
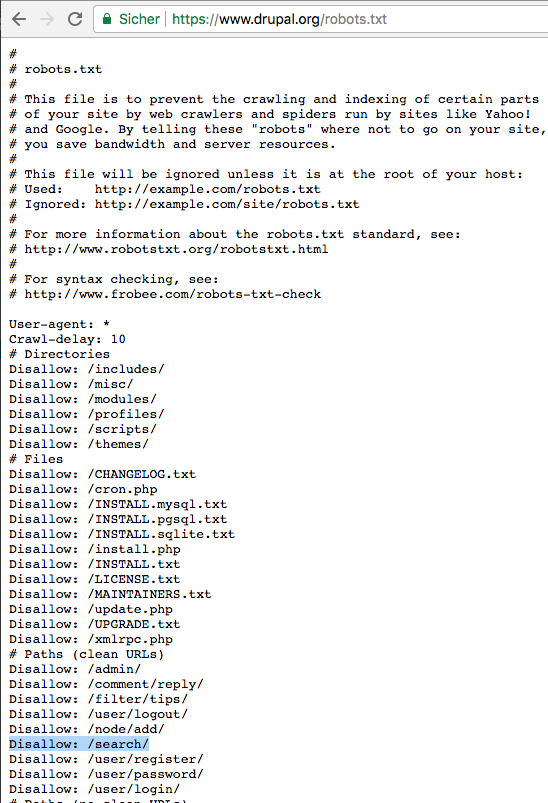
This code should be removed from robots.txt
# Paths (clean URLs)
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /node/add/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
# Paths (no clean URLs)
Disallow: /?q=admin/
Disallow: /?q=comment/reply/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
This code should be added to these pages instead:
<meta name="robots" content="noindex">
There are two main reasons for doing this.
- First, without a "noindex" meta tag, search engines will still list these pages in search results, they just won't crawl them.
- Second, by allowing robots to follow on these pages, the PageRank on the linked pages (primary menu, blocks) will increase.
See: http://www.seomoz.org/blog/serious-robotstxt-misuse-high-impact-solutions
| Comment | File | Size | Author |
|---|---|---|---|
| #15 | Bildschirmfoto 2017-06-09 um 16.31.15.png | 120.85 KB | nodestroy |
| #15 | Bildschirmfoto 2017-06-09 um 16.31.05.png | 140.47 KB | nodestroy |









{kind=link}
{kind=link}
Comments
Comment #1
yonailo CreditAttribution: yonailo commentedsubscribing
Comment #2
yonailo CreditAttribution: yonailo commentedsubscribing
Comment #3
RobLoachInteresting... Would this use both robots.txt and the meta tag, or just the meta tags?
Related: #495608: Move parts of robotstxt module into core.
Comment #4
j0nathan CreditAttribution: j0nathan commentedSubscribing.
Comment #5
pillarsdotnet CreditAttribution: pillarsdotnet commentedComment #6
userok CreditAttribution: userok commentedBy allowing those links to be crawled, wouldn't that impact on site performance?
eg, on every instance of /comment/reply, the link needs to be crawled first, in order to access the meta tag 'noindex'.
I'm a bit hazy about indexing so I could be completely wrong.
Comment #7
Roger34 CreditAttribution: Roger34 commentedI am not sure if this post belongs to this page, since it did not get a reply elsewhere (http://drupal.org/node/22265)I am posting here:
I use default robots.tx in drupal 6.22. But google webmaster central, performance overview shows that prohibited directories are also accessed. Do you suggest that I will be better off adding paths in meta tag? I have the following listed in the google webmaster central under example page loading time:
/admin/content/add 1.9
/node/add/story 2.3
/node/add/article 3.1
/rss.xml 0.6
/node/15008/edit 2.2
/admin/settings 0.9
/admin/reports/status 1.6
/admin/reports/status/run-cron 120.01
In addition to Disallow: /admin/
do I also need to specify for example: /admin/reports/status/run-cron. I am sure no one wants the crawler to spend 120 seconds on cron.
I also do not like google to crawl node/add/
Would appreciate a reply.
Comment #8
ar-jan CreditAttribution: ar-jan commentedI like this idea. Re #6: yes, I think so, the page would have to be crawled. So apart from any possible performance impact, for very large sites (thousands of pages) this would mean the crawler spending time on irrelevent /comment/reply pages, crawling time that should be spent on actual content. (Unless noindex pages are 'free' as far as far as crawling effort is concerned?)
@Roger: no, this is not the place to ask, this is an issue about changing the way Drupal core works. But: the default robots.txt prevents search engines from even crawling those pages. Everything under /admin/ is already disallowed by that line, so you shouldn't have to add that particular cron page. Better check that your robots.txt is accessible. For further questions head back to the forums or IRC.
Comment #8.0
philbar CreditAttribution: philbar commentedUpdate for clarity
Comment #9
jhedstromMoving to 8.1.
Comment #10
iantresman CreditAttribution: iantresman commentedJust a note that I think that some of the paths in the robots.txt file appear to be incorrect, and do not block the required pages. See "robots.txt paths incorrect"
Comment #14
chapf CreditAttribution: chapf commentedToday, after checking the access logs of a drupal based website I administer I was rather surprised to see googlebot constantly crawl some of the pages that are listed in the stock robots.txt file.
So I found this issue here and then read up on some of the documentation google provides for its crawler and they clearly state that robots.txt isn't any good in preventing a page from being indexed or crawled or listed in the search results. Basically useless for the purpose I think many people still assume it fulfills!! (Source: https://support.google.com/webmasters/answer/6062608?hl=en)
Now I don't mean to be annoying but is there any concrete plan to move forward on this problem or should I have a look into contrib modules? Seems wrong to me since this little file is core functionality and there is also other open issues for robots.txt listed above.
Comment #15
nodestroy CreditAttribution: nodestroy commentedfrom my point of view we should completely remove that urls from robots.txt and replace that with a x-robots-tag implementation - if thats possible with compatibility in mind.
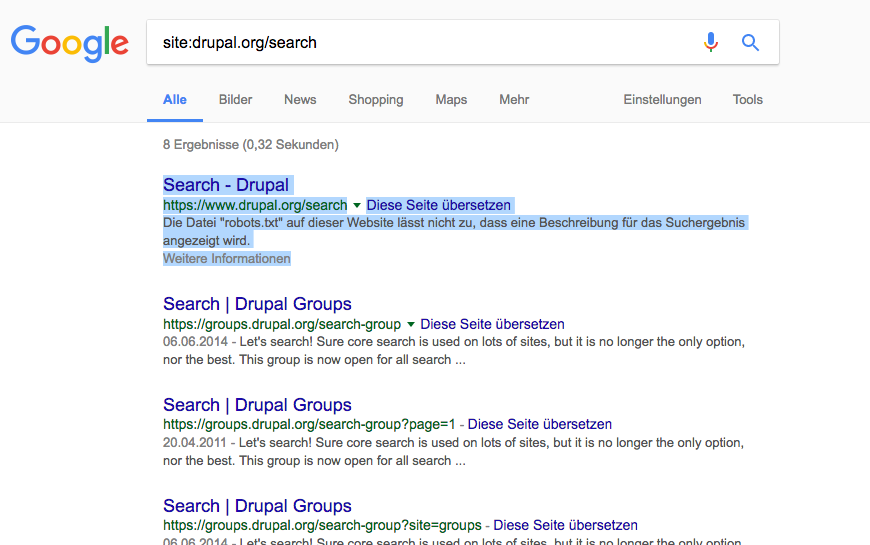
listing a specific page in robots.txt is no guarantee to prevent it from indexing. see an example below from drupal.org
Comment #16
no2e CreditAttribution: no2e commented@nodestroy:
robots.txtis used to prevent crawling, not indexing. Your screenshots show exactly this. The page is indexed, but not crawled (hence why the search result snippet refers to the robots.txt as reason why no relevant snippet could be shown).X-Robots-Tag(and the equivalentmeta-robots) prevents indexing, not crawling. To allow bots to notice this, they have to crawl the page, of course.In both cases, "prevent" is of course not meant in a technical sense. Both ways require that the bot and the search engine are polite.