thanks,
Jason
Comment #44
jdefay commentedHi everyone,
I've created and tested the attached patch on my Drupal 6.10 site and am looking for volunteers to do additional patch testing.
The patch chages the aggregator.module as generally descibed in my posts above. It first checks to see if the server has the htmlspecialcharacters_decode() function available (PHP 5.1.0 and greater). If so it uses the function to clean up HTML in the article titles and saves the results to the database. If the function isn't there for some reason, it defaults to the prior method for saving article titles.
I'll give it a few weeks for testing, then if I don't hear anything I'll assume it's good to go and try to get it into the next patch release.
Thanks,
Jason
P.S. Thanks to domesticat for turning me on to WinMerge!
Comment #45
cvining commentedJason,
Thanks much for the help, but after further testing & searching I'm pretty sure my problem is distinct from this thread.
A drupal thread (Aggregator Module Shows HTML Gibberish) which described my problem quite closely (dropping of key symbols like "&") is at this link: http://drupal.org/node/346990
It seems there is a known bug in one of the php libraries, libxml2 2.7.1,which strips out key html symbols (like <, >, & etc.). The bug is described here: http://bugs.php.net/bug.php?id=45996
My host's php installation has libxml2 2.7.2, which (if I'm reading the libxml release notes right) doesn't have the fix in it. But the latest release, libxml2 2.7.3, should. So only a few systems will be affected by this particular bug, and it will go away as the php libraries get updated.
In mean time, guess I'll use some work-around.
Thanks again .
Comment #46
jdefay commentedI fear there may not be sufficient traffic on this thread to get additional patch testing done. After waiting a few weeks for testers to evaluate the final version of the patch, and not getting any responses, I've gone ahead and updated the status to "reviewed & tested by the community".
While nobody seems to have tested the final version, it was tested and improved by a number of users since it was first created in May of 2006 by Steve Dondley. Since those earlier iterations led us to this final version of the patch, I think it has been sufficiently tested to be committed to the next version of Drupal.
I apologize in advance for not being able to get other developers to provide a supporting opinion on the patch. However, I'm confident this patch will work just fine, particularly since the final patch checks to make sure the
htmlspecialchars_decode()function is available on the server before running it.Cheers,
Jason
Comment #47
jdefay commentedAfter re-reading the Drupal PATCH instructions, it appears that I should be upgrading this bug to Version "6.x-dev", so that's what I just did :-)
Comment #48
packdragon commentedI've been having problems with my aggregator in that my feeds are displaying HTML code. I've got Drupal 6.10 installed. This patch sounds like exactly what I need. I clicked on the attachment, but it appears to display some text in my browser. How do I download and install this patch?
Comment #49
catchThe patch seems to be reversed - htmlspeciachars_decode() is removed, not added by #46.
Additionally the current development version of Drupal is 7.x rather than 6.x - where possible we fix issues in 7 first, then backport. http://api.drupal.org/api/function/aggregator_parse_feed hasn't changed that much (although it's in a different file now), so it'd be roughly the same change to make, although Drupal 7 requires PHP 5.2 or greater, so no need for the function_exists() there. Only did a very cursory review of the patch, but if you could re-roll against 7 that'd help to get some more reviewers.
Comment #50
alex_b commentedThis might work.
Comment #51
cburschkaThe patch looks good, and this is a great idea, but we definitely need a test case for it.
Comment #52
jdefay commentedThanks for re-rolling this Alex_b, sounds like we're ready to test & patch
Comment #54
jeffschulerRe-rolled for current D7 HEAD.
Comment #55
jeffschulerRe-rolled for current D7 HEAD.
Comment #57
jeffschulerTestbot says that the Error handlers test failed. It passes on my machine.
Patch still applies to HEAD.
Re-setting to Needs Review for another shot.
Comment #59
MichaelCole commented#55: 61456_html_decode_titles_2.patch queued for re-testing.
Comment #60
s4j4n commentedsubscribing
Comment #61
gausarts commentedI have my aggregator feed titles ended with
 .Subscribing. Thanks
Comment #62
jody lynnComment #63
agentrickardSo after 5 years, we should just declare that we don't care and close this.
Moving to D8 is pointless.
Comment #64
jody lynnLOL, I don't think this one is really that bad, and it's finally in 'needs review'. (I was trying to update the versions on the more promising issues).
Comment #65
agentrickardWell, the patch is green, and should be RTBC, so let's give it a try for 7.1.0.
Comment #66
jeffschulerI started writing a test for this for verification/assurance. The included patch adds this test but does not include the patch in #55, (nor any other proposed changes in this issue,) in order to allow testing with-and-without such changes.
The test in its current form adds a feed with an item whose title includes a quote (") and an ampersand (&).
However... these look to be displaying properly -- using SimpleTest and adding the feed manually -- without patching.
Am I testing this properly?
Is anyone actually seeing this error in D7?
I had some issues with testing the apostrophe ('). I see the correct output (manually and in SimpleTest's verbose results) when I use it in the test feed item's title, but
assertText()doesn't seem to acknowledge it.Changing this issue back from RTBC seems appropriate.
Comment #67
jeffschulersorry, here's the test...
Comment #68
agentrickard@jeffschuler
Now if you can just combine the patch and the test into one, set the issue to Needs Review and let TestBot try it out.
Comment #69
jeffschuler@agentrickard:
Sorry if I wasn't clear: the test passes without applying the patch.
We should demonstrate that something is broken, [change the test to do so,] before fixing it.
Comment #70
agentrickardSo you are suggesting that this actually got fixed somewhere else?
Comment #71
agentrickardMarking 'needs review' to test the test patch.
Comment #72
jeffschulerEither it's been fixed elsewhere or I'm not testing it properly.
I just tried the same test feed (generated in #67) in Drupal 6 and the entities displayed properly. So, perhaps I'm not testing the correct conditions?
The test uses a manually-generated RSS 0.91 feed (copied from the existing RSS091 test file) whose only item's title includes & and " entities.
I've added items to this feed using the title phrase "It&39;s an Honor" (from comment #1,) as well as a few other examples folks cited as problems in this issue, and they all displayed properly in D6 and D7.
Maybe someone experiencing this issue could point us to a feed they're having a problem with?
Comment #73
agentrickardThe test passes and accounts for the original condition, so I suppose this was fixed elsewhere and we can close this.
If it recurs, we can re-open?
Comment #74
jeffschulerSounds reasonable to me.
Comment #75
smscotten commentedPatch in #55 worked for me, mostly. This suggests to me that the result of #66 is a faulty test condition, not that the problem magically fixed itself. Testing against an external site known to cause the problem may be a better metric than creating a local feed to test against. (Of course, maybe something else has changed between 7.0 and 7.7)
I said the patch "mostly" worked for me. ’ still appears in my feed titles, but that's a htmlspecialchars_decode() issue and may be outside the scope of this issue.
Comment #76
jeffschulersmscotten: can you point us to the feed you're having issues with?
Comment #77
smscotten commentedSorry, that probably should have been one of the first things I put in the post.
Feed: http://www.politifact.com/feeds/statements/truth-o-meter/
And here on my site: http://splicer.com/aggregator/sources/19
Ugh. Looked at the source. Looks like they have double-converted their characters to character entities, resulting in &quote; all through, as described in reply #1.
So the patch in #55 is a workaround, not a fix, because the behavior in the aggregator isn't wrong.
Um... right?
EDIT TO ADD: I sent mail to politifact.com and got a response back saying they were looking into it so it may not even show the issue much longer.
Comment #78
David_Rothstein commentedI saw this issue recently also, but same thing as above; it turned out that the feed itself (on the source site) was incorrectly escaping its titles. So there's no bug here for Drupal to fix, at least not in D7/D8.
If an actual bug is still reproducible in Drupal 6 (i.e. with a feed that is formatted correctly on the source site but broken when imported to Drupal), someone could feel free to set this issue back to 6.x.
In the meantime, the tests in #67 look pretty solid so it's worth getting the patch rerolled and committed; tests are good regardless of whether the bug itself exists...
Comment #79
jeffschulerCool. Rerolled #67 for 8.x.
Comment #80
David_Rothstein commentedPatch looks good to me. The tests pass, and they're completely consistent with the way the other tests in the same area of the code are written.
I did a quick reroll to remove the "No newline at end of file" issue from the newly-added file. This should be good to go.
Comment #81
David_Rothstein commentedAh, but someone is going to come point out that Drupal documentation standards now require the PHPDoc to say "Tests a feed.." rather than "Test a feed.." :)
Fixing that in the attached.
Comment #82
xjmHaha, you heard me coming! But also....
Indentation is goofed on the second and third lines. Needs one more space before the asterisks.
Comment #83
xjmFixing that. No commit credit please. :P
Comment #84
xjmOh, and yeah.
Comment #85
dries commentedCommitted the tests to 8.x. Moving to 7.x.
Comment #86
dave reidThis appears to have broken tests. Failure on
"Quote" Amp&" foundhttp://qa.drupal.org/8.x-statusComment #87
andypostthis file was not commited
Comment #88
dave reidComment #89
sunWhy are you testing the page output that has been converted to plain-text?
When testing HTML escaping/sanitization/entities, use assertRaw() to check the actual, unprocessed content in the page output.
assertText() runs the entire page output through filter_xss(), which performs a plethora of HTML escaping, entity conversions, and validations.
Comment #90
pillarsdotnet commentedPatch suggested by #87 and #89.
Comment #91
pillarsdotnet commentedPatch for real this time.
Comment #92
pillarsdotnet commentedNote that since HEAD is broken, this is a critical bug.
Comment #93
andypost+1 to commit asap
Comment #94
andypostComment #95
pillarsdotnet commentedComment #96
dries commentedSorry about that. I just committed the patch in #91. I think that should fix HEAD. Let's see ...
Comment #97
dries commentedComment #98
David_Rothstein commentedLooks good - seems like we can still use a patch for D7.
Regarding assertText() vs assertRaw()... either should be fine here since it's just a text string. Leaving it as assertText() actually has the nice property that it verifies that filter_xss() doesn't do anything funny to
"or;&(which it shouldn't), but I suppose that's an extremely backwards way to test that :) Either one is OK.Comment #99
albert volkman commentedD7 backport. I *think* I got it right.
Comment #101
albert volkman commentedTrying again.
Comment #102
David_Rothstein commentedShould probably use assertRaw() rather than assertText() to be consistent with what went into Drupal 8.
Comment #103
albert volkman commentedGood call.
Comment #104
patcher commenteddoes anyone know, is there a similar patch for the feeds module? i am importing a xml with feeds and the html entities are not shown correctly in the title
Comment #105
xjm@patcher: This is a core issue. Try looking in the feeds module queue.
Comment #106
aascherson commentedHey guys,
Long time drupal user but not a pro so maybe I am doing something dumb here. I am getthe the tags in my titles from a google alert feed. Been looking everywhere for a solution to this and trying to apply this patch to drupal 7.15 core.
using git, I get a fail on :
checking patch modules/aggregator /aggregator.test ...
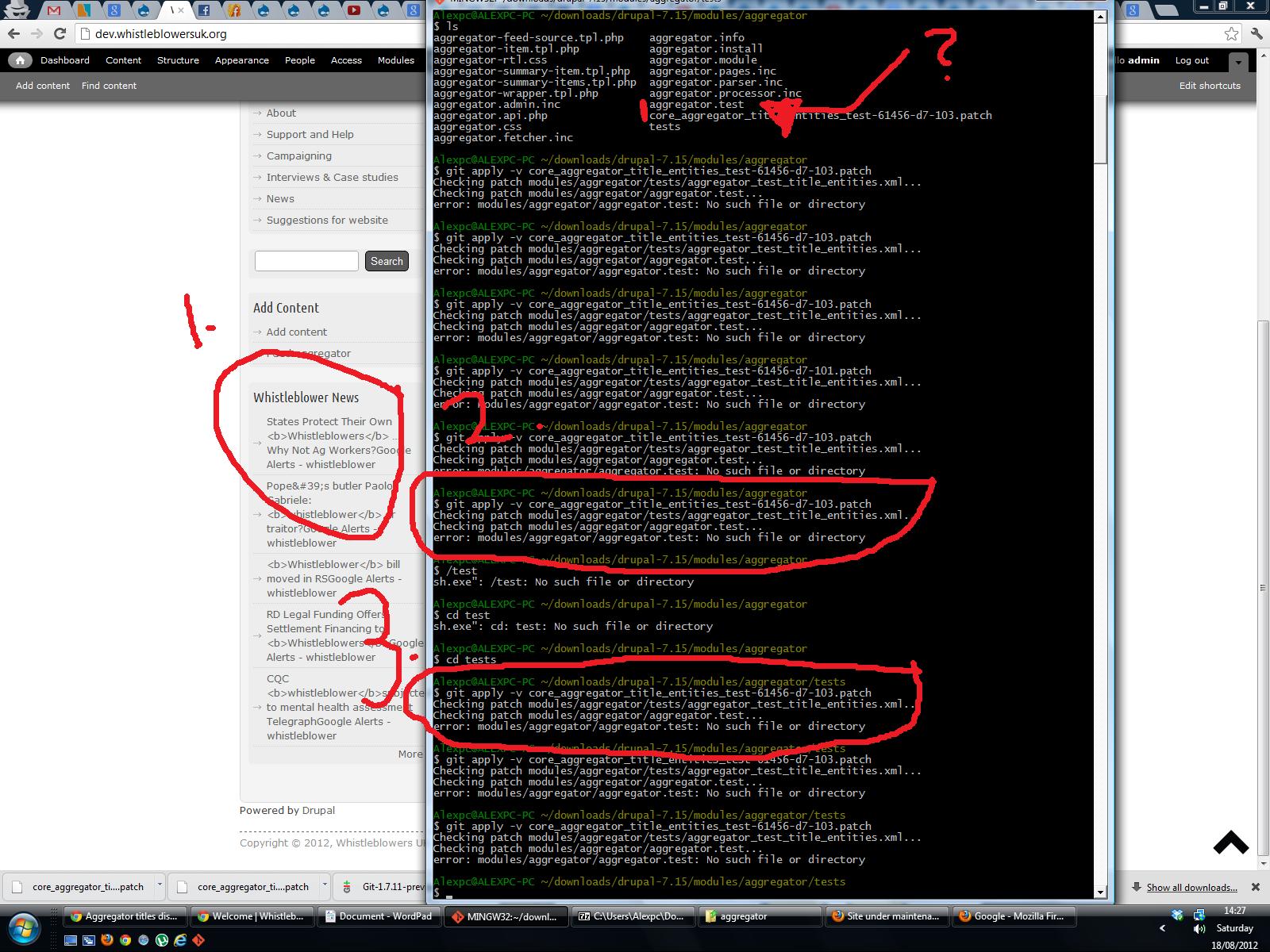
I get a file not found error. So it finds the patch, but not the test file that I can see there in the directory. Am new to git, am I doing something stupid? Any guidance would be really appreciated as this is driving me nuts. Have tried to look to see if I can apply patch manually but cant seem to work out what needs to go where on this one. Apologies if this is a newb moment.
For reference I am running this from the modules/aggregator directory, which is also where the patch is. Tried running from /test as well but same problem.
Comment #107
lundj commentedIs there any solution in one of the last versions of the aggregator.module?
In version 7.17 I have the same problem with Facebook-RSS-Feeds: http://cl.ly/image/220U1V26180j on http://junge-akademie-wittenberg.de/projekt/sprache-und-politik (right sidebar at the end of the page)
The related Feed for this one: https://www.facebook.com/feeds/page.php?id=301588419892418&format=rss20
Is there any solution for this?
Comment #108
albert volkman commentedRe-roll.
Comment #110
albert volkman commentedOops.
Comment #111
fbreckx commented#110: core_aggregator_title_entities_test-61456-d7-110.patch queued for re-testing.
Comment #112
fbreckx commented#110: core_aggregator_title_entities_test-61456-d7-110.patch queued for re-testing.
Comment #113
rtrubshaw commentedNot proud of this, but since the views that referenced the aggregator feeds already had template files I simply ran the entire output through strtr().
E.g. in "views-view--twitter-feed.tpl.php":
<ul><?php print strtr( $rows, array( '&amp;' => '&', '&#' => '&#', ) ); ?></ul>(and similar code for other full feed template files)
I found that Twitter, Facebook and Flickr have all - at times - stuck HTML entities in the title. YMMV
Comment #114
chirikamo17640 commented#55: 61456_html_decode_titles_2.patch queued for re-testing.
Comment #115
liam morlandPossibly related to #2011918: Titles are often double-escaped (including in the content attribute of the dc:title meta element for nodes).
Comment #116
ggevalt commentedWow.
This has to be one of the most incredible threads on Drupal forums.
The problem began in 2006 on Drupal 4 and folks seem to be still focusing on it for Drupal 8.
I'm in Drupal 6, I have the issue, and I see no resolution.
If I have missed something, please advise or provide a link as to the solution for Drupal 6 folks which still represent a substantial number of people.
Thanks so much for all you do.
cheers,
g
Comment #117
webengr commentedany fix for this? I agree hard to believe drupal 7 is doing this with a standard install. ?
Comment #118
albert volkman commented@ggevalt Issues are fixed upstream as to avert regressions.
@webengr Have you tested my latest patch? When a patch is in "Needs Review", it's helpful to test out the patch, report back your findings, and possibly mark the issue as RTBC.
Comment #119
mimes commentedTest patch in #110 applied.

Results:
Comment #120
albert volkman commented110: core_aggregator_title_entities_test-61456-d7-110.patch queued for re-testing.
Comment #121
albert volkman commented@mimes That's odd, it's still passing on the bot. Do you have a vanilla setup?
Comment #122
guillaumeduveauMmmm... spent a while on this. I could sure help with testing the test patch, but I what I believe, it that it's a real-world situation we have with feeds that already have html entities in it, like the original author of the issue said in comment #1 7.5 years ago. I can't really see what the test helps with that. Having an option to html_decode_entities by feed item was proposed and forgotten. I'd happily submit a patch to include that option if any Core maintainer gives me the green light.
Otherwise here is a solution to html_entity_decode the titles without hacking Core. We define and use a new parser thanks to hook_aggregator_parse, in a custom module "mymodule". Basically it's exactly the same parser except that we replace in the copy of aggregator_parse_feed() :
with :
You have to choose the new parser on admin/config/services/aggregator/settings. Here the code of mymodule.module :
Comment #123
Irene Meisel commentedtested patch #110 it worked. no fatal error on ubuntu. new test ran + passed.
Comment #124
Irene Meisel commentedComment #126
David_Rothstein commentedCommitted #110 to 7.x - thanks!
(And I switched t() to format_string() in the test assertion message on commit, since that was changed everywhere in core a long time ago.)
I'm really unclear if there's any functional bugs left to fix here (especially in Drupal 6) but someone can reopen/retitle or create a new issue if there is.
Comment #128
gojensen commentedMaybe I missed something, this still didn't work for me using a facebook page feed... Had to replace the check_plain calls with aggregator_filter_xss as mentioned in post #25. This was running on v7.31. (I could see everything from patch #110 was added, but didn't seem to resolve this specific issue...)
Another problem I have is that when I import the feeds "something" parses the content/description and changes all urls from absolute urls (i.e. http://facebook.com/ ...) to relative paths (i.e. /pagename/photos/image.jpg)... so when a user reads the post and wants to click a link or tiny image in the post they get a drupal error about the site not being found. Anyone know WHERE the scripts strips the url?
Comment #129
gojensen commentedComment #130
liam morlandThe "needs review" status is for issues that have a patch which might fix the issue.
Comment #131
mediaformat commentedSeems fixed for the
<item><title>, but not for the<channel><title>Comment #137
poker10 commentedMoving back to Fixed. If there are any problems left, please create a new issue (feel free to link it here). Thanks.