Closed (won't fix)
Project:
Search API OpenSearch
Version:
2.x-dev
Component:
Code
Priority:
Normal
Category:
Bug report
Assigned:
Reporter:
Created:
10 Mar 2023 at 04:17 UTC
Updated:
6 Jul 2023 at 01:00 UTC
Jump to comment: Most recent

Edge ngrams are used to split up a word into chunks of characters and are useful for autocomplete etc. ElasticSearch/Opensearch have filters and tokenizers. The modules custom edge_ngram_analyzer is currently using an edge_ngram filter with a standard tokenizer. The standard tokenizir splits text up into words. When requesting highlights from opensearch (I'm using the bodybuilder.js library) the current setup returns a highlight of only entire words, even if the requested text is just a chunk of text. For example, if the request is "Marou" the highlighted excerpt that is returned is "Maroubra" when it should be "Maroubra". I've attached screenshots of the current and expected behavior (After I made some changes).
N/A
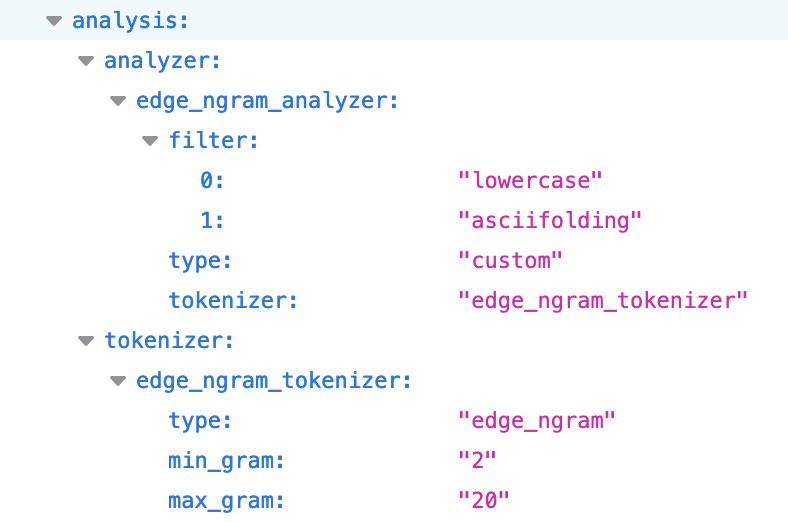
Change EdgeNgram and Ngram to use tokenizers instead of filters. Right now I'm just working around this using the AlterSettingsEvent but it should be changed on the EdgeNgram plugin. Instead of using a filter we should use an edge_ngram tokenizer. I've attached screenshots of my current settings.
N/A
N/A
N/A
N/A
| Comment | File | Size | Author |
|---|---|---|---|
| Screenshot 2023-03-10 at 3.12.27 pm.png | 62.16 KB | achap | |
| Screenshot 2023-03-10 at 3.12.16 pm.png | 64.22 KB | achap | |
| Screenshot 2023-03-10 at 3.00.02 pm.png | 29.68 KB | achap | |
| Screenshot 2023-03-10 at 2.58.34 pm.png | 28.29 KB | achap |
Start within a Git clone of the project using the version control instructions.
Or, if you do not have SSH keys set up on git.drupalcode.org:


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #2
kim.pepperSeems like a reasonable change. Are you able to submit a PR?
Comment #3
achapYeah I can do it when I get some free time.
Comment #4
kim.pepperCan you take a look at #3349179: Add a search_as_you_type data type to see if that is a better fit for your case?
Comment #5
achapThanks for putting that together. From what I'm seeing it actually has the same issue as the original edge n-gram implementation, i.e. it's highlighting the entire word rather than the n-grams themselves. Not sure why that is based on the docs https://opensearch.org/docs/latest/search-plugins/searching-data/highlight/
Comment #7
achapSwitching from filter to tokenizer is working for me with Edge N-gram filters. I guess the two plugins can co-exist?
Comment #8
kim.pepperYeah they can both exist.
I wonder if you can get the same results with
search_as_you_typeby just playing with the highlighter options? https://www.elastic.co/guide/en/elasticsearch/reference/current/highligh...Comment #9
achapI have previously played around with those settings on the edge n-gram field before using a custom tokenizer and it didn't appear to do anything but I haven't had a chance to try it out yet for search_as_you_type. I imagine it's caused by the same issue, i.e. that search_as_you_type is probably using the standard tokenizer which splits tokens up on word boundaries rather than individual characters.
This SO question appears to solve it in the same way for the search_as_you_type implementation (implementing an edge n-gram tokenizer) https://stackoverflow.com/questions/59677406/how-do-i-get-elasticsearch-to-highlight-a-partial-word-from-a-search-as-you-type
From the https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html#analysis-tokenizers it says that a tokenizer is among other things responsible for:
If I analyze a title field that is using the custom edge ngram tokenizer I get the following token information for the sentence "This is a title":
If I analyze a search_as_you_type field I get the following information:
So if the offset information is used for highlighting that explains why only the edge_ngram_tokenizer is working as expected.
Comment #10
kim.pepperOK. Makes sense. Now we just need to decide whether highlighting whole words or tokens should be the default.
Comment #11
achapSorry for not replying, got a bit side tracked :D I've been using this patch in production without issues for a while now. In terms of which one should be default I guess something to consider is index size and performance. Don't have any hard data to back this up but I guess tokenizing every character is a lot more expensive than every word. So maybe because of that and also preserving backwards compatibility it makes sense to keep filter as the default and add the tokenizer as a new plugin?
Comment #12
kim.pepperI'm inclined to push people towards the search_as_you_type approach rather than getting into specific tokenizers and analyzers etc. If people want to build their own custom solutions they can do that.
Comment #13
achapNo worries I will move this patch into our own codebase :)
Comment #14
kim.pepperOK cool. I'll close this for now then.