
 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.Problem/Motivation
Fields can store per language and revisioned values. Properties dont support that.
We want to address translation and revisioning together since D7 does not fully support those combined, even just for fields (see #12 for details). Another reason is that both involve the concept of Entity variant and addressing them together should allow us to find a unique and consistent solution. The system will need to support the ability to mark each property as translatable individually and the ability to switch a property's translatability.
As a side issue, we probably need a better term than translatable, possibly multilingual (see #1498850: Rename the 'translatable' field property).
Proposed resolution
A three tables per entity type approach
entity: entity id, revision id for revisioned entities, bundle, entity language (original submission language for the entity)entity_property_data:entity id, revision id, language, all entity properties (e.g. node: uid, created, status etc.)entity_property_revision:stores revision of revisable entities, same schema as {entity_property_data}
Untranslatable values copied for all languages.
Example schema for node
{node} PK: nid
| nid | vid | type | langcode |
{node_property_data} PK: nid, vid, langcode
| nid | vid | langcode | default_langcode | title | uid | status | created | changed | comment | promote | sticky
{node_property_revision} PK: nid, vid, langcode
| nid | vid | langcode | default_langcode | title | uid | status | created | changed | comment | promote | sticky
Remaining tasks
We still need to fully understand the pros and cons of this storage model.
- performance
- ability/ease of keeping data integrity/consistency
- permission in node/entity system
| Comment | File | Size | Author |
|---|---|---|---|
| #100 | NodeCopyVsProperty.png | 71.93 KB | gábor hojtsy |
| #58 | D8mi.png | 37.21 KB | andypost |
| #55 | entity sql storage.ods | 10.8 KB | plach |
| #12 | Drupal7EntityFieldPropertyTranslation.png | 86.21 KB | gábor hojtsy |
| #12 | Drupal8EntityPropertyTranslation.png | 81.42 KB | gábor hojtsy |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
dawehnerAdd a tag.
Comment #2
dawehnerComment #3
plachActually it might make sense to mark some properties as "locked" so their multlilingual status cannot be changed. In this case we would not need to add them in the translation schema.
Comment #4
plachCrosspost
Comment #5
plachbetter title
Comment #6
plachComment #7
gábor hojtsyLooking at #1498668: Refactor file entity properties to multilingual and #1498674: Refactor node properties to multilingual, I'm a bit concerned about how this interacts with revisions. The later issue says it should be discussed here. I think it sounds a bit scary, that for every entity + entity revision table, there would need to be an entity translation + entity revision translation schema too to support revisions for translations (which would be a must for core stuff that already supports revisions, so we cannot really forgo that).
Should we create a revisions based translation table right away and just join on the latest vid when looking up translations? Sounds like that could easily be slow. Do we know the status of plans to use document based caching of these entities, so that actual lookups like that would not happen that often in practice? Would that make the performance concerns moot?
As another option, are we scared of making the entity IDs a number + a language code instead of just a number? Is that a huge question to ask of all developers (that we'd rather introduce two more tables)? Would that mean we'd store non-translatable properties in multiple copies? That still sounds like it would be true for properties that are in the schema for translation in the original case but are not configured to be translatable, right? Because we have a record per entity vs. a record per property per entity.
Comment #8
fagoAre we going for revisions for translations or translations for revisions? I thought for the latter? I.e. a revision always applies to all languages but is not specific to a certain translation.
To recall, the way we discussed this in Denver was
With the above schema, we don't need to. When loading the *current* revision just the "entity" and "entity translation" tables are needed. We might want into lazy-loading translations later though.
We discussed that at the entity translation BoF and no one was fond of the idea. If we want to reduce memory-usage by not loading unnecessary translation I think the lazy-load approach is the way to go.
Comment #9
gábor hojtsyOk, well, my point was that we basically should now have 4 "base" tables per entity if the entity needs revisions support with this model, which looks a bit scary. For fields, that need revision and language support, we only need field_data_* and field_revision_* tables, because we store the multilingual info *inside* the data in the tables not in a separate overlay table. I think it would be great to get validation that the 4 table model is the best we can do and that retaining the simplicity of entity reference by its ID and the distinguished storage of the latest revision of properties this way trumps any language requirements.
Comment #10
yched commentedDo you guys really want to extend Field API's two-tables-per-field ? I'm personally not sure that was the best design decision made during the Field API code sprint, and I could totally see it going away.
Comment #11
gábor hojtsy@yched: no, this discussion is purely for entity property storage.
The main question was how to set the backend storage up for this. The solution we arrived at in Denver as explained by @fago above is that we add two new SQL tables for the translations (like the base entity table but has as many entries per entity as many translations there is). And then a translation revisions table, where the revisions are stored for translations. Because we want to have translation support for all entities in core, this would mean having double the number of tables we have currently per entity (if it is revisioned, we will have 4 tables, otherwise 2 instead of 2 and 1 respectively). Question is if this is the best we can do? We want to have property translation support, so we need to implement this in some way :)
Comment #12
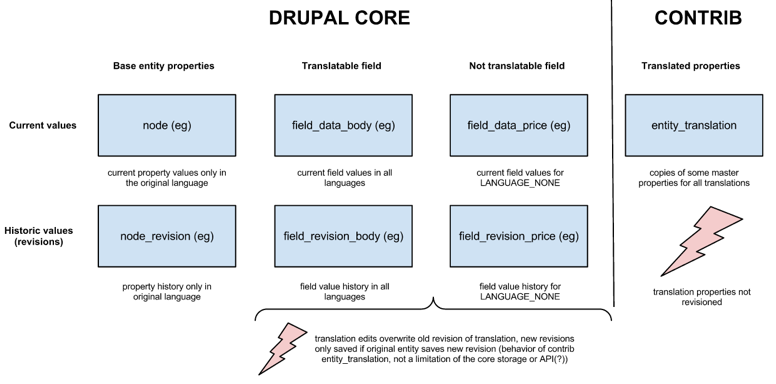
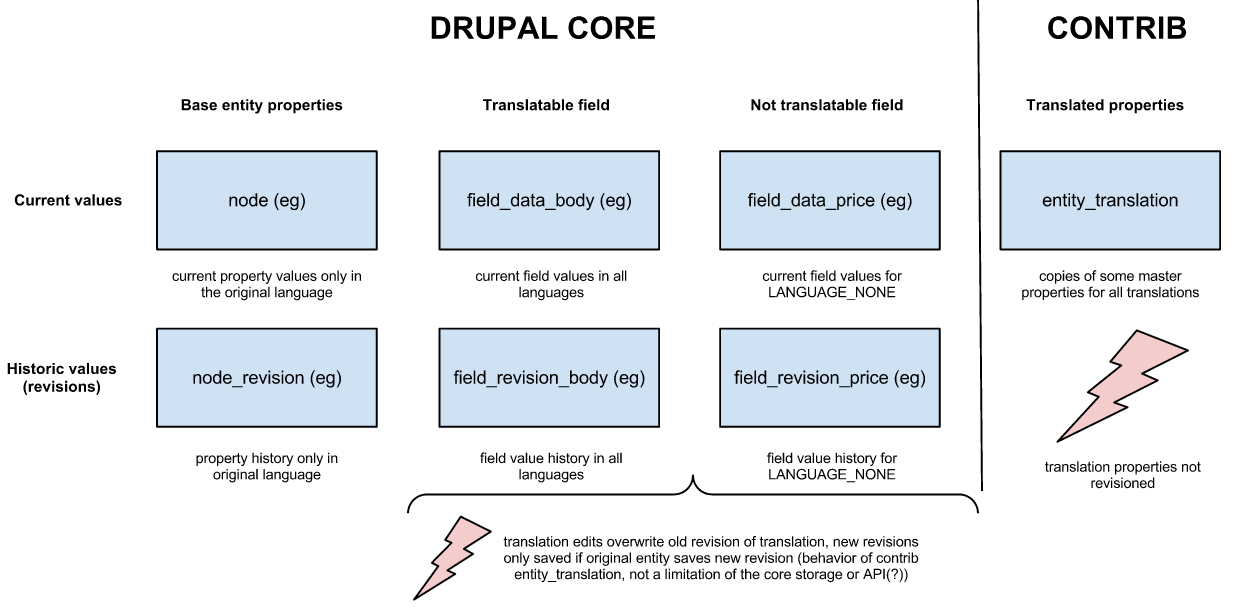
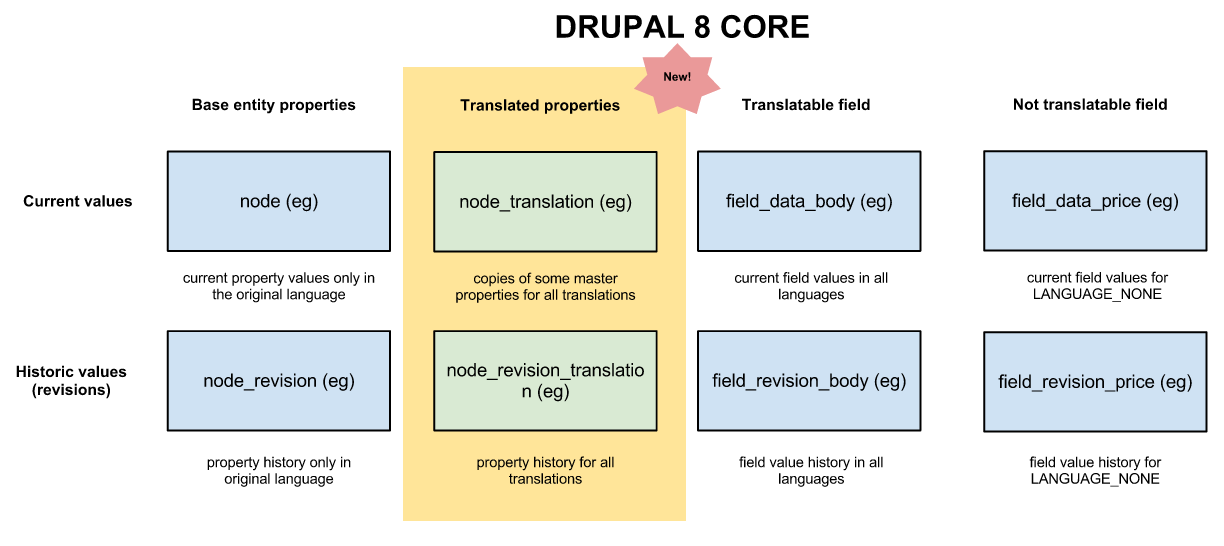
gábor hojtsyHere are some visualizations to help us get going. I've analyzed the D7 state, at least in my test setup, it looks like the following (click for larger version):
Core has built-in field translation, which entity_translation utilizes but it does not actually support translation revisioning (it overwrites the current revision when translations change). If the base entity is resaved for a new revision, that old revision of the translation is kept of course, but entity_translation module does not save new revisions. It also has a table to store property value overrides for common entity properties (author, created, changed, published, etc), but does not revision those at all either. So the current translation solution foregoes revisions altogether for properties and does not really work with them for field values either.
We want to have property translation support with revisions, so we need to replicate the "current value in a different language" data and the "historic values in different languages" data, if we consider the based entity table (such as node) would always store the original entity values only, we'd introduce two more tables as per the above discussion (we introduce these per entity type since all properties are stored in one record):
(We should also of course fix the field translation issue with revisions, that is not the topic of this issue, just an observation).
Any concerns with this model or we should just go ahead and implement it? :) (evil grin)
Comment #13
effulgentsia commentedFWIW, I'm okay with the 4 tables per entity type default (for entity types that have properties that are both translatable and revisable). I'm assuming several things (please correct me if I'm wrong):
So, we're not so much saying that entity types must have 4 tables, but rather that Entity API must include support for translations, revisions, and translations of revisions, and must include pluggable storage, and that we think the most performant default storage implementation for relational databases is to partition independently on both revisions and translations. I think that's a reasonable assumption to move forward with (unless someone has evidence to the contrary), and if we learn that it's wrong, then either core or contrib can provide an alternate storage implementation.
My gut tells me that 4 should be our limit though. If some new variant gets invented, then we should probably implement some generic variant solution rather than expand to 8 tables. But at this time, translations and revisions seem different enough, and I'm not aware of a 3rd variant for us to worry about.
Comment #14
effulgentsia commentedWell, for file entities, there's lots of other potential variants, like format, bitrate, size. But I don't think D8 is the version for core to worry about that. It's a problem space still being explored in contrib.
Comment #15
gábor hojtsy@effulgentsia: Yeah, I don't think we wanted to dynamically create the tables/columns. We wanted to dynamically query them for sure. The family of issues were opened I think with the intention to have the schemas static but the queries dynamic. See remaining tasks above. Hm. We definitely need to think about this.
Comment #16
fenda commentedComing into this pretty late but will node titles be translatable through this solution?
Comment #17
gábor hojtsy@drupaljoe: yes, that is the plan.
Comment #18
plachWell, an example of cross-entity-type variant is domain: I recall @agentrickard arguing that we should not special case language for configuration. That argument applies to content as well. I think there would be solid use cases to justifiy the design of a generic Variant API, anyway I agree this is not exactly a D8 thing. However if we design this system well enough, it might not be that hard to implement a D8 Variant API, provided that we have time do it.
Actually this is phase 2: #1498720: [meta] Make the entity storage system handle changes in the entity and field schema definitions :)
See the complete masterplan for details: #1188388: Entity translation UI in core.
Comment #19
gábor hojtsy@plach: question is if there is point to introduce the manual schemas if we want to go the automated schemas, hm? Introducing and debating all those manual schemas (and having them around even if you don't have translation as per the patch at #1498668: Refactor file entity properties to multilingual) would be hard enough to get in, I have doubts we'd have time to introduce automated schemas and back out the manual ones. Hm. Unless there is strong interest for a variant API with people backing to work on it, I see little chance we can get that done. We made almost no progress on content translation changes so far, and D8 freezes are not far off :/
Comment #20
plachI'd be ok with working directly on automated schemas, @fago had some concerns about this solution. Maybe he can expand on this.
Comment #21
agentrickard@plach
While I'd be much happier, I think, with {node_translation} and {node_revision_translation} being {node_context} and {node_revision_context}, where language is the default context, I don't see anyone rushing to implement that code in the other issues. I would think we can make this work for translations and then look at abstracting for more use cases.
Comment #22
sunI tried, but can't think of a diplomatic follow-up, so I can only put it this way:
Other contexts or variations are way too use-case specific to even consider for Drupal core. Not only data storage but also their negotiation would be entirely unclear at this point. Language or translations, however, are absolutely essential for Drupal's goal towards world domination. If we are not able to deliver a system that is capable of presenting the appropriate information in the right language for the current visitor/user, then we fundamentally fail at presenting information.
I won't argue against the perspective that language is just one more vector/variation in terms of dynamic contexts. But I do argue against the perspective that "we shouldn't special-case language", because it is my belief that we're only able to properly abstract this dynamic context negotiation and data handling, once after we have fully introduced a first one successfully. There are lots of challenges involved in merely resolving that single context, and history shows that even those alone are too complex to be solved.
Language is a first-class requirement for plenty of web sites world-wide. I don't want to see progress on solution attempts deferred or delayed, just because there might be more contexts we could cater for, searching for the yet unknown but Ultimate Perfect Solution™. Instead, the multilingual efforts that started with Drupal 7 should be seen as corner-stones for better context negotiation/handling. By continuing these efforts with the outlined plans, we may be special-casing language as a context at first sight — but in reality, we're exploring our way towards a system that is capable of handling contexts for data at all. And it's not like we're not struggling hard with that limited goal since years already.
We are in a step-by-step process, from a very high-level perspective. By introducing field language as first-class context for fields in D7, we've learned a lot of lessons - good things that worked as well as huge mistakes. Due to that, we're now able to advance on that knowledge and gained experience. Which can easily be projected/translated to other contexts. But we didn't make any progress on entity-level and other language/context facilities yet. Thus, we can discuss abstract solutions for the next couple of years. Or we can start to complete the first first-class context by also introducing an entity-level language context for all entities in core now. And learn from that tomorrow.
In this spirit:
{[entity-type]_translation}proposal makes sense to me.Or is the proposal to leverage #1346214: [meta] Unified Entity Field API and to actually load all values in all languages into a property, so that it can be loaded + saved without huge disasters, similar to field values?
Lastly, given the other directions and efforts currently happening for D8+, I no longer consider $entity->label as an entity property though. It's nice and good to retain that property as the #1 example, but I do predict a future in which
SELECT * FROM {node} WHERE title LIKE 'abc%'is no longer possible, since entity labels will (very potentially) be stored in fields.Comment #23
plach@sun:
I pretty much agree with this statement, that's why I said I don't see this happening in D8, unless we have completed all the already planned work (which is very unlikely TBH). However I feel that having a generic system in mind, although not actually implemented, and the awareness that we are dealing with a special case might help us in finding the proper design solutions in some cases. That's all.
IIRC we agreed that multiple properties will have their own tables just as fields do now.
I think that when we referred to dynamic schema creation, we were mainly talking about automatically generate the
_translationtables. Not sure about inspecting the original schema and pick only the translatable properties, since a switch in translatability would imply a schema change, and I ain't sure we want to support it. The downside of this approach is we would store replicated data for non-translatable properties.I definitely think this is the plan.
I think that the Entity Storage API will make this irrelevant as we won't directly query the DB anymore. Labels then could be anything from fields or properties to computed values.
[OT] IMHO we should really make node titles fields as not being able to use markup inside them is a pretty bad limitation.
Given that no one here seems to disagree with the proposed plan what about the point raised by Gabor in #19? Should we directly work on automatically creating translation schemas or should we manually introduce those tables first? Personally I feel that introducing one table as an experiment to nail down tricky aspects might be a good starting point, then we could make a leap ahead and work on the dynamic thing.
Comment #24
gábor hojtsy@plach: all right, I think it makes sense to start with at least one static schema then and experiment with the rest of code with that too. I think the node schema would be a trivial choice for that since we need to work out not only how it works but a migration schema as well from node translation.
Comment #25
agentrickard@sun
I totally agree with this statement and apologize if comment 21 did not make that clear:
IMO, we should make language work in d8, and then abstract it for d9, due to feature scope, timelines and resources. I was responding to @plach's request for comment based on another issue that reached the same consensus.
No blockers here.
Comment #26
fagoI fully agree that entity vector/variation is out of scope for D8. Still, with pluggable entity storage controllers it should be possible to experiment with that in contrib.
Yeah, the plan is to load/save all languages at once - just as we do now for fields. Dynamically overloading entity-data might have some unexpected consequences for developers, so I'd prefer to keep any context/state out of entity objects. Still, something like an entity render system can apply reasonable language defaults.
Yep. Don't forget we have the abstraction of storage controllers in place. So if needed/desired one can still implement further tables for storing multiple valued properties in the controller. I don't think we should add or need support for that in the DatabaseStorageController provided by core though.
Yep, I also think we should start with a complete static scheme, including translations. We need to get that and the querying part right first anyway.
Still, once we've that you could add support for a more flexible property scheme with custom storage controllers. Imo, it's most important to reach the state of entity controllers being really pluggable and the system relying on the entity property metadata, such that existing code does not break when you decide to use another controller.
Once we've that + a sane default implementation, we can think about implementing even more sophisticated stuff in core or just leave the experiments to contrib.
Comment #27
sunPromoting to RTBC queue as there is a consensus here.
Comment #28
gábor hojtsySo sounds like we want to fix #1498674: Refactor node properties to multilingual as soon as possible with a static schema. Then move on with introducing actual API and UI for property / entity translation (where missing). Then (and in parallel) get to #1498720: [meta] Make the entity storage system handle changes in the entity and field schema definitions to introduce automated schema creation for the rest and then for nodes as well, right? :)
Comment #29
effulgentsia commented#28 sounds correct to me. I think that means we should promote #1498674: Refactor node properties to multilingual to major, and postpone or "won't fix" #1498662: Refactor comment entity properties to multilingual, #1498660: Refactor taxonomy entity properties to multilingual, #1498664: Refactor user entity properties to multilingual, and #1498668: Refactor file entity properties to multilingual. I considered doing that myself, but wanting to double-check here if I understood correctly.
Comment #30
effulgentsia commentedAlso, just so we have it written down for future reference, could someone summarize why _translation tables per entity type are preferable to _translation tables per property? I'm assuming performance, but 1) is that the only reason?, and 2) what are some example queries that we believe are performance-critical, and where we can show a significant difference between per-entity-type vs. per-property? (we don't necessarily need to run benchmarks now, just want to know in case someone wants to run benchmarks at some point)
Comment #31
gábor hojtsy@effulgentsia: I think the properties are properties at the first place for performance reasons, not much else. Fields provide a lot more flexibility and features otherwise. As for why translations of properties would use the same one-record storage with columns for properties, that would be to avoid the multijoin scenario that fields entail (which is the main reason that the original properties avoid that too). Such as when you need to limit permissions to a node listing by published / author data, which feels like a very common use case. Making that interact with translations and the permissions system is going to be a challenge to work on to say the least.
I've marked #1498674: Refactor node properties to multilingual major and moved onto the sprint. Did not yet mark the others won't fix, waiting some more agreement from the rest of the team :)
Comment #32
effulgentsia commentedThanks for the use-case. Ok, suppose you want to get a node listing filtered to nodes whose German version is published. Are we expecting a query that returns nids only (as with EntityFieldQuery), and then we do a entity_load() on them to display the list/table? If so, then joining on {node_translation} is no faster than joining on {property_status}. Or, are we expecting a query that returns $partial_node objects that contain all properties (but not fields), so that a list/table can be displayed with no entity_load() needed. In that case, querying {node_translation} saves on a join only if that table contains all {node} columns, which is different than #8's proposal of translation tables containing translatable properties only. If we stick with #8, then I think the only queries where per-entity-type storage involves less joins than per-property storage are ones where we want to filter/sort on multiple translatable properties at once. So, am I correct that:
[EDIT: Actually, one benefit to per-entity-type translation tables is even if you only filter on one translatable property, if you then want to display a HTML table of $partial_node objects (such as an admin listing), containing columns for multiple translatable properties (such as a column for status and a column for author). And that does seem like a very common use-case.]
Comment #33
gábor hojtsyIf we want to have only translatable properties stored and we want to make what translatable configurable, #1498674: Refactor node properties to multilingual might not fit that goal, since it is about a static schema with a superset of all translatable properties. If a property is not translatable, we'd store some empty value in its place or value equal to the original language, or something along those lines with that approach.
Comment #34
effulgentsia commentedThat's okay. It's a transitional step that will eventually be replaced with #1498720: [meta] Make the entity storage system handle changes in the entity and field schema definitions, and as a transitional step, it's still useful to unblock progress on the query/API/UI work, even if it has columns for properties configured as nontranslatable, and that we therefore don't query.
If our plan is to fetch non-translatable properties from {node} and {node_revision} only, and never from {node_translation} and {node_revision_translation}, then I suggest setting the latter values to NULL rather than duplicating what's in the base tables. I'm just pointing out that in this model, we always require at least 1 join when needing $partial_node to contain both nontranslatable and non-default-language property values, and am looking for confirmation that we're okay with that, as opposed to duplicating all nontranslatable property values in the _translation tables as a way to remove that join requirement.
Comment #35
sunClosely related: #1537214: Clean up node revision log message handling or convert it to a field
Comment #36
gábor hojtsyIn that case, for properties newly turned translatable, we need to backfill the property history for translation (if we want to pretend it was always translatable), or just make the system aware that some properties were NULL before they were made translatable.
Comment #37
gábor hojtsyLet"s figure out that node translation schema then: #1498674: Refactor node properties to multilingual posted patch.
Comment #38
sunI happened to discuss this proposal with my local user group last week. A possible pitfall:
This schema does not resolve the "original/source language" problem space.
It is solved for fields, because there is no "primary" record for fields. The records for a field are attached to the primary entity. This means you can change the language the entity is edited and/or presented in, and you'll always get the proper values (if there are any).
This proposal does not normalize all language-specific values into a separate storage. It only normalizes the translated values.
In turn, what happens in the (unlikely) case when you create a node in French and (for whatever strange reason) you go edit that French node and decide to replace all values with Spanish values instead? Consider that a Spanish translation may or may not exist already.
Now, the language-specific values for revisions will look and work identically with this proposal. So, What happens in the revision records (and the revision translation records!), if someone decides to change the primary language of an entity?
By not normalizing translatable properties and retaining them in the primary entity + revision tables, there's a not so small chance that we're going to run into extremely special conditions that will require a serious amount of complexity in the CRUD operations, but also in the API design and documentation.
We might be able to cope with those special conditions by treating the translatable property values in the primary entity table always as copies of the "actual" values in the entity translation table (i.e.: we'd always store values in the
{[entity]_translation}table, even if there is only one language), but even with that extension there are probably still ways to hi-jack the design.Comment #39
gábor hojtsyI think most of us would be happy to just store properties as fields too, we thought making that the default would be impossible to get into core, as the primary motivation for properties in the first place is speed. Is it far fetcehed to change all property storage to be field oike once you add one more language to your site? That sounds like fair bit of complication too. I think we just need to pick are poison, there is no holy grail here.
Comment #40
gábor hojtsy@sun: the apparent alternative is that we can make all languages be on the same level and promote langcode to be a primary key on the node table. That is store all translations in the same table too. Just like for fields. This would be a HUGE change given that all modules would then need to understand that a node number is not sufficient to identify a node anymore. Or at least it would lead to different language versions based on context. (That might be the same result with the current solution either though). Hm.
Comment #41
catchCross-linking #1497374: Switch from Field-based storage to Entity-based storage. I think Damien's idea (I didn't watch the Denver presentation, but based on previous discussions) was to store data fully normalized (or alternatively serialized in a document structure - XML in the db or something), but then have automated denormalization for queries on that data.
Something like that would allow for fully normalizing translatable properties without the immediate performance hit, but not sure how far along any of this work is.
Storing the stuff in the translation table even if there's only one language installed doesn't seem that bad to me? Don't we already do that for revisions in field storage?
Either way I agree this needs more discussion.
Comment #42
sunAlways storing the language-specific values in
{[entity]_translation}(or perhaps rather{[entity]_language}then?), and essentially always treating the values in{[entity]}as copies sounds fine to me as well.That may or may not introduce a pattern for normalized + denormalized data storage.
That said, I'm actually not sure what kind of benefit or use-case the denormalized values would fulfill in the end -- since you can't really rely on copies, and doing so would mean that we'd have conditional db query code that queries the denormalized values on monolingual sites and the normalized values on multilingual sites... sounds like lots of magic/complexity.
Comment #43
fagoSo the default language changes? Spanish won't be a translation any more, but French. So Spanish values would move into the main table, while French values move to the translation table. I'm not sure how that poses a problem?
The entity language needs to be revisioned too, then all should be just fine.
To me, normalizing would work too. However, the idea was to don't put the burden of additional joins on single-language sites - so we can completely skip the translation table then and save some joins/queries.
In a way this proposal is in line with what we do with revisions, it just adds another dimension (=translation) which exactly works like the first one (=revisions): by default, query/load the default values, upon request query/load the values specifc to the dimension (= a certain language or revision).
Still, the "translation dimension" load-case would be a bit different as it's activated "globally" not per-load. What brings me to a related idea: What about handling it exactly the same? Let's think this through - feel free to ignore if it turns out to suck:
entity_load('node', 1)always gives you the current revision in default language. To request a different translation you'd have to doentity_load('node', 1, 'es')and for a revision of the entity in default languageentity_load('node', $nid, NULL, $vid);Then, we could keep the current getters/setters but additionally add easy accessors to entity translations and do the same for revisions:
$german_translation = $entity->getTranslation('de');So, as for revisions the $german_translation would be a full entity which so could be loaded/cached/saved/updated on its own, which actually should be a good idea for memory usage anyway.
I don't think the API design would be so complex, as language and revision would be always optional parameters. I'd see the query-ing logic which has to switch tables as needed as most complex, however with revision and languages working the same way we can apply the solution to both. That way we'd fix querying certain revisions while we solve it for translations.
Also, we'd have to solve problems like what if
$node_revision->save()or$node_translation->save()updates not revisionable or translatable properties? How can modules easily detect the change of the property although just a revision or translation got updated?I guess the best option would be to disallow that and really only save translatable/revisionable properties.
Comment #44
effulgentsia commentedIs that true? Like #43, I've been assuming that the _translation tables would contain records for the default language too, just like the _revision tables contain records for the active revision. Though also like fago, I'm more concerned that we get our API right, so that we can tinker with storage implementation details later if we want without it affecting any code that uses the API. In regards to API, I like #43. Just for clarity, I assume that
entity_load('node', 1, 'es')would work even if 'es' is the entity's default language, and that$german_translation = $entity->getTranslation('de');would work even if 'de' is the entity's default language.That's an interesting question: if what we mean by "translation" is "an entity in an explicitly requested language" rather than "an entity in an explicitly requested language that is different from its default language", then is "translation" the correct term for that? It seems to be the term used by Doctrine PHPCR ODM mentioned at the end of Damien's and Lukas's Denver talk, and based on that talk, I wonder how closely we can/should be consistent with that.
This is an example where I think being consistent with the PHPCR ODM could be very helpful. I just found that link, so I'm not yet clear on how that answers this question in detail.
While there's still a bunch we need to figure out on this and soon, what do you guys think remains a blocker before we can re-open #1498674: Refactor node properties to multilingual as an initial step?
Comment #45
sunForget entity_load(). That's no use-case.
More to the point would be
entity_load_multiple('node', array(), array('uid' => $me->uid));, but not even that fully cuts it.Actual problems arise when you
db_select('node')->condition('title', db_like($input) . '%')->execute();, and this happens, often.If the answer to that is "EntityFieldQuery", then there is not point in duplicating the values into denormalized tables in the first place, because we stop to directly query entities on translatable properties anyway. We're querying entity IDs instead, based on a dynamically built query, and load the full entities afterwards.
Comment #46
gábor hojtsy@sun: yes, we discussed this in your presence in Denver. We need people to forget using db functions for entities altogether, and they should use our abstraction layers so they get the right data regardless of where it is stored. Storage could change when you turn on more languages or when you translate a node, or however we see fit to implement storage best. And your code should not be bothered with that.
Comment #47
gábor hojtsyAnybody cares about moving forward here?
Comment #48
gábor hojtsyI'm growing increasingly aware that there will be no entity translation UI in core for Drupal 8 since it seems pretty hard to imagine when we'd have the opportunity to even get there. I hope we can at least agree on an API level and make the implementation it in before the code freeze, can we?
We seem like to have a number one requirement to keep the entity data storage as simple as now, BUT we don't have a requirement at all to keep making it able to be queried directly anymore as such. So I'm not sure why we are so tied to keeping the current data storage as-is if we will require people to use an abstraction API (like EFQ) to query entities anyway. As long as the data model for entity (property) storage is pluggable, the storage model can use one SQL table or a table per each property (like fields) or something else like a document XML format. Whatever. So we are relatively to pick storage models for multilingual content.
I think what we are concerned about is the migration between the single-language storage vs. multilingual storage. If the storage model is very different, your site needs to go offline when you add a second language to convert all storage proper. Or if we just replicate the single language data in the multilingual storage, the concern was we do duplicate storage, that has performance/integrity implications too.
I think we demonstrated we need to pick which drawbacks we accept. Or we can just be in indecision limbo if that is better.
Comment #49
plachI have a couple of ideas about this :)
We certainly need an agreement on this before moving on with rest. I'd say this is our #1 priority.
I was thinking along these lines too, however if we stick as close as possible to what we have now the amount of actual work to be performed should be minimal: can we agree on this?
In D7 the field API team decided to avoid dynamic schema alterations (at least in core) to avoid the complex data manipulation logic it involved in CCK. Hence, if history matters, we have a clear signal that we should prefer replicating untranslatable data over making the translation schema dynamic.
However I'm wondering if the two scenarios are actually assimilable: if we use the main data/revision tables to store original and untranslatable data, making a property translatable is just matter of adding a column with default value NULL to the translation data/revision tables. Reverting translatability is just matter of dropping that column, so in both cases no data migration is necessary. Obviously in the latter scenario we would lose all the translation values, but this is what currently happens in ET and none is complaining about it. Not sure if such operations would require to put the site in maintenance mode but, even if this was the case, switching translatability should not be such a common operation on a live site.
Does this make any sense? Am I missing something obvious?
@Gábor Hojtsy++
Comment #50
gábor hojtsyI think the concern was that data copy-over would be required when you make something translatable. The original value would be copied over to the translation table too, so it would be on the same level. Then if the entity is updated, it would need to be updated at both places.
Comment #51
plachYes, this is a possibility. If I'm not mistaken having the original languages in the translation table has been proposed mainly to ease the ability to change the source language. Does this bring us more advantages than not having to deal with duplicate data?
Which is what already happens, e.g. for the last revision's title, hence if we go this way we are not actually introducing a new real issue about integrity. Surely perfomance might be a concern, at least in theory.
I think we have not really agreed on a full proposal, there are a bunch of slightly different variations on a main theme. I'll try to sum them up along with their pros/cons later today.
Comment #52
gábor hojtsyYes, currently, it would change the node and node_revision table records (2 tables). If we have translation table counterparts for both, changing the title of the node in the node's original language would result in updating 4 table records at once with the same value.
Comment #53
effulgentsia commentedThanks. I look forward to that. I thought of these use-case questions that might be good to have answered as part of that summary.
Suppose I have an array of user ids ($uids), and I want either of the following results:
For each variation of storage proposals, for each of the above two requests, what would the query be for both:
Also, for each variation of storage proposals, what query would need to be run when:
In all cases, the entity api should shield application code from needing to write these queries directly, but I think knowing what these queries would look like, even if only run from the storage class, will help clarify the pros/cons of each storage approach.
Comment #54
plachThis will take a bit longer than what I initially thought. Hopefully tomorrow :)
Comment #54.0
plachAdd a summary and link to the other issues
Comment #55
plachI updated the OP with a summmary of the discussion held so far. Did not put any consideration on pros/cons yet since I'd like people to review the attached spreadsheet. It holds the query variations asked by @effulgentsia in #53 and looks very clarifying to my eyes. Here is a legend to help understand it:
S4RCO = 4 tables Storage, helper tables Replicated, untranslatable values Copied, Original values copied in the helper tables
S4RCT = 4 tables Storage, helper tables Replicated, untranslatable values Copied, only Translations in the helper tables
S4RNO = 4 tables Storage, helper tables Replicated, untranslatable values Null, Original values copied in the helper tables
S4RNT = 4 tables Storage, helper tables Replicated, untranslatable values Null, only Translations in the helper tables
S4VO = 4 tables Storage, only Variable values in the helper tables, Original values copied in the helper tables
S4VT = 4 tables Storage, only Variable values in the helper tables, only Translations in the helper tables
S2LCO = 2 tables Storage, Language as primary key, untranslatable values Copied, Original values copied in the helper table
F50DD = First 50 records, Default content, Default language title
F50EE = First 50 records, English content, English language title
LTUT = Label Translatable, Uid Translatable
LTUN = Label Translatable, Uid Non-translatable
UNT = Uid changed from Non-translatable to Translatable
UTN = Uid changed from Translatable to Non-translatable
Unless I got something wrong, which is certainly possible, it seems that the most effective choices, wrt the metrics mentioned in the OP, are S4RC0 and S2LCO. Keep in mind that I tried to wrote the smartest query I could think of, but in the S4* scenarios it might become very complex to dynamically find out which is the best query depending on the variability of the properties involved. Moreover the simple queries where no join is involved are unlikely to happen in a multilingual scenario, where asking for the default language, no matter which it is, makes little sense. This sample seems to indicate that most of the time we would find ourselves querying the helper tables, possibily joining on the base one.
After this analysis I definitely think we should move forward with the 2 tables schema originally proposed by Gabor. The only thing I'm really annoyed about is that in this model there is a strong asymmetry between the two variants. I am wondering whether it might make sense to go even further and, as @yched hints in #10, go for a 1 table approach where variants would be simply additional columns (possibly dynamically added/removed): I guess the node table is currently used as an optimized storage to avoid querying a high cardinality table in most situations, but the 1 table approach would save a join in many simple queries. However I'm wondering if this would be a worth trade-off given that we would have entity cache in place, possibly backed by document storage.
Comment #55.0
plachUpdated issue summary at comment #54.
Comment #55.1
plachUpdated issue summary.
Comment #56
gábor hojtsyMoved #1498674: Refactor node properties to multilingual off sprint since we have no agreement here, let alone discussion :/
Comment #57
plachIf no one here has anything to object I'll simply go along with your plan, as soon as I have time to work on it.
Comment #58
andypostWe wanna have a universal solution which is not possible to satisfy all cases (SLS, MLS). Also MLS has a lot of different needs. But the most of sites are SLS. So language should be a primary identifier as stated in #1266318: Make English a first class language But we can't mark every piece of data with langcode for now.
I strongly agree that for "universal solution" we should change storage for entities to denormalized tables (a-la cck-6 by adding for each translatable property it's own column) or use Field-like schema with langcode in PK. Both of them has it's own ++&-- but applicable for all cases. this leads to more EFQ and Views based queries in core. Is it bad?
I see a few of simple tasks: configure/define data schema, show form, store data, search data; translate data, store translated data is subtasks of show form and store data.
What we need to store: config, entities, fields and properties (probably for config too), UI strings with translation, states for config and content.
Language is a attribute by it's nature for any kind of data. Historically we always make a JOIN to get translation. This assumption stops #1452188: New UI for string translation - when language is not defined core have to search in both tables. So our string translation still has English as source (for what? performance reasons? #1266318: Make English a first class language) In this case I think all strings are same and should be just linked(bundled via some hash or uuid) - any language could be the source.
This model we tried with CMI #1448330: [META] Discuss internationalization of configuration without success in #1552396: Convert vocabularies into configuration and #1588422: Convert contact categories to configuration system
Currently only fields works well because they have langcode in Primary Key so this is a way.
Adding another abstraction layer around entities is good from architectural point of view but increases a complexity and finally adoption of Drupal. A great idea of #1499596: Introduce a basic entity form controller does not get enough of attention - how much devs has a good knowledge of EntityAPI to help with?
Render is partially affected by language but should.
Currently we have 3 language-aware modules in core and a new a bit lighter but the same spaghetti code (module_exists()) all over language-aware functionality. And all of them does not solve a simple task of content translation.
We wanna to translate node titles - let's wait to make title a field again.
Taxonomy stacked in vocabulary conversion and inconsistency, standard profile Tags for articles are not translatable and from D7 has no synonyms.
Users now have 2 language fields but this more confusing then usable.
Files (semi-entities) still has a lot of issues with uploading ... and we wanna make mirror(translation) tables for them too?
PS: Sorry for emotional post.
Comment #59
plach@andypost:
I appreciate your passion, but you are touching many different issues: honestly I ain't sure I get your position about the specific discussion here. Are you saying that the translation schema replication is too complex and that we should follow the Field API example, setting the langcode column as part of the primary key?
Comment #60
andypost@plach Yes, I do, exactly.
I touching most subsystems specially to show overall inconsistency in translation. Also we use a lot of wording and issues that was tried to systemize usage of localization, translation, i18n are failed. So I suggest to leave only a few storage for multilingual data.
As all entities already has langcode so we just need a meta-data storage to indicate properties affected by translation. Suppose this should be part of entityAPI. Then we should decide on Render and Froms.
Also we have backdoor as i18n does for now.
Comment #61
dries commentedI've been reading this issue and it sounds like this is a blocker for the entity work (and for the D8MI initiative).
I think we want to make a decision before the code sprint in Barcelona. Per http://buytaert.net/streamlining-drupal-core-decision-making, I'd like to delegate that decision to Gabor and I'm asking him to make a decision before the code sprint.
I have not discussed this with Gabor, so if Gabor thinks he is not the best person to make this decision, he can bounce it back to me and I'll delegate the decision to someone else.
Comment #62
gábor hojtsyFor reference, here is the ODS converted to HTML that plach posted to look at queries for each storage method mentioned:
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Comment #63
plachLegend in #55
Comment #64
gábor hojtsyI've been thinking about this *a lot* this week.
First of all, we need to change how we think about entities either way. By making entity properties translatable, it is not anymore possible to just assume you do a simple query to the node/taxonomy/etc. table and get your value. It does not work that way whatever we pick for implementation path. So you'll need to take language into account some way.
The elegance of fields is that you just load stuff which loads all languages and later you display stuff which picks the right language version and you don't need to care for language that much. Granted, entity properties are more often queried (eg. posts from this author, only published nodes, etc), but regardless of how we make them translatable, the queries would need to change.
While I don't think my statement will be definitely the final implementation, looks like almost all arrow point to S2LCO as the most consistent implementation with our current entity/fields/config approach.
1. Language is already part of the primary key on field storage. The primary key is (`entity_type`,`entity_id`,`deleted`,`delta`,`langcode`).
2. Different language values are stored on the same level for fields.
3. All language values are loaded for fields when the entity is loaded.
To be consistent with at least (3), we'd need to consult the translations at all times when loading an entity, so that the display can pick the right values. Same goes for saving an entity. We don't have states for entities like 'the English version of this entity', we just have the entity as a whole, so all language variants of properties would need to be there too.
In terms of loading values directly, this is simpler then any other proposed solution because you could still do SELECT * FROM node WHERE nid = $nid, you just get multiple records for the different languages, like for fields. Its still just one node, with language variants. In terms of filtering values, you'd only need to consult the base entity table again (and add conditions filtering for original variants and translations as needed). For relating things to the entity, you could still relate to the main entity_id (and write custom join queries like that) which would mean the relation is not language dependent (or it cannot have language variants). For the built-in relations like author, we'd have language variants naturally. (We already have language variance for field based relations like taxonomy terms by virtue of them being fields :).
A noticeable downside is that we'd need to store duplicates of the base information for non-translated (non-translatable) values, but that is the same even if we duplicate the entity base table and revisions table and could only be avoided if we do dynamic schemas for property translation storage or move property storage to a field storage like separate table system. Both sound like could kill the performance advantages of properties being properties, which is the base reason they are not fields at the first place.
Solid?
Comment #65
gábor hojtsyTwo more side notes:
A. The affect of this change on developers is that they'll need to treat properties as multi-variant, just like they do for fields. That is really not something we can avoid, its the whole point of this issue to make that happen :)
B. The affect of this change on single language sites will be a tiny bit longer key on entity tables (and foreign keys on entity revisions tables).
Comment #66
plachI totally agree with #64 . The more I think about it and the more I like that way it naturally merges our different D7 translation approaches (entity translation vs translation sets).
This would pair well with the API usages depicted by @fago in #43, which probably need more discussion in a separate issue, though.
However I'd like to clarify the alternative I proposed in #55, which could very well be a follow-up work after we implemented S2LCO. I'm again sarting from the idea that language and revision are two variants that could be treated the same way: if we dropped entirely the
entity_revisiontable and stored all the values in a singleentitytable, we could save many joins at the price of having to query a table with a (potentially) higher cardinality. I did not check but I suspect we are joining on thenode_revisiontable most of the time anyway, so this might not be a real perfomance issue. This totally needs verification as it could easily reveal as a grand BS, however maybe entity cache would alleviate many problems here.This approach would buy us the ability to add/drop the language or revision columns as needed by the site being implemented (possibly paving the way for a future variant API):
Dumb site (no language, no revisions):
Dumb ML site (translated, no revisions):
Advanced site (no language, revisioned):
Advanced ML site (translated, revisioned):
Comment #67
effulgentsia commentedFWIW, I'm ok with #64. We still have plans for implementing a property API, pluggable storage, and an improved EFQ for D8, but regardless of that, I think #64 is acceptable and worth proceeding with.
Question: How do we identify the entity's original/source/default/native language (and which of those 4 adjectives best describes the meaning)? A langcode_original/langcode_source/langcode_default/langcode_native column? Is the value of this column always a non-empty langcode and the same one for all records of a given eid (in the same way that {node}.type must be non-empty and the same for all records of a given nid)? I ask cause #62.S2LCO is querying source_langcode='', which doesn't seem quite right to me.
Comment #68
effulgentsia commentedFound this comment from catch from August:
I don't know if I understand the full concern being expressed here, but one thing fago, Crell, dixon_, DamZ, and I just discussed earlier this week at the Paris WSCCI sprint is the need for PropertyAPI to include a standardized ReferenceProperty class, and for all entity references (both core things like {node}.uid as well as contrib modules like flag, nodequeue, etc.) to use this (or an alternate class that implements ReferencePropertyInterface). This is actually quite important for serializing to JSON-LD (or whatever other format contrib REST service implementations want to add) and managing content staging/deployment. I think this ReferenceProperty class will be able to take care of the necessary querying, so that the flag, nodequeue, etc. modules don't need to worry about joining on {node} themselves (and therefore, needing to deal with the complexities of a nid,langcode compound key). @catch: does that sufficiently mitigate this concern?
Also, I added a comment on that August thread inviting others there to comment here.
Comment #69
effulgentsia commentedThe idea might be worth discussing/pursuing, but I agree with deferring it to a separate issue, one that simultaneously asks this question for both entity and field tables.
Comment #70
effulgentsia commentedIt occurs to me that I don't know if we'll have problems with {node}.nid being both autoincrement and part of a composite key. If that's not a problem, great. If it is, perhaps another approach is to have {node} only contain nid, vid, type, and langcode (where this langcode is the node's original/default/source langcode). And have a {node_property_data} or {property_data_node} table (along with {node_property_revision} or {property_revision_node}) contain all the other columns. This is similar to the various 4 table approaches from #62, except that the property table is the definitive/only source of all properties (just as the current field_data_* and field_revision_* tables are for fields) and the entity table is for very limited use (autoincrementing nid, knowing a node's original langcode, and queries like
SELECT nid FROM {node} WHERE type='article'orSELECT vid FROM {node} WHERE nid=5). As with the field_data tables, we can duplicate vid (revision_id) and type (bundle) in the property tables to allow them to be queried on those columns without needing a JOIN on the entity tables, resulting in something very similar to #64.Comment #71
catchI'll try to summarize my concerns a bit more, I don't think they apply here reading this again but it'd be good to go over the complications:
- if you have a module like statistics that stores by nid, then if a node type is translatable, there's no easy way to store the results for the 'translation set', votingapi, nodequeue etc. are all similar.
- for an i18n project a couple of years ago, we started adding tnid reference support for some of these projects, so you could start referencing the whole set instead of just the individual translations - at one point we were going to try to add a 'translation group' entity for field sharing as well.
In this case though, even though the node will have multiple records in the same table, loading the node still gets you the same information regardless of language - it's just that some properties/fields may have multilingual values.
We'll still have the issue with storing translatable vs. non-translatable properties and deciding what's what, but that's the same as field API really now - which just stores everything as translatable anyway even if there's only one language.
So I don't think this is going to re-introduce the complications that adding tnids did, or at least not in the same way. Of course having both methods of translation makes things very confusing but hopefully we can drop tnids before too long.
Comment #72
catchI don't think we can keep nid autoincrement and also duplicate it in the same table, so we'd either have to do the two tables method (which doesn't seem awful on the face of it), or switch to the sequence API (would rather not do that if we can avoid it).
Comment #73
gábor hojtsy@catch:
Yeah, this is not something we could *ever* solve from the outside of statistics module let's say. If it does not store data by node + language, it will not support segmenting visits per language, that is it. The appeal of the entity/property/field translation approach is that modules can relate to nids still which would not make them language-aware but they'd still work (vs. the tnid approach, where different nids were involved for translations).
Yes, fields work the same way. And current proposals for CMI language storage do the same, when a value varies by language, you get it stored with the other values, not in some special extra storage.
Yes, the plan is still that we'd drop tnids and the current translation.module altogether and move in a UI for field/property/entity translation. We need to get moving faster to be able to do this :)
Regardless of how we are storing language variants for properties, it would require all code that wants to be compatible with that to write their queries differently compared to how they did it before. Since the property values would differ by language, they'd be stored at different places. Whether its a different table or multiple rows stored in the same table, its going to be different. Code needs to adapt. There is no way we can introduce property translation and hardwired queries can remain intact.
Indeed we have this problem with autoincrements and we can use this opportunity to store non-translatable values in the main entity table (like original language and type for nodes). We'd basically have the properties stored in a table similar to fields then but grouped together instead of their individual tables AFAIS.
Comment #74
attiks commentedI like the approach of {node_property_data}, the following schema solves statistics problem because nid tags the translation set and autoincrement on {node} still works. The performance degradation will be neglectable (untested)
{node} PK: nid
| nid | type | source_language |{node_property_data} PK: nid + vid + language
| nid | vid | title | uid | status | created | changed | comment | promote | sticky | language |First node insert: insert into {node} and {node_property_data}
Update of first node: only update {node_property_data}
Translation of node: insert into {node_property_data}
Node load by nid: will load {node} and all matching rows of {node_property_data}
Node load by nid and language: will load from {node} and 1 matching row of {node_property_data}
Node delete: only delete {node} if {node_property_data} is empty
source_language never changes, so never updates on {node}, only insert and delete
Performance implication one extra join to {node_property_data} using an index
Contrib can add columns to {node} (no translation needed) and/or {node_property_data} (if translation is needed)
Comment #75
dixon_I really like the idea by effulgentia in #70 with a very simple base table and
{property_data_node}.By using this approach we come close to what Gabor is looking for in #64 as well as keeping the ability to use auto increment on the base table and avoid needing to use sequence API. Also, properties would then be stored in a way that is very consistent with how Field API is storing things today. Obviously this would require an extra join for even the simplest property like title. But I believe that's a very valid trade-off for what we are trying to accomplish here.
Comment #76
attiks commentedAs far as I can see there are 2 possibilities left:
My gut feeling is to put vid inside {node_property_data}.
Comment #77
gábor hojtsy@attiks: I think we need to retain the D7 behavior of saving one vid for any kind of change. The API is designed so that an entity is one big thing, and it is very well possible to change things across translations, eg. a VBO action could publish all translations at once, or invalidate multiple translations at the same time. If we'd save new vids per language for each change, that sounds like it would be very different from how we do it right now. It would also make it harder to figure out the changes applied to one language, since you'd need to detect holes in the vid sequence where other languages got vids. So I think its best for consistency and to allow for the API to be used fully to use the D7 system of giving a new vid for any kind of change across anywhere in the entity.
Comment #78
attiks commentedOK by me
Comment #78.0
attiks commentedUpdated issue summary.
Comment #78.1
webflo commentedUpdated issue summary.
Comment #79
fagoI second #75 - the property_data approach looks well to me. Also, I like the analogy to field storage, although it has a more duplication than field storage.
Imho that's a resonable approach to move forward with now.
Comment #80
attiks commentedSo we will use this:
{node} PK: nid
| nid | vid | type | source_language |{node_property_data} PK: nid + vid + language
| nid | vid | title | uid | status | created | changed | comment | promote | sticky | language |Comment #81
effulgentsia commentedI think this:
{node} PK: nid
| nid | vid | type | langcode |{node_property_data} PK: nid + langcode
| nid | langcode | (vid | type | source_langcode |) title | uid | status | created | changed | comment | promote | sticky |{node_revision} PK: vid
| nid | vid | langcode |{node_property_revision} PK: vid + langcode
| vid | langcode | (nid | source_langcode |) uid | title | log | timestamp | status | comment | promote | sticky |The ones in parens are denormalization used for performance optimization only (can avoid joining {node}/{node_revision} for some queries). I don't know if we want to start with them (for consistency with the field_* tables) or without them (and only add them when we can prove the performance gain is worthwhile).
Comment #82
effulgentsia commentedWe'll also need to figure out the above for the other entity types. For example, for {file_managed}, should uri be in the base table or in {file_managed_property_data}. Similarly for {users}, what about mail and pass? In cases like this, if Drupal has logic that essentially would make 0 sense (and possibly break stuff) for some columns to be language-specific, I think they belong in the base tables and not the property tables.
Comment #83
dixon_I really like #81, and I think most people agree here. Let's move forward with this, no?
Let's decide on special case properties (like mail and pass for users) in implementation follow-ups.
Comment #84
gábor hojtsy@dixon_: we talked about starting an example implementation for this with the test entities' properties in core, instead of a real entity that could have lots of side effects (whether it is nodes, users, taxonomy terms, etc. it will need to require all queries being rewritten on them).
Comment #85
damien tournoud commentedI'm coming very late to the party. But one thing we discussed during the Entity sprint in Paris is that we should standardize our datamodel based on the concept of Properties (an extension of the current concept of Fields).
In that model, a Property:
I'm confident that this covers all the possible needs expressed in this thread.
The datamodel we aim for in Drupal 8 is: an Entity has a ID, an (optional) revision ID, an (optional) bundle and zero or more properties; each property is possibly multiple, possibly has sub-columns, is possibly multilingual.
Talking about the SQL schema misses the point completely. We can store some properties differently (especially those that a non-multilingual and non-multiple), but that's really an implementation detail. Let's not corner ourselves with a SQL schema when the most important refactoring that we need to do is to convert everything into Fields (renamed to Properties for the occasion).
Comment #86
effulgentsia commentedI agree with the rest of #85, but not with this conclusion. fago is working on getting an initial Property API patch written, and then a bunch of us (I hope) will help review it, iterate on it, and at some point, it will land in core. But we shouldn't make all that a blocker for continuing progress on D8MI. There's logic within various core modules that needs to be made language-aware with respect to, for example, {node}.title and {node}.uid. I think implementing #81 is a good step towards letting that work happen, as well as not harming (maybe even helping) the eventual transition to a proper Property API and pluggable storage.
Comment #87
gábor hojtsy@Damien: I don't think talking about the storage is/was a bad idea, that is what got us to realize we get here :) Also agreed with @effulgentsia. I don't see why we need to restrict ourselves to a waterfall approach here, we can have independent tasks while the API is being worked on. Unless we can just sit back and assume the APi will solve node permissions as fields and all kinds of other things for us in itself. Then I can go and just sip mojitos. Sounds like a great prospect :)
Comment #88
damien tournoud commented@effulgentsia and @Gabor: I fear you are missing the point here. Now is *not* the time to invent neither a new storage schema nor a new storage engine. We already have a storage architecture in place (the Field API), let's leverage it.
There is no point in migrating twice: once to this new schema and then to the Field API. Let's just migrate everything we currently store in the base table of the entities (other then id, revision id and bundle) to the Field API (that we are renaming Property API), and move forward.
Let's not take a step back instead of a step forward.
Comment #89
damien tournoud commentedLet's not fool ourselves: the storage is the *easy* part of all this. The storage is abstract, we can implement whatever storage we want. The *hard* part is going to get all the things we currently randomly store in the base table migrated to something richer (and also a little bit more involving), and convert every part of Drupal that uses or queries those.
Comment #90
miro_dietikerI need to refer back to attiks #76 discussion.
In fact with content translation we have had separate revisions per language (translation set).
Deciding not to write current revisions per language (and not allowing to write a language only) is a significant regression to the current system.
* We'll create huge amount of dupes on systems with many languages.
* Also we won't have separateable per-language workflows (if multiple editors try to translate node X, the first to save will cause a message "the content has changed" for all other translators that do different languages).
* It might be very hard to decide which revisions are relevant for a specific language
However i agree that this approach would add quite some complexity to the current code... but for the newly built Entity API system i would strongly recommend to base on per-language-current-revision approach.
Am i missing something?
Comment #91
gábor hojtsy@miro: I don't really see how those concerns relate to *this* discussion. However we store translated properties, all language versions being under one entity has this problem, we just treat it as one thing, and if people work on it at the same time, yes, they get the "content has changed" thing. We cannot really solve this in my opinion without making the translations separate things that are related, which is what node translation was/is about. If that is the best of all, we should rip out field translation and just improve node translation. You'll be able to implement a relation based workflow in contrib definitely in Drupal 8 though, if you don't like this language system, just ignore it. You'll be able to ignore it by hiding the translation checkbox on the content type, and done.
Comment #92
effulgentsia commentedThat will mean a temporary performance regression and possibly a temporary DX regression until we get the next phase of Property API completed. Assigning to catch to decide on whether that's ok.
Comment #93
catchI'm not opposed to committing known performance regressions as long as there's a clear plan to correct them and people actively working on that (and the follow-up issues to do so are appropriate priority so they don't get buried) - we've already done that with both CMI and WSCCI patches and entity refactoring is a similarly large scale project we need to try to get right within the next 6-8 months.
However I'm not clear exactly what the 'next phase' of property API is - is that entity-centric storage or something else? It would be good to have the next steps outlined in issues and linked from this one if we go this way, including what the plan is to make this performant with core's SQL storage.
Comment #94
berdirProperty API: Development of the API part of that (implementing all those defined interfaces) is happening in #1637642: Start implementing the Property API currently. That issue isn't about storage at all, though. At least not yet.
Comment #95
gábor hojtsy@Berdir: Wrong link?
Comment #96
andypost@Gabor link is right + #1346214: [meta] Unified Entity Field API
I think we should join forces with Property API to fix current issues with Field API. For query performance we could use
multiple sub-columnsComment #97
gábor hojtsyWell, according to the WSCCI Web Services Format Sprint Report many of the properties will be reference "fields" on their own, like sticky or promoted. It does not really have a clearly laid path for how the rest of the properties would be stored/handled, but it makes a good case for generalized storage and forgetting about properties like we have now. It is not really clear to me what is left here to discuss for us given those decisions.
Comment #98
fagoYeah, as discussed that's the vision we should aim for. However afterwards, we've been working out an implementation plan which concentrates on getting the property api in place first, i.e. establish all the interfaces and make it work with the current split of properties and fields.
At the same time, we can work on improving field api, port storage over to the entity controller and decouple it better so that making a property a field doesn't have unwanted implications, e.g. for the UI. Once we've achieved that we can move the storage of properties over to the fields approach.
So I think the approach outlined by this issue is good for d8mi to move forward. It's improving the *current* node schema to be multilingual - it's not inventing a new storage. So d8mi can ensure it doesn't get blocked by the field api improvements.
Comment #99
gábor hojtsy@fago: can you elaborate on what more exactly it makes sense for us to refactor now, given the somewhat conflicting decisions documented in the WSCCI sprint summary? How do others see this?
Comment #100
gábor hojtsy@Damien Tournoud, @catch, @fago, et. al. I decided to break into visualization again because I think the extent of this does not seem to register yet.
These are the main things we want to achieve in D8MI:
- have 1 way to translate content, we picked field/property translation to be that way
- we need to actually add property variance by language to make that possible
- this has a few huge side effects like having widgets and validators, etc. for these (user reference in core for authors or a custom one-off field for example?; feel the WTF factor there?)
- another huge side effect is permissions; once a node/entity can be from different authors and can vary publication states by language, its permissions / access will vary by that too; we will likely need to add language to node permissions as well
- while this craze is going on, if we have basic property storage varied by language at least, we can build a UI on top of it
- then at that point we could say we have a replacement for translation storage and UI that node copy translation data should be migrated to; the whole migration path needs to be in core too as per current standards
Does this process sound easy as pie for the remaining
45 months? Is postponing the migration path and removal of the module fitting post feature freeze (well, it would be a distinct removed feature, so technically speaking hard to imagine).That is, we should figure out way to paralellize this work or we'll seriously screw very core systems of Drupal, whether your entity forms will be built in crazy ways or your permissions will be whacky and unreliable in Drupal 8. We can wait around mumbling and then attack all the problems at once in a couple months instead and get half-assed solutions in or we can get our act together and work on this sooner than later.
Reading the summary from the WSCCI sprint (http://groups.drupal.org/node/237443) and talking to Crell there is no consideration in the property API for storage layers or solving language-variance for properties. It is unclear to me if solving separation of editing widgets, validation and entity form building based on those is part of the process either. I hoped that would be, but that is not very clear from the ongoing issues.
So the question is how we can best work on things needed to solve this big picture without stepping on toes and not leaving everything for the last month to finish.
Comment #101
gábor hojtsyAny good tips as to where to move forward to not clash with the entity work? I hate doing figures and summaries that just stop the conversation :/
Comment #102
plachI'm afraid the level of partecipation here indicates that we need to move forward with the Entity API clean up and hope that it will bring the schema refactorings "for free".
Comment #103
fagoI think it's fine to continue with this issue as discussed now. As said in #98:
I don't think they conflict. Obviously, for making more stuff translatable we'll need to move forward with the entity property API. At this point, we can already fully embrace the storage architecture as discussed in this issue and have translatable properties (being not fields yet).
Then, in the next phase we can convert more and more property over to the field systems. But for that, we'll need improvements to the field api be in place, such that it is better decoupled and storage goes via the entity controller. That way we can keep the custom-storage for entity base properties (e.g. node author, status) as well as possibly custom widgets although they become "fields" as well.
Comment #104
gábor hojtsyOk then, executing on this issue at #1658712: Refactor test_entity schema to be multilingual, help is welcome there.
Comment #105.0
(not verified) commentedRemove outdated stuff from summary
Comment #105.1
das-peter commentedUpdated issue summary to match to the Change record