
 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.In D8 HEAD, a significant portion of rendering the page is spent in bubbling cacheability metadata. There is at least some room for optimization still.
For example: we currently validate cache tags and cache contexts every time we bubble. That's done to give good stack traces to developers. But it's not free. We could choose to only do this when "finalizing": when writing to the cache or when generating the X-Drupal-Cache-(Tags|Contexts) headers.
@dawehner had some profiling (can't find it ATM) that showed this quite clearly.
| Comment | File | Size | Author |
|---|---|---|---|
| #11 | bubbleable_merge_before.png | 147.32 KB | berdir |
| #11 | bubbleable_merge_after.png | 147.97 KB | berdir |
| #11 | bubbleable_merge_diff.png | 226.5 KB | berdir |
| #11 | mergetags_after.png | 142.72 KB | berdir |
| #11 | mergetags_diff.png | 204.88 KB | berdir |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
berdirYes, I can definitely see this too, although I'm not quite sure how much of that is overhead, especially if you look at a patch with a cold render cache, there are hundreds to thousands of those method calls.
+1 to not sorting/validating during merge.
I'm also seeing BubbleableMetadata::createFromRenderArray() and BubbleableMetadata::merge() quite high in the list, but that was done on a a bit older core version, we might have already refactored/optimized some of that.
Comment #2
dawehnerhttps://www.drupal.org/node/2342045#comment-9707699 contains the profiling where I saw those methods.
Comment #3
wim leersSo that's #2342045-192: Standard views base fields need to use same rendering as Field UI fields, for formatting, access checking, and translation consistency, relevant data:
In the first link: 22 ms (3.22% of total page generation time) spent in
Cache::mergeTags().Comment #4
wim leersComment #5
wim leersBrought from #2458349-23: Route's access result's cacheability not applied to the response's cacheability:
Comment #6
berdirHm, so now we also have a service call to validate contexts in mergeContexts().
I'm not sure I understand why we bother with that there? it just means we validate them over and over again. Why not just validate where we actually use them, which is somewhere in Renderer?
Comment #7
dawehnerI think the point was that the error should happen as early as possible, so its easier to find the code causing it.
Comment #8
wim leersWhat #7 says.
Comment #9
berdirYes, I can see that, but that only works partially, when you merge with something else, it might also be what has already been set by someone else.
AFAIK you're adding a new API that allows to set those things through the renderer service, maybe we could additionally add it there instead?
The question IMHO is, is the improved DX worth that additional performance cost. I'll try to do some tests of the next days. In recent profiling runs that I did, multiple of those methods where listed high when sorted by exclusive run time. And IIRC, a large amount of the calls were caused by the renderer itself, due to the stacked rendering. Maybe we can introduce a mergeNoValidation() or something version of those and call them there, because it won't really help anyway when an exception is thrown there.
Comment #10
wim leers+1 to everything in #9.
#7 + #8 just explain the rationale for why it works the way it does today. Obviously, if that's too costly for performance, we need to re-evaluate that. It's basically DX versus Performance: more of the former or more of the latter, not both. This is why assertions are so interesting for this: we need the DX only while developing, and we want the performance especially when in production. Assertions may thus enable us to have both. See #2454649: Cache Optimization and hardening -- [PP-1] Use assert() instead of exceptions in Cache::merge(Tags|Contexts). To move forward with that, we need a PoC patch and profiling to see if that's viable and if it's worth it.
Comment #11
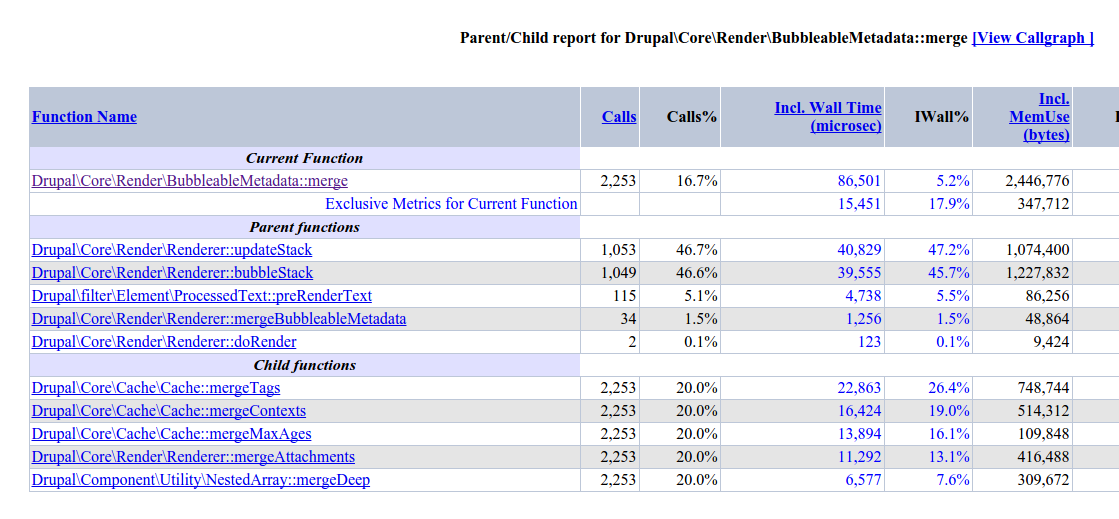
berdirOk, so here are a few numbers. The profiling overhead is definitely high because those methods are called a lot, but still, there's a lot going on.
I've tested this with a disabled render cache to simulate a cold cache. Of course, when that is enabled, then there are a lot less calls. Comparison numbers of that below. Tested on the frontpage of my installation profile, with beta8, so without the cache context validation.
HEAD:
Total wall time 1.6s
90% of that is in doRender(), which is both good and bad.
BubbleableMetadata::merge() is 5.2%, 2.3k calls
Cache::mergeTags() is 3.4%, 6k calls
Cache::mergeContexts is 1%, 2.3k calls
Cache::mergeMaxAges() is 2.1%, 5.9k calls
Those calls are overlapping of course, a large part of the Cache::merge* calls are from merge() (40-50%, most of the other half is AccessResult)
With the attached patch, we save a bit (around 1% of the total wall time). And maybe other improvements are possible too. mergeMaxAges() for example, I think we can make it a bit faster by doing a simple loop instead of fancy array_filter() functions. Again, the numbers come with considerable overhead, but it should still be worth doing some micro-optimization here.
With enabled render cache, I'm down to 600ms on that page. And there are still 700 calls to BubbleableMetadata::merge(), still 5%.
And comparing the same when the profiler is disabled, numbers based on ab -n 50 -c 1
Render cache fully enabled: 140ms
Completely disabled: 700ms
(that's an even bigger difference than I expected, also the result I saw in the browser were a bit higher, 960ms and 200ms, ab also went up to those numbers)
Given those numbers, I'm not sure how much we can actually trust those improvements. I tried to compare it with ab, but for some reason, it behaved very strange.
Would also love to compare that with PHP7 too, but that will probably have to wait until I can update to beta9.
Comment #12
wim leersThanks for kicking this off, Berdir!
catch tried that, didn't notice a difference: #2443073-39: Add #cache[max-age] to disable caching and bubble the max-age.
I think @dawehner made a good point: all of these functions accept N arguments. But typically, we only call them with 2 arguments. If we'd only deal with 2 arguments, we could potentially make more aggressive optimizations.
Comment #13
berdirOk, different approach for testing this.
xhprof and xdebug disabled.
PHP 5.5: 16-17ms
PHP 7: 4-5ms (yeah. Can I haz php7 today plz?)
Without validate + unique + sort:
PHP 5.5: 8ms
PHP 7: 2ms
Comment #14
wim leersNice! :)
4-time speed-up, makes sense. This is all super simple code. It was mostly slow because of PHP overhead. Less overhead = huge speedup!
Comment #15
borisson_This was fixed in #2471232: Optimize Cache::merge*(), by only accepting 2 instead of N arguments.