
Ok, this post is gonna be long and include various graphics. Might want to grab a cup of coffee. Also, disclaimer: This is just documentation of what I've learned from spending way too many hours staring at this stuff, and reflects my current understanding which may not be 100% correct. But it's a place to start talking, anyway. :)
This weekend, Dave Reid and I had a chance to "sit down" on IRC and go over the architecture of the XML Sitemap module, some of its flaws, and how to generally make the module scale on high-performance sites. Dave has been toiling on some code in his sandbox that basically represents a ground-up re-write of the xmlsitemap module with various architecture improvements. I want to share some of those here with you so that we can brainstorm about how (and I guess if) to bring those into the XML Sitemap module.
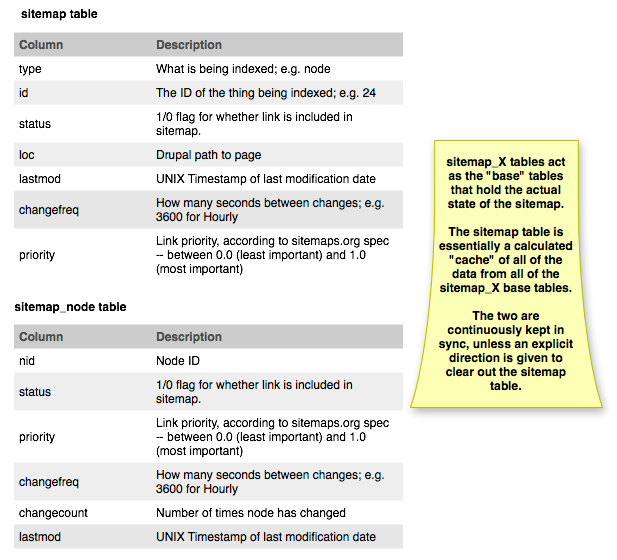
Let's start at the data model. Here's the data model for Sitemap module:
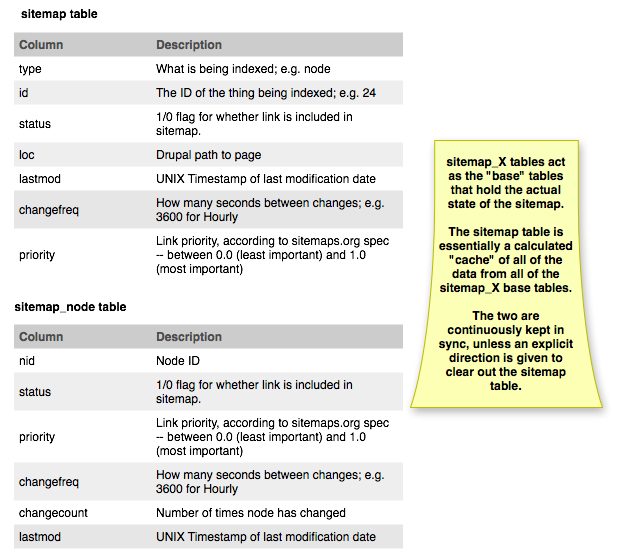
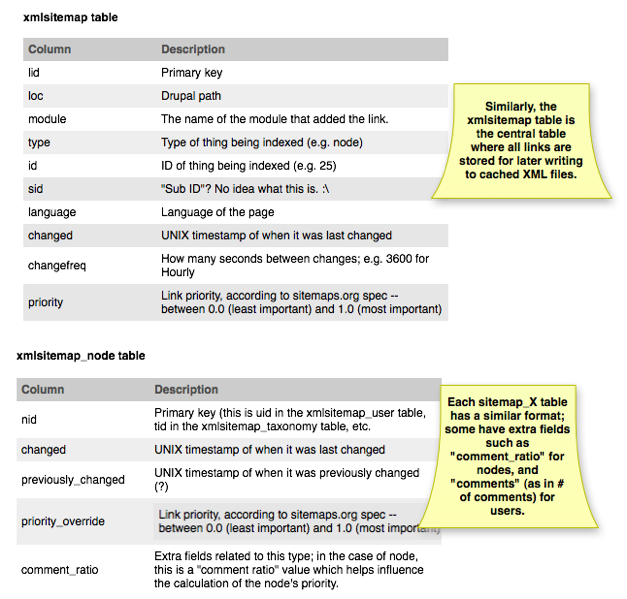
And here's the one for XML Sitemap module:
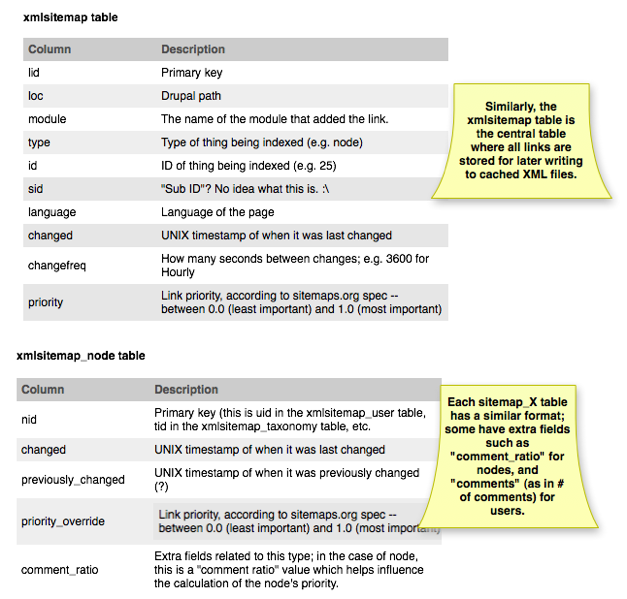
Both are pretty similar in both their form and function. Each module that adds links to the sitemap has its own table where it tracks its data, and there's a central "sitemap" table that holds an aggregated view of the entire thing. When the cache files are generated, they pull data out of the central table rather than having to calculate it all the time.
Sitemap has pulled out some columns, such as the lid field (opting to make both "type" and "id" a composite key) and the perplexing "sid" field (what is that for, anyway?). Sitemap also archives *all* of the link properties in both places so that it's easy to tell what's changed.
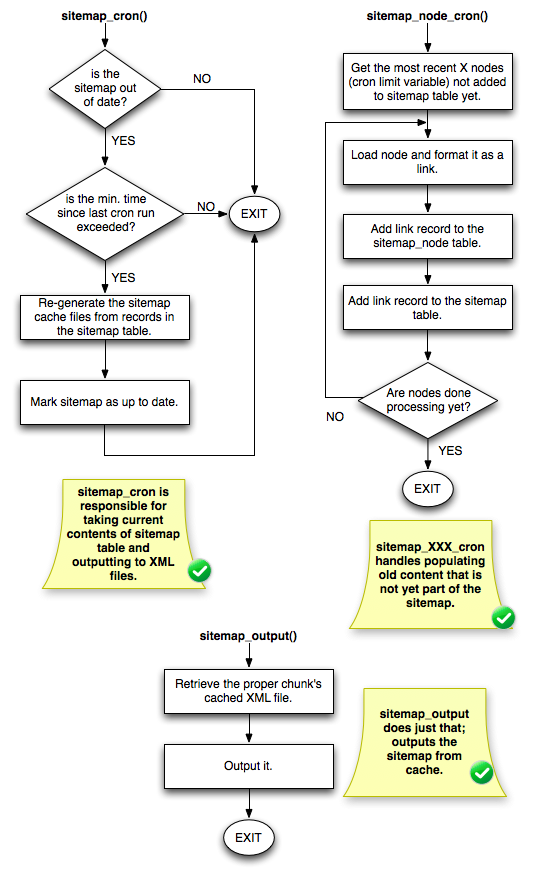
Where the modules really start to differ is when we look at their "populate sitemap vs. serve sitemap" logic. Observe a flowchart for sitemap module (note: I haven't drawn flowcharts like this for like 5 years so forgive me if they're off ;)):
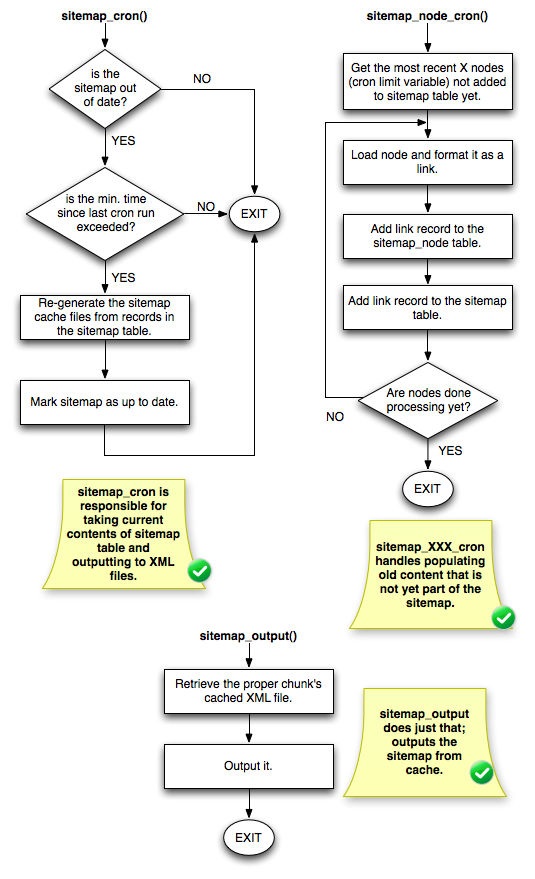
All of the expensive operations -- generating the sitemap cache files, populating legacy content into the sitemap tables, etc. -- are done on cron. Additionally, it does some neat tricks like switching to an anonymous user *while* gathering the list of links, populates legacy content with newest stuff first (so that if you have 100K nodes being processed 500 at a time, the stuff you posted yesterday will end up in the sitemap first, and the stuff you posted 10 years ago can wait a few days). But best of all, sitemap_output() is *really* simple: it merely reads the file out of cache and renders it to the browser. Done and done. This is important because the primary audience for sitemap.xml is search engines, and you want them to get results quickly.
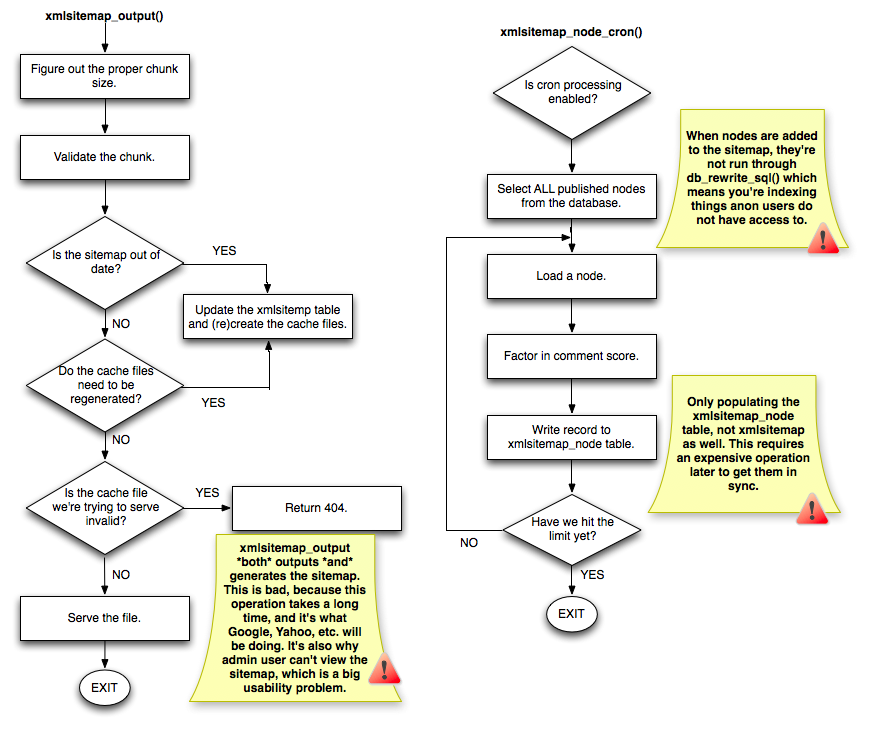
Contrast that with a flowchart of the existing XML Sitemap module, which has some issues in this regard:
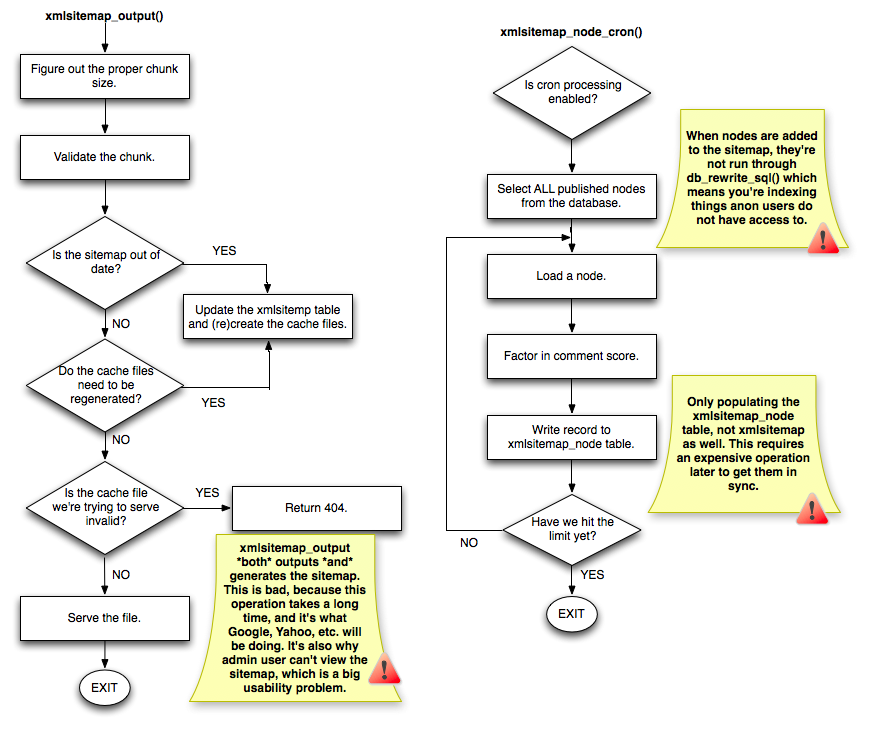
The first major problem that I see is that xmlsitemap_output() does *not* only output the sitemap. It seems to be a "jack of all trades" callback, which both generates *and* displays the contents of the XML file. While I can see how this could work fine on a site with 50 nodes, this is not a good thing on a site with several thousand, because that means Google's going to sit around waiting for a bunch of XML files to get generated instead of getting the sitemap contents when a site has 100K nodes. Instead, it should be able to grab the 2MB+ file as quickly as possible.
I also notice some issues with the way legacy node content is populated into the tables. Rather than using something like db_query_range() to select only X number, all published nodes are selected into a result set. That result set is then looped through, one at a time, and added to the sitemap. The problem is, that list of nodes is not run through anything like db_rewrite_sql() to see if the anonymous user has access to it, which I think is why XML Sitemap does that awkward thing of only allowing user 0 to see sitemap.xml.
And then just in just in general, the code in sitemap module is a bit more compartmentalized and easy to understand, at least for me. A lot of the patches I've filed so far have just been a result of me struggling through xmlsitemap's code and going "Wait. What? Why does it work that way? Shouldn't it be this?" Kiam has done an amazing job of answering all of my questions (and committing lots of improvements!), but I still can't help thinking that the XML Sitemap module is a bit more complex than it needs to be, and could be better broken up into smaller functions that each do one thing and do it well.
Now, as far as where to go from here.... well... let's talk about it. :)
| Comment | File | Size | Author |
|---|---|---|---|
| #54 | xmlsitemap v2.png | 165.4 KB | webchick |
| #35 | sitemap.php.txt | 7.18 KB | baldwinlouie |
| xmlsitemap flowchart.png | 205.23 KB | webchick | |
| sitemap flowchart.png | 162.74 KB | webchick | |
| xmlsitemap data model.png | 182.92 KB | webchick |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
DamienMcKennaNot to be too crazy, but could XMLSiteMap be rewritten to build off SiteMap?
Comment #2
RainbowArray+1
Would love to have a workable sitemap module. Thanks so much for looking into this!
Comment #3
Dave ReidI wanted to put down a couple other major things that I wanted to note as well. When the user wants to completely clear and regenerate the sitemap data (with the data from hook_sitemap_links()), there is also a hook_sitemap_links_batch() that works with some optional parameters in hook_sitemap_links() to ensure that a complete regeneration can be completed in a batch process for large sites.
Second, last I knew was that the {xmlsitemap}.loc field actually stores the aliased path (content/kittens) instead of the 'normalized' Drupal path (node/1). So what happens when a bunch of node aliases are changed from content/[title] to stuff/[title], you have either a large portion of the {xmlsitemap} table that is out of sync and needs to be corrected one by one. If just the normalized path is stored, and we look up the current alias during the sitemap file generation, we're always going to ensure we have the correct and latest path/alias. Note, I can't confirm this is still the current behaviour, because I can't get the latest version to import anything in my {xmlsitemap} table. :/
Note that the code in my sandbox has maybe had at most 10 hours of development in it from my spare time this last week or so. It's rough and doesn't include every single feature. But it has already been stress-tested by several people and represents the kind of changes I feel are necessary.
Comment #4
quicksketchSubscribing. I've frequently had to be the bearer of bad news regarding XML Sitemap, telling clients straight-up: "If you install this module, it will take down your site." Unfortunately the SEO people that no nothing of performance tell everyone to turn it on, only to have the site come crashing down even after the warning.
I've looked at David Reid's implementation and it does seem quite a bit more sane when dealing with large amounts of content. I really like the idea of "chunks" that are regenerated as needed, rather than regenerating the whole fricking sitemap on every node or comment change.
However, even this implementation is not quite perfect. The use of "chunks" is brilliant, but the problem exists that the sitemap.xml page can still take a long time to output while the cache table rows are all retrieved and appended to each other. This is fine if the site map is out of date, but upon request it would be ideal if this final generated file would simply be saved to sites/default/files/sitemap.xml. Then future requests to sitemap.xml would just be a pass-through to the already generated file, making the request super-fast since it'll just be reading a real file from disk.
Comment #5
Dave Reid@quicksketch: That's the current behavior of both xmlsitemap (I think) and my sandboxed code. The difference with the sandbox code is all the data is absolutely ready to go in the {sitemap} table. Just read from the table and output to file, repeat. Then when the engine/user requests the sitemap.xml path, use file_transfer() to output the correct file.
Comment #6
DamienMcKennaTo give a bit more detail.. it just seems that XMLSiteMap should be:
If SiteMap is doing the indexing well, why not reuse it?
Comment #7
quicksketch@Dave Reid: Ah, sure enough. Looks like I should've read the code more carefully. :-)
Comment #8
jbrauer CreditAttribution: jbrauer commentedSubscribing. Like Nate I've had to explain to sites that the reason they are crashing is the extraordinary load the current xmlsitemap places on their site. I would like to see a way to keep the sitemap on disk if at all possible.
Comment #9
netaustin CreditAttribution: netaustin commentedI strongly prefer Sitemap's approach.
My first contributed Drupal module was simplesitemap (now removed from CVS by me for being awful), which, awful though it was, managed to scale by using SimpleXML to directly edit the XML files, which were stored in-place and streamed out using rewrite rules rather than PHP processing. Here are my concerns.
I'd love to see some consensus around sitemaps emerge; it's critical to running Drupal on big sites. Let's make it like RSS handling: a simple, easy to modify (has a hook) default that works for 99%, and a lower-level API so that the other 1% is at least spewing data in the right format.
Comment #10
justin.hopkins CreditAttribution: justin.hopkins commented+1
Thanks for looking into this issue.
Comment #11
EvanDonovan CreditAttribution: EvanDonovan commentedBrilliant. Thanks to everyone at work on this. I think it would be ideal if XML Sitemap could do the expensive sitemap-building operations on cron (possibly split over several cron runs the way search index does it) and then used SimpleXML or something similar to output the {sitemap} table into a static XML file. My organization's site has over 70,000 nodes so I fear that the current architecture of the module would cause PHP timeouts, etc. when Google or Yahoo tried to view the sitemap.
Comment #12
apadernoActually, {xmlsitemap}.loc does contain the canonical URL; xmlsitemap_node.module inserts values like
'node/'. $node->nid.Comment #13
deadprogrammer CreditAttribution: deadprogrammer commentedI only recently realized how scary this module was and how badly it was hurting our million-node site. I am writing a custom sitemap generator for now.
Here's what I don't understand. Is there really a need for node_loads and hooks? A simple enough join of the node table and url_alias should do the trick, as is writing the output into a file. Why does a sitemap need a table to store the data?
Comment #14
apadernoThe database table is required because differently would be hard to sort the site map content by the links priority; it would be also harder to calculate the number of site map chunks that the site map must use to not have more than the allowed number of links per site map chunk.
Also, it's not true that a simple join with the URL aliases table would be enough; in a multilingual site, each node can have a path alias for each enabled languages. If the query would limitate itself to grab one random path alias, then that would be enough; it doesn't return the correct value, anyway.
Comment #15
dman CreditAttribution: dman commentedThanks for taking the time to write this up.
I still haven't got any insights, but I looked at the existing state of code a few times and just couldn't get my head into it. I'm really glad to see some restructuring going on.
Any convergence with sitemap proper would help a lot on the UI side of things!
Comment #16
giorgio79 CreditAttribution: giorgio79 commentedTalking about simplexml I am strongly against it. Why? The newer php xmlreader is much better suited for such a task, as it is a stream based parser and with it you can process easily a 2GB xml file with an 8MB shared host.
How?
Check it here:
http://www.ibm.com/developerworks/library/x-pullparsingphp.html
Comment #17
dman CreditAttribution: dman commentedYes. If scaling is ever going to be an issue, then you have to eat the extra complexity of xmlreader etc.
XML was designed from the ground up to be stream-process capable. And that's cool when you work with it. SimpleXML and DOM are just easier. But not the tools for scaling problems.
Just choose the tool for the job...
Comment #18
giorgio79 CreditAttribution: giorgio79 commentedI was thinking about this a bit more, and I am not sure if it is possible, but with xmlwriter / xmlreader would it be possible to simply edit an existing xml file instead of recreating it every time there is a node operation, such as delete, create etc?
It would be much more parsimonious to add 2 new nodes at cron run, or upon creation then to recreate the whole thing (with 50 000 nodes in the db :D)
Comment #19
Darren OhMy preferred way forward would be for Dave Reid's code to be released as XML Sitemap 6.x-1.0. Dave, would you be willing to make the necessary file and function name changes?
Comment #20
apadernoI am not sure if using
db_rewrite_sql()insidehook_cron()is the perfect way to proceed.The query passed through
db_rewrite_sql()could return a different set of nodes data simply because the access permissions are changed.Suppose that the first time the query returns data for A, B, C, and D (and those are all the nodes present in the database), while the second time it returns data for E, F, and G. The table would then contain data for A, B, C, D, E, F, and G but we don't know if the anonymous user still have access to the first inserted nodes; the consequence is that the database table would contain data for nodes that should not be referred in the site map.
The code would be slower to be executed, but the table would get populated with data of nodes to which the anonymous user doesn't have access; in other words, the result doesn't change.
Comment #21
stormsweeper CreditAttribution: stormsweeper commented@Apparently Sitemap dummy switches to uid 0 (i.e. anon) before running the query.
Comment #22
apadernoI also don't understand why the approach is to still use a database table for each module, and a central database table.
hook_cron()would populate two different tables at the same time, when it would be possible to only use a single central database table, and execute half of the SQL queries.If we are going to completely change the code, then we can also change the way the database is used.
Comment #23
Anonymous (not verified) CreditAttribution: Anonymous commentedNot before we have a release of the current code base. It's getting very close to working for at least 85% or more sites. People be a bitchin' and it's too late to upset the apple cart for 6.x-1.0. Such things belong in 6.x-2.0 which I think we should be able to tag issues to including this one. Kiam, could you at least create a version tag? You don't need to show the 6.x-2.x-dev file on the project page.
Comment #24
DamienMcKennav6.x-1.x should only be released if it isn't going to overwhelm sites with more than a few hundred nodes.
Comment #25
webchickWell, I should be clear about a few things:
a) I intended this big, over-arching discussion to be more for the 6.x-2.x release. I agree with Earnie that getting a mostly unbroken 1.x release of this module out ASAP is a good and happy thing.
b) While sitemap's fundamental architecture is more sound than xmlsitemap's currently, it's important to note what Dave said in #3 about his module only having about 10 hours of development on it so far, and not all of the features implemented yet. For example, it doesn't deal with multilingual sites, it doesn't handle search engine submission, the XML strings are built in memory then written to disk rather than written as they go along, etc. None of these are insurmountable problems, but they'd certainly come as a nasty shock to people expecting something that behaved like 5.x-2.x.
c) Right now, the flowchart graphic for XML Sitemap has a three red exclamation points. If I had drawn this same flowchart graphic back when I first looked at this module two weeks ago, there would have been more like 50, and I probably would've had to figure out a way to make them blink and scroll across the screen menacingly. Kiam has been extremely busy since then solving all kinds of the issues that I and others have raised, and the module's in much better shape now. For example, while I haven't tested it in a few days on my 25K+ node test site, I at least am confident that it can now be enabled on a site this large now, which was not possible two weeks ago.
d) If Darren Oh is interested in seeing the improvements Dave's made in XML Sitemap module, then something that might be worth considering is giving Dave Reid commit access to the 6.x-2.x branch. That way Kiam could continue to solidify the 1.x release while Dave is leading the charge on the high-performance version in parallel, and (assuming everyone who's chimed in here pitches in a bit) we could hopefully see an alpha/beta release in a few weeks, as opposed to a few months.
Comment #26
apadernoIf 2.x is going to be developed, and that branch doesn't contain code coming from the 1.x version, working on the 1.x branch is just wasted time. It would be better to sit, and wait for the new branch to come out from the microwave.
What is the purpose to develop two versions that are completely different from each other?
Comment #27
webchickIMO the purpose would be:
1) Get a working release of the 28th most used project, which is linked from thousands of resources on the Internet, including Google.com's documentation for third-party libraries, for Drupal 6.x as soon as possible. Drupal 6 has been out for more than a year, and this module constitutes critical functionality for many websites out there. The fact that it isn't ready yet is directly hampering Drupal 6's adoption, so this has become a larger, "For The Good Of The Project" issue.
2) As Dave pointed out, there are nearly 10,000 people using the highly volatile -dev branches on their sites right now. In fact, usage of the 6.x version which isn't yet released eclipsed the usage of the 5.x version back in late January. This hampers our ability to make the sweeping changes we need to do, because we're affecting live, production websites with every commit.
3) Once a release is out and threads with 200+ replies finally die, we'd have plenty of time to give a very thorough analysis to the module's underlying architecture and wildly refactor as needed, without having to worry about affecting 10,000 sites. We can also then benefit from all of the various thinking that has gone around this module by all of these high performance sites that have had to switch to their own custom solutions since this module was never able to be installed on their sites before.
Comment #28
apadernoOne of them could be removed; or one red exclamation point should be added to sitemap.
Using
db_rewrite_sql()insidehook_cron()(especially when the nodes table is analyzed in different times, as XML Sitemap already does) doesn't avoid that the table used for the node links contains references to node that the anonymous user cannot see.Also, it's not true that the actual implementation of
hook_cron()load all the nodes; it loads X nodes at each invocation of the cron maintenance tasks.Comment #29
webchickSorry; my bad! There is no db_rewrite_sql() in sitemap module. Here's what sitemap module is doing:
The sitemap_node_create_link() function which formats the node in sitemap link format. Its status property (a 1/0 boolean that determines whether the link should be indexed) is determined by sitemap_node_get_status() which does:
So in other words, all nodes are listed in the sitemap / sitemap_node tables; but only those that are viewable by anonymous users (and have not been deemed specifically unindexable) will get output to the cache files.
Comment #30
webchickAlso, I should point out my motivations here, since I'm not sure that those are clear.
My motivation is not to belittle the work that Kiam and Darren have done on this module. It obviously works well for a wide subset of sites, or it would not be the 28th most used project. :) There are also a lot of things this module gets right, and a lot of really tweaky and difficult problems (like the sitemap "chunks" stuff) that have already been thought through.
However, this module is notorious for absolutely killing the performance of sites with hundreds of thousands of nodes and tons of user-generated content flinging back and forth every second. One of the first things we do on a performance optimization gig when we encounter a site that's struggling to stay online is check for this module, and switch it off if it's enabled. And often times, that's enough to stop their servers from melting, and their infrastructure team's pagers from going off. To a large extent, this is because cache invalidation is a really difficult thing to get right, especially when you're dealing with such inter-related subsystems such as nodes, comments, and taxonomy terms, that all influence each others' scores and need to be escalated to search engines when they get deleted.
If you look at any high-performance Drupal site out there with a sitemap.xml file, I will guarantee you that they are either using a method such as a python script to trawl through access logs, or have re-written this module completely from scratch. The only difference between what Dave did and what dozens (if not hundreds) of other Drupal developers have already done is he put his re-written code out there for people to look at. And he did it in his sandbox so we didn't get into the messy situation of a "Better Sitemap" module or something, which serves only to confuse users and divide development efforts.
So. My interest in posting this thread is to try and get all of those dozens or hundreds of developers in the same "room" and figure out a way we can take what they've learned and put it to work for the larger Drupal community. Please don't interpret it as a personal attack of any kind, Kiam, because I do really appreciate the amazing work you have done the past couple weeks.
Comment #31
antiqel CreditAttribution: antiqel commentedSubscribe.
Comment #32
apadernoI don't take it like personal attack. The only thing I care of is the project, and its code quality; if somebody can make it better, I can only be happy because I am first a user of XML Sitemap.
Let us face the realty; in the past commits, I made too much errors, I didn't understand what the users were telling me, and I was not able to catch the suggestions given from who was only trying to offer the right persective on how the code should be developed.
Comment #33
baldwinlouie CreditAttribution: baldwinlouie commentedInteresting post. And good job everyone!
I had the same experience when I needed to create a sitemap for a 50k node site. I struggled with xmlsitemap for two weeks before I decided to write my own.
I ended up writing a custom script that generated my sitemap once each night. Its nothing fancy, but crawlers only hit static xml files, solving my performance needs.
Then for anything critical such as news or articles, I created a news sitemap, again, with a simple query for the last 4 days worth of stories. The Google news sitemap specification states you only need a rolling index of 4 days of data.
One of the things I started questioning when I was struggling with xmlsitemap is whether a sitemap _TRULY_ needs to contain the most up-to-date information each time a node is created or updated. What if the approach to this problem is for the xmlsitemap module to spit out a new static sitemap once a day?
A sitemap merely is a roadmap for the crawler. Google's crawlers should be sophisticated enough to find new content, even if the sitemap is 24 hours behind.
Comment #34
webchickWould some of the people like baldwinlouie who had to go their own way on this be able to share some of their code? It'd be nice to compare/contrast different approaches people have taken.
@Kiam: Rad. Glad to hear such a good attitude coming from you! :D
Regarding the quality, a simple thing to do would just be to switch to more of the core development process, where a patch gets at least +1 from someone before it's committed. Of course, that's easier if you have more "formal" co-maintainers than people who flit in and out of the issue queue here and there.
The ultimate thing to do, of course, is write simpletests to ensure that once a feature is working it continues to stay working. Dave's module has a .test file in it, although I confess I haven't looked at it closely.
Comment #35
baldwinlouie CreditAttribution: baldwinlouie commented@webchick,
I'm attaching a php file of what I did for my site. It is pretty basic and a lot of the things supported in xmlsitemap is not present. My assumptions when writing my script is 1) only certain node types were needed in the sitemap, 2) the user's profile url was part of the sitemap, 3) views listings pages are not included and 4) primary menu, secondary menu and a few other menu items have to appear.
The script takes about 1 minute to query all my nodes, user profile urls and menu links and spit out a sitemap. The script uses the DRUPAL_BOOTSTRAP_FULL so I can use all the drupal functions.
My script could use a lot of work and the code is sloppy, but it gives an idea of how I did things.
Let me know if you have questions.
Comment #36
Dave Reid@baldwinlouie/#33: Only having the sitemap generated once a day is easy to do if a 'minimum sitemap lifetime' is implemented, which I've done in my sandbox code. In your case the minimum sitemap lifetime would be 24 hours. The best reason I can explain for having separate tables for each data type (e.g. node, user, etc.) we can save our 'custom' information like nodes specifically excluded from the sitemap, nodes with specific priority values, or a node's change frequency, we don't want to lose that data if/when we need to completely regenerate/rebuild the sitemap information.
@baldwinlouie/#35: Thanks very much for sharing your code!
Comment #37
apadernoThere are many reasons to generate a site map on a daily basis.
The first reason is that the site map content must be keep in synch with Drupal settings. This means that when the web site starts to use clean URLs, the site map content must be updated; it's also true when the path alias of a link present in the site map is changed.
Another reason is that the content of the site map depends from the actual conditions, which change from day to day; the anonymous user can have access to a node to which he didn't have access before (therefore, that node must be added to the site map).
The site map is not a static entity; if it would be, then it would be easier to create its content with a Drupal page you manually change.
Comment #38
apadernoI am changing the priority basing on what reported here.
I don't see much of a discussion, or I have not understood the topic of the discussion.
What should the topic of the discussion be?
Comment #39
gddWell the first discussion was "Is this new code a good thing and is anyone interested?" and I'd say the answer to that was a resounding yes. Now it seems like the discussion is, how and where does this code get integrated? The options being
1) Clean up and create a stable release of the -1.x branch, and then start the new code in a -2.x branch
2) Scrap the current -1.x branch and start over
I 100% agree with webchick in #27 that option 1 is the way to go, for all the same reasons. Not much I have to add there. Getting davereid (and possibly others) in as co-maintainer(s) to drive the new branch while kiam drives home the -1.x branch seems like a perfect solution to me.
webchick also raises a good point in #34 about going to a more core-like commit process for quality control. We do this in the Services module - no patch gets committed unless one of the other maintainers gives it the +1. It definitely raises the bar for code quality, and personally I'm always thankful to get more eyes on my code. The down side is that when everyone is insanely busy (and that is most of the time) then patches are very slow to move. Still, I wouldn't have it any other way. Having a few active trustworthy maintainers would help keep the queue moving and improve the quality of the module immensely.
Comment #40
gddSorry didn't mean to change priority.
Comment #41
Anonymous (not verified) CreditAttribution: Anonymous commentedUpdating to the correct version.
Comment #42
apaderno@#39: The problem is that the number of maintainers actively involved in the code development is less than the numbers of maintainers currently active for the Drupal project; the number of people that are not maintainers of this project, and that participate more actively in the development is 2.
If then you considerate the number of people who proposed a patch to the code, in the last month, you will see how the community offers a help to the development.
Would you use the same development process used for Drupal core code, in the case of XML Sitemap?
Comment #43
DamienMcKennaKiam: I've wanted to help but was unsure where to start (hence my questions on #359104). I'm intending looking at the Google file "creation" later today, presuming someone else doesn't provide a patch first.
Comment #44
gddKiam: The overall scope of this module is also much smaller than Drupal core. If xmlsitemap had 2-3 active co-maintainers you could get a lot of work done, especially after a stable -1.x branch is shipped.
Comment #45
apadernoThe point to start is an existing issue; find an issue you are able to resolve, and create a patch for that.
That is what I normally do, except that in my case I can directly submit the code I change. If you want to be sure you are doing it in the desired way, read first the answers given to other reports.
Comment #46
apadernoThat is exactly what the project missed.
If you check how many people became maintainers in the last 6 months, you will see they are just 2; if you check how many maintainers committed code in CVS between November and February, you will see that number is 1.
If anybody is able to develop code for this project, he could ask to become co-maintainer; the project would make a jump (hopefully forward :-)).
I really wish more people would actively help with the project, and become co-maintainers.
Comment #47
webchickRegarding the bulk-population of legacy content, I was reading through #212084: perform bulk updates during cron and/or via the batch API which is basically the same problem for Pathauto. Because this is something that only needs to be done once (or very rarely), another option is just making a one-off script like the one at http://drupal.org/node/236304 which does *only* the import and can be put on a cron job that runs every 5-10 mins to get through the back-log rather quickly, rather than invoking *all* of the enabled modules' cron hooks every 5-10 mins which might NOT be what you want.
Might be worth looking into, unless XMLreader is smarter than I think it is and can eliminate the need for database tables whatsoever.
Comment #48
Dave ReidI have officially been added as an XMLSitemap 6.x-2.x maintainer. I have created #449998: XML sitemap 6.x-2.x-dev progress to let other know when I've finished brining my code over from my sandbox (why I didn't just name everything xmlsitemap instead of sitemap, I'll never know...).
I'm a big proponent for code review for modules with more than one maintainer. Let's really try to attach patches to any issue we can so we can review code for inefficiencies or bugs before it gets committed. With as large of a userbase this module has gotten, it's going to call for more responsibility.
To everyone else, please keep sharing your custom sitemap modules that you have had to code! All of us can learn something from each and every one and I'm personally studying each one to find the best and brightest ideas/code for the new 6.x-2.x branch.
Comment #49
Anonymous (not verified) CreditAttribution: Anonymous commentedI agree with this as long as there are responses. If a patch is lingering more than a couple of days without a comment then letting the fix to the masses should allow for the review process. At least though, the patch will be posted to an issue and is more easily obtained.
Comment #50
apadernoI guess that the key phrase is with more than one maintainer; I am assuming he is referring to the code review as a maintainer task.
Comment #51
apadernoI think that a single report for such topic would be only confusing.
It would be better to close this report, wait for the code to be passed from a repository to the other, and then we can open a report for each different topic. Dave can say when his code is ready to be reviewed, and people can open reports.
I can imagine the mess in this report, with people suggesting a different way to proceed, asking if the code is going to be changed as they suggested, etc.
I don't think it's possible to follow a comment, and the answers to that comment, here.
Comment #52
webchickThe nice thing about this thread is it has replies from a bunch of people who've already solved this problem. If we discuss here about general approaches, or ask questions to the group, then those people get the issue bumped in their tracker and can chime in. It can act as a central place to "brainstorm" in this way.
If we split this into 10 sub-issues, we're going to lose the focus. That said, I agree there will never be a "patch" here. What I picture is we create our 10 sub-issues and cross-link them here, then close this issue out when the 6.x-2.x is released and we no longer need all of these brains.
Make sense?
Comment #53
Anonymous (not verified) CreditAttribution: Anonymous commentedI agree that this is a brainstorming thread and the work is done in another issue; therefore changing the component.
As I'm trying to debug some issues preventing a -rc release; I'm constantly thinking that one table is all that is needed, a cron process (hook_cron for smaller sites and a separate script for larger sites) to create a static sitemap.xml report and that static report is what is given to the search engines. Dynamic is great but there are times it just isn't the right thing to do.
Comment #54
webchickYeah, I've always been confused as to why we need tables for both the individual modules and the overall sitemap. I noticed Dave did the same thing though. I remember asking Dave, and I remember him replying and it sounding reasonable, but I can't remember what he said. ;) Could one of you guys elaborate on why this was necessary?
So, earnie, is this basically what you're saying?
Comment #55
webchickOne question I'm not sure of, do we need to ping out to search engines when we delete a link? Or are they smart enough to compare their old copy of your sitemap with the new one?
Comment #56
hass CreditAttribution: hass commentedI'm not aware about a way to delete something via sitemap.xml... leave a node responding with 404 and the node will be removed from SE.
If I remember correctly - one of the biggest 5.x performance issues from past was - one url() function call per link. This produced 130.000 single DB requests only on the url_alias table on one of my sites and crashed the generation process. I think this is why the aliases have been cached in the xmlsitemap tables and only synced from core tables.
Comment #57
Dave Reid@webchick/54: Let me see if I can try an explain reasoning for storing a few different tables. So let's say you've got a full {sitemap} table but you've noticed that something is wrong and for some reason, you'd like to rebuild the whole thing. The first thing that is done is
DELETE FROM {sitemap}. If all of our data is stored in that table we've just now lost all of the custom node priorities, change frequencies, etc. If we store the *custom* data only in the separate tables, we can then load that custom data when the relevant entries are inserted back into {sitemap}.@webchick/55: They should be smart that if they go to deleted links in a sitemap and see "Oh craps! There's a 404 on this link now.". Search engines rechecks the newest sitemap.xml and sees there is no longer a link to that page found.
Comment #58
Anonymous (not verified) CreditAttribution: Anonymous commentedI'm thinking that moving the control fields (changed, previously_changed, comments (or comment_ratio) and priority_override) to xmlsitemap is all that is needed. Updating the xmlsitemap dynamically instead of xmlsitemap_node, xmlsitemap_user, etc. Then xmlsitemap_output() just needs to create the report and not update the data significantly reducing the time to create the report.
Comment #59
apadernoActually, I was reporting about the need of a single, central database table on the comment #22, 2 days ago.
The code that was contained in the 2.x branch I committed (the code should have been updated, but I stopped to do that to better shape the 1.x code) already used a unique central table.
@#56: It's true that if you leave a dead link in the site map, the search engine will get a 404 error; it's also true that Google Webmaster Tools would fill a page with warnings about not existing pages, and will force you to tell it which pages it must remove from its internal database. I am not sure people would be happy to do such task.
Comment #60
Anonymous (not verified) CreditAttribution: Anonymous commented@Dave: Can you give a scenario of "you've noticed that something is wrong" that can't be fixed without destroying the data with a sudo rm -rf /?
Comment #61
webchick@Kiam: Sorry! I must've missed #22 in all the back-and-forth. Good to hear you're on the same page.
@Dave Reid: Well in that scenario, the sitemap would be rebuilt over time during cron, just as the search index works and just as sitemap module works by populating legacy content that's not part of the sitemap yet, no?
Comment #62
apadernoThat is the reason I said that a unique report for a plethora of comments about different sub-topics is not a good idea. We would have started to talk about the database tables to use 2 days ago, which means 2 lost days.
I agree with what webchick says; the tables used from the modules seem a sort of backup tables that would help in rebuilding the central table in case of some problems.
In this case, there are some considerations to do:
Comment #63
Dave ReidI shouldn't have said that they are backup tables, but rather, they store extended information related to that particular type of sitemap link. For instance, Drupal's {node} table stores the basic node information. {node_revisions} store the node bodies, etc. {poll_choices} stores the choices people can select for nodes that are polls.
With respect to xmlsitemap, the xmlsitemap table should probably only store:
- node id
- comment count, etc
Comment #64
webchickOk, that I could see: storing data that is required to calculate the proper priority, etc. But I can't see much point in archiving *everything* in those tables.
Comment #65
webchickAlthough, I wonder. Should that kind of stuff be in an 'xmlsitemap_extras' module or similar, which uses hook_xmlsitemap_links_alter() to let you fine-tune node priorities, and offers those as a couple of examples?
For me, about the only thing I'd need is a custom priority per content type. Pages should show higher than Articles which should show higher than Forum topics. I don't care enough (nor do I want to incur the performance penalty) to set a custom priority per node based on a selection form, nor (heaven forbid) based on a comment count which will change literally every second on my client's site.
I'd love it if xmlsitemap.module just did the basics and left that fancier fine-tuning stuff to "contrib" modules.
Comment #66
Dave Reid@webchick: Totally agreed. The separate tables should only store the information that makes sense to keep separate. I think I'm almost leaning towards keeping advanced priority calculation out of the responsibility of xmlsitemap. Modules like Popularity can do all the comment ratio calculations, and that should actually remove any need for any extra tables besides the one {xmlsitemap} table.
Comment #67
Thomasr976 CreditAttribution: Thomasr976 commentedSubscribing
Comment #68
Dave ReidHmm...the idea of an xmlsitemap_extras module for the custom priority and inclusion/exclusion is interesting. More brainstorming...
Comment #69
apadernoThe idea of using already existing modules is fine.
In the specific, the Popularity project should at least be released as development snapshot, or official release. How much will we wait before to see an official release of that module? I am not sure that saying to the users they should install a development snapshot of a module if they want a feature more (we suggest to not use the development snapshot of XML Sitemap, but at the same time we would push people to use the development snapshot of Popularity) would be a good idea.
Comment #70
Dave ReidI'm not saying we're going to be pushing users to do anything soon. I'd probably make sure to devote a little time to developing Popularity and get a stable release working before I'd ask users of another module to depend on it for another feature. This is not an issue right now. We're just brainstorming.
Comment #71
apadernoI understand we are not pushing anybody to adopt a module before the time; still we should think if XML Sitemap users would be happy to have a dependency on third-party modules. In the code I developed there aren't any dependencies from third-party modules; they are used if they are present, but the project code works fine without those modules.
Brainstorming is also to see the cons of the possible choices; if we just see the pro of something, we would be probably going to think that all is wonderful, even when it's not.
When I introduced an extra module, I was asked what its purpose was, and why it has been called in the way it was called. Now there is the proposal to create an extra module.
Comment #72
natrio CreditAttribution: natrio commentedsubscribing
Comment #73
bwv CreditAttribution: bwv commentedsubscribing
Comment #74
Thomasr976 CreditAttribution: Thomasr976 commentedI'd be curious on what the rule of thumb is on Drupal? Would relying on another module that is not a stable release violate a policy, best practice, or is it routinely done?
I'd like to comment as a user also. Many of the current modules rely on other modules for basic functionality and some on advanced functionality. While I personally like the relied upon module to be a stable release, I wouldn't mind it if all users were given adequate notice in the documentation on the project page of xml sitemap.
Comment #75
Dave ReidRelying on a module that doesn't have a stable release isn't a good practice, but there's no standards that say it shouldn't or can't be done. Some modules have very stable development releases, some don't. It depends on the situation.
This situation (which I remind everyone is just brainstorming at this point), would *not* be a requirement or dependency on another module, it would be the xmlsitemap working just fine on its own, but 'enhanced' with a more advanced feature if another module is installed. Not having all the complex stuff will allow the module to do what it does best. This also would probably allow us to trim down to just one table for all links instead of a separate table for nodes, users, etc.
Comment #76
Thomasr976 CreditAttribution: Thomasr976 commentedThanks for clarifying that. Now the question is whether that would satisfy the needs of the majority of the websites/users out there who are using version 5 or some form of 6.
Since we are brainstorning, this issue also begs the question, who are you really designing the module for? Large sites with over 200,000 nodes (that's an arbitrary number), etc. etc. I don't have a feeling for that, but I think it is relevant to ask in terms of who will want those advanced feautures and are they part of your main target audience you are trying to serve.
Comment #77
Anonymous (not verified) CreditAttribution: Anonymous commentedRE: Relying on unstable releases:
If a module has a dependency on another module that isn't yet ready for prime time then the module depending on that module isn't ready for prime time either. Would you ship a c++ program dependent on a library that is known not to be ready for production? It is the same idea with a PHP module.
Comment #78
litwol CreditAttribution: litwol commentedIs it very important for SEO to _sort_ the total sitemap result set after it have been generated ? If we can avoid sorting then performance of this module is not that bad. There are other optimizations that depend on the answer of whether sort is really very important.
Comment #79
Dave Reid@litwol: The new 6.x-2.x-dev branch will not have any sorting while reading from {xmlsitemap} to generate the files.
Comment #80
webchick@Kiam: The key difference between xmlsitemap_fancy_priorities.module and xmlsitemap_helper.module is that in this case we would be splitting the module up by separating out an optional feature, where in your case you were splitting them up by how often functions are used. This created a dependency in all modules on something that didn't do anything on its own; it was really just a place to house a bunch of functions used throughout. And since all of those modules already required xmlsitemap.module, it was sort of redundant and made things more complicated than they needed to be.
@Thomasr976: What I'm ultimately looking for is the simplest sitemap module possible, so that it can be installed and on a site with anywhere from one node to one million+ nodes. I want to stop getting frantic calls from clients whose database servers are completely melting under loads and whose IT departments' pagers are going off constantly, only to discover that this module being enabled is the reason behind it.
I don't think a scalable sitemap module is at all at odds with a sitemap module for "Mom and Pop, Inc." site with 5 pages, and see no reason why they can't both be the same thing. But until we solve the scalability problem for sites with many thousand nodes, I can't let this module anywhere near any of my clients' sites. And that sucks.
On the downside, I suppose, we'll have fewer opportunities to be complete superheros when we instantly cause clients' site performance to increase 1,000-fold by simply disabling this module once the 6.x-2.x module is finished. But that's a downside I'm willing to accept. ;)
Comment #81
apadernoWill the 2.x branch allow other modules to change the site map data associated to a link?
If it will allow that, then creating an additional module for changing the priority (or something else) would be easier. All the extra code that is now contained in one of the main modules (in the 1.x branch) can be moved to an additional module.
Comment #82
apadernoWe should decide which features are only for the 2.x branch, and which features can be implemented in the 1.x branch as well.
The risk is that the branches would otherwise become too similar to each other, and many users would be confused on which branch use.
Comment #83
apadernoMaybe it's a silly idea, but could not the code that would increase the performance of the project code be put in a module that the user could enable if he needs the increment of performance? In the case he is fine with the normal performance, he will not activate the module, and he will not see any advanced settings.
Comment #84
mstef CreditAttribution: mstef commentedJust after browsing over the initial workflow charts, etc - I really don't think any of this is necessary. It's comprehensive and nice-looking, etc, but just browse through Google documentation on sitemaps. They don't really consider anything other than the URL - except priority. Change frequency is ignored (pretty much) as well as every other attribute. I think this is a waste of resources and database space.
The only thing that is important to handle and keep track of is the amount of items being put into the sitemap. Google has a limit of 50,000 URLs per sitemap. If you have to exceed that you must create sub-sitemaps and a main index sitemap.
The makeshift solution I posted in the xml sitemap thread related to drupal 6 porting progress is a decent start from scratch and it's barebones. An admin settings page has to be implemented to determine which node types you want included, which tax categories, menu links, etc. Settings should also be added to determine how ofter to regenerate the sitemap (currently its set at every 24 hours). Also, submitting to search engines is a great idea, etc.
Comment #85
apadernoGoogle is not the only search engine that is able to handle a site map; the project should considerate its strange behaviors, but not depend totally from them.
For what I can see, Google is the only search engine that needs a custom meta tag to understand when two pages must be considerate the same.
It's also the only search engine that keeps memory of the links passed through the site map, when (IMO) it should simply take what the new site map gives it; this would avoid people to pass time writing relative URLs just to make Google understand that some pages have been removed (a manual task that should be avoided if Google would consider only the latest version of the site map that a module like XML Sitemap automatically creates).
Comment #86
Dave Reid@mikestefff: Thanks for sharing your code in the other thread. I'm looking through it now, and it looks like you have a start for something that works for you. However, for larger sites (and to answer your statement in the other thread), it is much easier, faster, and more efficient to have all the data ready to go in one {xmlsitemap} table instead of querying the {node} table with a join, the {menu_links} table, and then the {term_data} table.
BTW, I just want to let you know that doing:
url('node/' . $node['nid'], array('absolute' => TRUE));is much faster/easier than:
url(drupal_lookup_path('alias', 'node/' . $node['nid']), array('absolute' => 'true'));Thank you again for sharing your code (I have a folder where all this code is going so I can review). Please feel free to comment back here as the 6.x-2.x-dev release evolves!
Comment #87
mstef CreditAttribution: mstef commentedDoing
Gives google an ugly node/1234 url which makes using pathauto pointless - which ruins seo.
---
As for having the data ready, and not querying, the module I put together creates the sitemap.xml file and saves it on the server so when it is requested, it doesn't have to be generated. The module can be set to regenerate at specific time frames, etc. Well the whole point of writing it was for a quite solution before XML sitemap came out with a stable 6.x release. Creating a database and tracking every single thing would have taken me a while and it just didn't seem necessary at all to me. I just decided which values for each attributes to give to each URL type - example: nodes get priority 8, changefreq weekly, etc, or whatever it was. Doesn't make a difference to me.
Comment #88
Dave Reid@mikestefff: Truuust me. Using url() like that will automatically look up the alias for the path you give it. Anyway, we're getting off the subject. :)
On the 6.x-2.x-dev branch we are only building and saving the sitemap in specific intervals when cron runs (pretty much like your code). When the sitemap.xml file is viewed, it is all ready to go as well. Some early stress tests have shown that it is working really well for large and small sites.
Comment #89
webchickRegarding 1.x vs. 2.x, I think that 1.x is basically should be treated as a stop-gap solution to get a critical bug free 6.x version of this module out as soon as possible. Then our goal should be to make the 2.x module kick ass, and deprecate the 1.x module when it's released. Obviously, this is a discussion that needs to be had among the XML Sitemap maintainers, but that'd be my vote.
Regarding what Google does and doesn't do with sitemaps.org data, I personally feel that's irrelevant. We should conform to the spec. Google isn't the only search engine out there, as Dave mentioned, and Google could always change their minds later on how closely they choose to adhere to the sitemaps.org specification. Let's err on the side of conformance.
Also, since the whole point of this exercise is to build a sitemap module that can handle hundreds of thousands of nodes, I'm not very interested in a solution that craps out at 50K links.
Comment #90
webchickSome follow-up issues based on discussion here:
#451234: Support for extended sitemap formats (e.g. video, news, image, mobile)
#451240: Let sitemap.xml be served from the web server
#451244: Investigate into XMLReader/XMLWriter
There were also a couple earlier replies by @netaustin at #9 that I don't quite parse:
Er. Where is the sitemap keeping track of authoring information? Or is this about the news sitemaps?
Could you elaborate on that, Austin? (or anyone else who parses this)
Comment #91
apadernoMy parser must be broken as well (:-)).
The second note seems based on the wrong assumption.
hook_cron()updates the tables with the data that is not already present in them; it doesn't insert all data present in the Drupal core tables.Comment #92
Dave Reid@webchick/89: I agree that the 6.x-1.x version should basically move any and all feature requests (unless absolutely necessary) to the 6.x-2.x version. Anything that isn't a bug fix is likely to bring it more in line with the 6.x-2.x version, which is wasted time if we're going to have these two versions developed at the same time. Let's just get a bug free, stable, feature-locked version of 6.x-1.x out. Kiam and earnie, do you agree or what do you think?
Comment #93
apadernoIt was the doubt I express in #82.
I perfectly agree that only the 2.x branch should implement new features.
Comment #94
webchickOh, there was one bit of deadprogrammer's questions @ #13 which I don't know were really addressed here:
The node_load is required in order to perform a node_access check to ensure that anonymous users have access to view a node. Without that, you risk putting a bunch of 403 links in your sitemap, which I'm sure penalizes you in some way. This is important for sites with a mix of public/private content.
The hooks to allow modules to add links (and alter them) are also important because we can't forsee all of the ways in which modules will expose 'links' on your site. For example, a Panel Page might not be in the navigation menu, and definitely isn't a node, but could have a nice collection of feeds that you want indexed by Google.
Comment #95
webchickThis is totally OT, but someone e-mailed me to ask what I was using for the flowcharting stuff, so I figured I'd put it here too in case someone else was curious (I always hate answering the same question more than once :D).
The flowcharts were made with a Mac program called OmniGraffle (http://www.omnigroup.com/applications/omnigraffle/) and I'm using some stuff from the Konigi Wireframe Stencils (http://konigi.com/tools/omnigraffle-wireframe-stencils).
If anyone here also wants to float around some architecture ideas, you can also use free, open source programs like Dia, or Pencil. Or heck, scribble something on a napkin and scan it; doesn't have to be fancy. :D
Comment #96
baldwinlouie CreditAttribution: baldwinlouie commentedOne thing I ran into when playing with xmlsitemap is that I run all my cron jobs from a dedicated machine. Let's call that machine1.example.com.
So when the sitemap was generated from the cron run, all sitemap urls generated were machine1.example.com instead of the desired example.com.
A possible feature for the new 2.x branch will configurable base_url for sitemap urls.
Comment #97
Thomasr976 CreditAttribution: Thomasr976 commented@webchick/89 and site maintainers. Would the 1.x version that is in discussion here provide all of the functionality that is present in 5.x-1.6 version? Also are there any performance improvements with the 1.x version?
If the site maintainers agree with going with a 1.x version, lets make sure we fully disclose the issues in the project page, documentation, and readme text so people can make a "knowing decision."
Comment #98
Dave Reid@Thomasr976: At this point, the 6.x-1.x version is continuing to be a port of the 5.x-2.x version, which no more new features. We are just attempting to get a stable, bug-free version so people are not using development builds on production/live sites. The 6.x-2.x version is the rewrite which will have performance and scalability improvements.
I'd love for anyone to come help comment on improving the project page's documentation so we can help clarify/distinguish between releases. See #451642: Reorganize and slim down the wall-of-text on the project page.
Comment #99
Thomasr976 CreditAttribution: Thomasr976 commentedThanks for the clarification. I'd be interested in doing that. Let me take a look at the wall first to see where this is at.
Comment #100
Thomasr976 CreditAttribution: Thomasr976 commentedThanks for the clarification. I'd be interested in doing that. Let me take a look at the wall first to see where this is at.
Comment #101
David StraussAny need for me here? I'd love to help, but I don't want to read 100 comments.
Comment #102
andreiashu CreditAttribution: andreiashu commented@David Strauss: it has been decided that 6.x-1.x branch will be feature frozen so we can get a stable release (Kiam and Earnie are going to take care of that, with the help of the community of course). And Dave Reid is going to take care of the 6.x-2.x branch which will have performance and scalability improvements. Also the project page is in some cleanup, you can see the process being discussed here #451642: Reorganize and slim down the wall-of-text on the project page
Comment #103
Dave Reid@David Strauss: If you have time, I'd like for you to take a look at the current state of the 6.x-2.x code and see if there is anything glaring to your db-focused eyes.
Comment #104
whiztech CreditAttribution: whiztech commentedsubscribing
Comment #105
Dave ReidFor a summary of the current state of the module and where we are going to be headed, please read http://blog.davereid.net/content/state-of-drupal-xml-sitemap-2009.
Comment #106
kmillecam CreditAttribution: kmillecam commented+1 to Angie's suggestion (http://drupal.org/node/448000#comment-1534584) that private nodes be filtered out of the XML Sitemap.
I know my clients don't want search engines to have /even/ the URLs to their private discussions.
Thanks for all the great work!
Kevin
Comment #107
kmillecam CreditAttribution: kmillecam commentedSitemap module?
Where might one find the highly acclaimed Sitemap module so oft referred to in this thread?
Comment #108
Dave Reid@kmillecam: That's referring to the 'sitemap' module I had in my drupal.org CVS user sandbox. It is now available (and in progress) as the 6.x-2.x branch of xmlsitemap. See also #449998: XML sitemap 6.x-2.x-dev progress.
Comment #109
kmillecam CreditAttribution: kmillecam commentedThanks Dave,
I was confused (so what's new ;).
I thought there was a new and improved Sitemap module that rendered HTML pages like the XML Sitemap does for XML pages. I have a client who has spend big $$ on Google Search Appliances that can't read XML -- go figure?
Comment #110
NonProfit CreditAttribution: NonProfit commentedSubscribing
Comment #111
mason@thecodingdesigner.com CreditAttribution: mason@thecodingdesigner.com commentedsubscribe
Comment #112
Dave ReidI could use some architecture input on #472598: Architectual problem: Mass updating links from anyone here to help solve the next big hurdle in the rewrite.
Comment #113
Dave ReidAdding tag
Comment #114
Dave ReidCould use some db/optimization experts with #477072: Optimize the generate chunk SQL query.
Comment #115
Dave ReidWe could use a developer-oriented opinion on the direction/implementation of hook_xmlsitemap_links in #490660: Rename hook_xmlsitemap_links. In the hook should it return an array of links, or should it write links to a file?
Comment #116
Dave ReidI could really use some input and feedback on the one last remaining architectural problem in the 6.x-2.x version: #512216: Last architectural problem: override a link's status in the sitemap (inclusion/exclusion).
Comment #117
DamienMcKennaDaveReid: sysadmins and many managers are eager to know what can be done to help out the v6.x-2.x effort? Thanks.
Comment #118
Dave ReidA kind of pre-alpha release has been made: 6.x-2.0-unstable1. For all intensive purposes, it's basically an alpha release, but needs some testing to make sure all the latest big changes work just fine. We are back on track to get an actual alpha out soon if we get lots of testers, and onwards toward a 6.x-2.0!
I am going to mark this issue as fixed since we have the new branch progressing. I'd advise everyone to keep an eye on #449998: XML sitemap 6.x-2.x-dev progress for progress updates on 6.x-2.x.