Follow-up to #2150511: [meta] Deduplicate the set of available field types
Problem/Motivation
Deduplicate available field types. We have (plain) string, mostly used for base fields and text which have a setting to enable text processing (select a text format, wysywig and stuff). So text fields without that option enabled are essentially the same as string fields.
Proposed resolution
Expose string fields, which currently have the no_ui option set to TRUE as "Text (plain)" and "Text (plain, long)" in the UI, remove the option from text fields (to disable it, so that it is always enabled), rename them to "Text (filtered)" and so on.
Remaining tasks
User interface changes
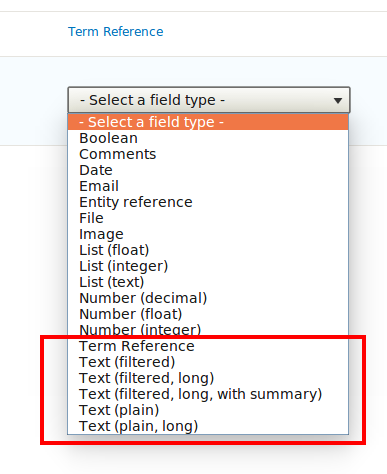
As described, more options for the field types (+2), removed the option from text fields (which defaults to FALSE and I think people often forget to change). See screenshot.
Before:

(Note that it is not just Text but also "Long text" and "Long text with summary". We're really just adding Text (plain) and Text (plain, long) to the list.
After:

API changes
Option removed, all text* fields automatically have it enabled.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
berdirFirst patch.
Biggest problem so far was actually to make sense of the different editor plugins, could use some help from Wim on that.
Comment #2
berdirOh, forgot the screenshot.
Comment #4
yched commentedThanks a ton for pushing this, @Berdir.
Nitpick : I think "Filtered long text" is a bit weird. If I'm not mistaken, in proper english you'd tend to say "Long filtered text", "filtered" being a more intrinsic characteristic than "long".
Given that Number and List field types already use parenthesis to be alpha-sort friendly, I'd think we can go with :
Filtered text
Filtered text (long)
Filtered text (long, with summary)
Plain text
Plain text (long)
?
Other than that, the possibility of adding optgroups in that list was mentioned a couple times, we just never actually crossed that line. Would require adjusting the annotations a bit, so probably for a separate issue. Just mentioning the possibility in case we find no way satisfying way to structure the flat list.
Comment #5
yched commentedSide note : #2226493: Apply formatters and widgets to Node base fields already adds 'string_long' field type to the TextTextarea widget.
Comment #6
wim leersLooks great, from an
editor.modulePOV!I only made one functional change:
PlainTextEditorshould not limit itself to the "string" fields, it should only limit itself to not support "filtered text" fields. It's more likely that special-purpose string-like fields will be added than that more filtered text-like fields will be added. Hence the inverse condition makes more sense :)The remaining changes that I made are all to reflect that we are now effectively officially calling "processed text" fields "filtered text" fields. Hence I've updated
editor.moduleand its plugins to reflect that. Consistent language helps with maintainability & understandability.I did not try to fix failing tests in this reroll.
Comment #7
wim leers:D
Also fixed the Quick Edit test failure and one other.
Comment #10
sunAwesome, thanks for working on this.
Though, hm, can we think of a way to keep the options sorted/grouped together, using a shared prefix? They're all about text, so it's a bit confusing UX to have some options in one spot and some others elsewhere.
For example - focusing on the intended end result, so intentionally omitting text_filtered_long_with_summary:
Looks much more pleasant to me?
Quite possibly separate issue, but we should also rethink "long". That's not very intuitive. It would make more sense to use "single-line" and "multiline", since both words are common language. (It doesn't matter that you technically can insert newlines/
<br>s.)Comment #11
andypostAlso about UX - there's #1963340: Change field UI so that adding a field is a separate task
Suppose this change would allow to provide a description for each field type to properly describe each field purpose
Comment #12
berdirWorking on this.
Comment #13
berdirRenamed the labels, I like this, not sure about the summary thing, but I think it's OK like this.
Fixed most tests, can't really make sense of HandlerFieldFieldTest, going to ask @dawehner for help.
Also not sure about TextPlainUnitTest, there is a ton of helper methods on there and a very short test that is testing text fields with the string formatter. We can either switch that to use a string field or we can remove it, did the second for now.
Comment #15
yched commentedQuick review before I go afk for a couple days - not much to complain about :-)
Also, 'string*' field types have the following widgets :
'string' = textfield
'string_textarea' = textarea
For 'text*' field types it's :
'text_textfield' = textfield
'text_textarea' = textarea
Maybe the 'string' widget should become 'string_textfield' for consistency ?
The comment above this code block ("Set up two fields: one with text processing enabled, the other disabled") is now stale ?
At any rate, it looks like this test is now about the 'string' formatter for 'string*' field types, and no longer belongs to text.module ?
It looks like it certainly could be skimmed down (wasn't there a commit that added assertStuffAboutContent() methods to DUTB, or did I dream it ?), but the "Verify that all HTML is escaped and newlines are retained" part would make sense to keep for the 'string' formatter - I vaguely remember nasty cases in that area, the regression check would be nice to keep.
Comment #16
dawehnerThe patch needs a reroll, so I tried that, I hope this isn't totally wrong. On top of that here are the adaptions to the test, so that the
previous functionality is still tested.
Comment #18
berdirThanks, another reroll and hopefully fixing the remaining tests.
Comment #20
berdirComment #21
wim leersVerified that with this patch applied, we have zero remaining occurrences of "text_processing" (except in migration tests' simulation of D6/D7 databases, of course).
Nitpick: Why do we want to remove this assertion? I think it's because we can no longer format filtered text fields as plain text. But shouldn't we then also create a
StringFieldRdfaTestto ensure we don't reduce test coverage?… we may want to re-enable this one :)
Shouldn't we also turn this into
Text (filtered, long) settings'?Analogously for the other ones.
Why can we delete this test?
I think this one is very close!
Comment #22
wim leersComment #23
berdirRe-roll.
Conflicted in TextPlainUnitTest, instead of removing, I sent that one through a very strict diet and renamed it to StringFormatterTest (in field.module). Almost all helper methods that were now already in the parent removed, but they were slightly different, assertText() didn't work the same way, so I removed the assertText(), as we already have the assertRaw() with the exact format we're expecting, the other seems to be testing assertText() and not the formatter?
Also removed the part about cache tags from TextFormatterTest to StringFormatterTest for the string formatter.
Addressed Wim's review, added a rdfa test for the string field type, re-enabled the test, updated the schema description and re-added the test as described above.
No readable interdiff, as most of the changes happened during the re-roll, messed that up... Instead adding a raw diff against the previous patch, a bit hard to read but shows the exact changes between the two patches.
Comment #26
berdirHad some weird no remaining sql connection test fails, green after re-test.
Comment #27
yched commentedTextPlainUnitTest: cool :-)
Not sure whether #15 1. and 2. were adressed ?
Comment #28
berdirNo, they were not, missed that, sorry. Will update it asap. (I think it's looking good other than that?)
Comment #29
berdirOk, removed string from TextFieldWidget, renamed string to string_textfield/StringTextFieldWidget, let's see if I found all instances.
Also removed that comment.
One thing that is missing here is migration I think, because we need to change the type based on the field setting, I don't think the current mappings can deal with that, and we need to map the widget/formatter based on the field type.
Comment #30
berdirComment #32
berdirFixing those tests.
Opened #2324649: Migrate text fields correctly based on their text_processing setting. for the migrate part. @benjy is OK with a follow-up for that.
Comment #34
berdirMissed the default config files.
Comment #35
fagoGeneral, big +1 on resolving the mess around current string + text field types. I'd already explain it that way that text fields are about text processing and their option to turn it off does not make sense given we have got the string field types to developers.
For sitebuilders this patch removes the ability to switch between text-processed fields on the fly, but I think that's ok and makes sense as it is/should be a change in the data model (there is no point in creating an unused format column). Field types should be perceived as "what data is going to be stored", what this patch encourages.
I've discussed with berdir a bit on IRC whether it makes sense to have a field type with machine name "string" and human readable label "Text (plain)", but given the different target audiences (devs / sitebuilders) I'd consider it ok in that case.
Finally, this patch starts to use the wording "filtered" instead of "processed", what makes sense given it's making use of the filter system ;). We could consier renaming the computed processed property to "filtered", but that would have to happen before beta also.
Moved around code, but this seems to to test $value only, but not the rendered output?
Some whitespace here.
Weird that this becomes a sequences now, it should be still a mapping even if empty, right?
E.g. this is what the boolean field types uses:
type: mapping
mapping: { }
Btw, why do we have field config for core field types below the field.modules?
Comment #36
yched commentedYeah, agreed that the field type names are not ideal yet - meaning, still tainted by history rather than reflecting the actual model.
Patch does:
string* = "Text" - with SQL underlying type TEXT, btw (well, or VARCHAR...)
text* = "Filtered Text"
That's not what we would have chosen if we were designing a fresh system :-) - more probably something like:
text
text_long
filtered_text
filtered_text_long
filtered_text_with_summary
But then it's another case of "A becomes C, B becomes A" nasty rename ('text' / 'text_long' become something different).
Also, it raises the question of "text.module provides filtered_text* but not text*" - which also relates to "do text.module, number.module still have a justification as modules" ?
All in all, I think there's room for enhancement there, but IMO it's reasonable to keep the renames for a separate issue, and tackle the funtional changes & field type remapping here.
Was wondering the same :-)
Since it's already the case in HEAD, it's fair for this patch to stay consistent for now. Opened #2325999: Move config schema for Core field types out of field.module
Comment #37
yched commented'filtered_text' ?
+ the class also has a "Verify the processed text field formatter's render array" comment that should be updated.
Comment needs to be updated, this now only tests "without" text filtering - and we lost test coverage for filtered text ?
Whitespace
$filtered_value ?
4 places within editor/quickedit use that list, it should probably be centralized to a helper method somewhere (but not sure where :-/)
Comment #38
yched commentedAlso, very sorry for what I'm about to post, but thinking about it more I'm not sure "filtered text" is the right terminology :-/.
Being given a choice between "Text" and "Filtered text", the second option sounds more restricted.
The actual difference for users is: the former will give me a dumb text input where HTML won't be active, while the latter will give me a CKeditor where I can do lots of pretty stuff.
So I'd think "plain text / rich text" is more telling.
A "filtered text" only requires filtering because it's "rich" (and thus potentially dangerous), but that's a technical consequence, not the actual feature that makes sense to end-users, the actual feature is that it's "rich".
+ "filtered text / filters" are drupalisms, while everyone knows what is a "rich text editor".
I still think it's more accurate to talk about the "filtered version of a rich text" than of the "processed version" (in the cases where code / comments need to differentiate between the raw and safe versions), so the general "s/processed/filtered" move in this patch is still fine IMO.
Comment #39
yched commentedAlso, going with "filtered text" for the field type causes the ambiguity, present in a couple places in the patch, that you have code and comments about "the unfiltrered (raw) value of a filtered text" and "the filtered value of a filtered text". - i.e. the "filtered text" is not always actually filtered :-)
Talking about a "rich text" field lets you unambiguously talk about its raw and filtered values.
Comment #40
sunNot sure I'm able to follow - the screenshot in #13 had "Text (plain*)" vs. "Text (filtered*)":
It might make sense to rename "filtered" to "formatted", because users are more likely to understand the difference between plain text and formatted text, but that's just a minor UI/wording tweak.
(Renaming the internal IDs that way would not be sensible, since "formatted" would be ambiguous with Field Formatters, and "filtered" is pretty precise from a technical perspective.)
Comment #41
yched commented@sun: what I'm saying is that
- yes, technically, "filtered" is more accurate than "formatted", so we're right to move to the former where we're talking about "the string once passed through check_markup()"
- but either "formatted" or "filttered" make little sense to end-users, what makes sense for them is "rich" :-)
Comment #42
sun@yched: I don't agree. "rich" is an overloaded term due to historical IT evolution. It primarily assumes a familiarity with Microsoft products, which is (thankfully) no longer a given in today's world of consumer devices. Without that legacy association, "rich" doesn't encompass any sensible meaning to a human. A content may be "rich" of words (as opposed to e.g. poorly written), but there is no relationship to text editing, processing, or formatting. Contrary to that, the act of "formatting a text" is unambiguous and clear, even beyond the scope of computers.
Comment #43
yched commented@sun: you think "plain text / rich text" is ambiguous ?
RTE / "rich text editor" is common lingo, so I'd think people are much more akin to figure out what "rich text" means as opposed to "filtered text", which, to me, feels like a "less powerful version of a regular/plain text".
Maybe so, but "formatted" has been ruled out and is being removed from the UI.
Anyway, I don't intend to bikeshed on names here if this is controversial.
Fine with RTBC when pending remarks are adressed :-)
Comment #44
berdirCatching up on reviews...
#35
1. I don't understand this. renderEntityFields() puts it in rawContent() and then we assert for the string we expected in the raw/rendered output. This is using the new trait-based content assertion.
2. Removed.
3. I found that weird too, but the mapping didn't work, field.schema.yml is also inconsistent, see field.integer.settings and field.email.settings, boolean actually has field level settings, it's the instance settings that are an empty mapping. Trying again.
#36: Not doing any field type renames for now.
#37
1. Updated to filtered, removed processed from the comment.
2. Updated the comments. We were only testing text fields to test it with/without text processing, I can't see how we would be checking that now, text field type is tested in the next method.
3. Same as #25.3, 2. removed.
4. Renamed.
5. Yeah, not sure about that, but it seems like a bigger problem to me, what if contrib defines a new field that that it wants to integrate with the editor too or something? Maybe check if there is a filter property instead? Don't know...
6. Started renaming this, but its quit a change on it's own and it's actually not that far off from. the filter system sometimes also uses processed/process/processing, see FilterProcessResult for example. In that way, this also seems a possible way out of the "(un)filtered text of a filtered text field", we could have a filtered text field (text + filter) that is processed or not?
#38-43:
Um, yeah. Am I understanding it correctly that we're mostly talking about the UI labels and comments? If so, then I think it would make sense to do that in a follow-up issue, that's a minor change compared to everything else it seems.
Comment #46
berdirArg, accidently included half of the processed/filtered rename. interdiff is against #34.
Comment #48
yched commentedWill probably need to be adjusted after #2325999: Move config schema for Core field types out of field.module .
Still feels messy if you ask me.. It seems a bit far-fetched to have "filtered" not mean "has been filtered", and "processed" mean "filtered text has been filtered" (even though I love "grumpy cat is grumpy" :-p)
Anyway, yeah, let's keep that for another issue.
Well, in my mind that spills to the field type IDs and class names if we want to keep our sanity, but yeah - followup.
- re - #37-5 and hardcoded list of field types :
Agreed that hardcoding the list is not ideal, but that's what the patch does currently, so hardcoding in one place is a little better than hardcoding in four places ?
Then, we can talk with @Wim about how to change the content of the method from a hardcoded list to something extensible (an entry in the field type annotation ? a setting ?)
Comment #49
wim leersRE: #37.5: yes, let's discuss that in a follow-up. I just created that follow-up and already added all relevant information, and the general steps that should be taken: #2327941: Simplify in-place editor selection (Was: Refactor PlainTextEditor/WysiwygEditor/Editor in-place editors now that text fields no longer have configurable filteredness). In short: it will actually allow for a clean-up, and the code cited in #37.5 is necessary for now, but we should be able to remove that altogether. Fixing it here would lead us in the scope of Quick Edit module though, so let's do it in that follow-up I created.
Comment #50
berdirOf all the kernel tests in core, the clearly had to use exactly the one I'm renaming in the new test.. ;)
Comment #52
berdirWell, it doesn't help if I re-upload the wrong files. Was late...
Comment #53
sunLooks ready to me — just to nits:
Rule of thumb: Always use the strict comparison flag for
in_array(), unless you explicitly want to perform a loose comparison; i.e.,in_array(…, …, TRUE)We can keep 'text' as a secondary @group, but the first @group should be 'field', since this test is in field.module.
Comment #54
berdirAdded TRUE and updated the @group, just forgot to change that when I moved it. Doesn't belong to text.
Comment #55
wim leers312 insertions, 811 deletions.
A wonderful simplification.
Thanks, Berdir!
Comment #56
andypostI think this needs change record and final update to summary
wrong indent, could be fixed at commit/re-roll
Comment #57
wim leersYou're right. Back to NW for a change record.
After that, this can go straight to RTBC, #56 can indeed be fixed on commit (good catch though :)).
Comment #58
berdirCrated the change record: https://www.drupal.org/node/2329465
Made some small changes to the issue summary, but not much changed other than the field type labels.
Comment #59
wim leersLooks great. RTBC +1.
Comment #60
chx commentedThis is perhaps a followup: since we are fixing this mess, what's the difference between text field and text field long? *I* know it's varchar vs text -- but shouldn't that be a field setting that the storage can decide upon? Would decrease the confusion here.
Also, nitpick:
Indent error.
Comment #61
yched commentedre #60 - "short / long" as separate field types or a storage setting :
Can't really remember the exact reason why we made the split in D7, IIRC we tried to reduce the occasions were changing a setting would mean SQL type conversion. It would probably work, as we can forbid changing that setting once the field has data anyway.
Main drawback I see atm is that the default widget is typically not the same - textfield or textarea. So for example after adding a "text" field with "long" setting, you'd get a silly mono-line textfield widget until you to visit "Manage Form" to switch it "textarea".
Unless we refactor to a single widget outputs a textfield or textarea depending on the field...
At any rate, yeah, separate issue.
RTBC +1 on this one :-)
Comment #63
berdirRe-roll and fixed the wrong indentation there.
Comment #64
fagoyeah, that has been bugging me as well in particular as we've the setting for integers. However, as one models the data structure using field types it seems to make sense to have a different field type for a different storage type, so there is a clear mapping. But then, that's a quite SQL centric view... Howsoever, separate issue.
I guess it would be nice to have the default be returned from a method, so it could take field settings into account.
Comment #66
berdirgit rebase powered re-roll.
Comment #67
catchAlso sorry to bring this up but I agree with yched in #38 - the Text (filtered) looks very odd to me, and it doesn't match with either text editors or 'text formats' which is what we expose elsewhere. You only see filters for the configuration of filter plugins for text formats, and you can use Drupal for a decent amount of time without visiting that screen.
Comment #68
Bojhan commentedI think its rather odd that you have to make this choice upfront. From a strategic standpoint, I dont think we should be adding more and more to this list - but instead make the next step "field configuration" more important and better able at providing you the choices. chx gives a perfect example for this.
With that in mind, I think we should at least open a meta or followup for this. Because in the larger scheme of things it just doesn't make sense and won't scale. \
Other than that catch is right that the labeling isn't very usable. Can we perhaps just mention the actual concept like "text formats"? Like (with text formatting), we probably don't have to signal that the other one doesn't have it.
Comment #69
andypostThere was #1963340: Change field UI so that adding a field is a separate task but usability here also questionable
Comment #71
berdirRe-roll if someone wants to try this out.
@catch mentioned in IRC that he would be equally OK with formatted or rich instead of filtered.
I also asked @webchick to provide feedback.
Comment #72
catchJust to clarify reasoning:
- "Formatted" might not be perfect, but it matches the language we use with "Text formats". If I have no idea what it means, I can at least scan the configuration page and the word format is in the menu pointing to the right place. Filtering as a concept you only see when you're actually configuring a text format (which is a very rare operation).
- "Rich text" this works as colloquial term to go along with rich text editor, which also gets you back to text formats if you follow that route (eventually). Also pretty clear what it means compared to "plain text".
Comment #73
Bojhan commentedHmm, I hope we can just make a follow up to do this in a separate page. Then you can offer "text" and than provide two additional dropdown, that is much more sensible, than this combined in one dropdown approach. I feel that is the right way to go, and although I am sure this labeling is more consistent - at the end of the day we evaluate by how "usable" and it doesn't really meet that standard.
Comment #74
yched commented@Bojhan: The whole purpose of this issue is to split "plain text" and "formatted/rich text" into separate field types.
The rationale being:
- We need to keep a simple, lean and performant field type for base fields like "node title", "comment subject", ... that store raw strings. That is the 'string' field type in current HEAD.
- In HEAD, that 'string' field type is not available in the UI. Instead, there is the 'text' field type, which can, on a second screen, be configured to be about raw text or formatted text (= a text + a format).
- In the "raw text" mode, this field type thus behaves exactly like 'string', which means code duplication and DX confusion (not in the UI, but in the set of field types available to developpers). We need to remove that duplication.
- However, for the perf reasons explained above, we cannot simply remove the 'string' field type in favor of 'text', and state that current 'string' fields will be 'text' fields in "raw" mode.
- Additionally, "a raw string" and "a string + a format" really are two different things in a data model - and you need to pick one upfront anyway, since there is no changing your mind and switching from one to the other once there is data in there : you cannot arbitrarily assign a format to a string that was just a raw string so far, and you cannot decide to suddenly treat a string with a format as a raw string, ditching its previous format.
Those really are two (related but) separate field types. I'm really not in favor of artificially smushing them in the first UI screen, to then offer a secondary choice in a second screen. The first screen list field types - if there are two separate field types, they should be listed as two options; I don't see ourselves bending the UI to make an exception here, sounds like a nightmare implemetation-wise.
If we really are worried about adding new options here, and need a way to make "similar / related" field types more obvious, then as mentioned above, adding optgroups to that list is easily doable (in a separate issue :-p). But let's not artificially "merge" field types just to avoid adding options in that list.
Comment #75
wim leersI agree with the sentiment in #74. This issue is about code simplification and prevention of an entire class of security problems inherent to the current approach.
I also see Bojhan's concerns. But I think those concerns essentially boil down to "we should improve Field API's UI". The exact same reasoning () can be applied to other fields: File and Image (). Similarly for number. And so on.
Improving the Field API UI is out of scope for this issue. This patch is more than big enough already. Last but not least: Field API UI improvements like this one are a perfect example of an improvement we can add in Drupal 8.1.x!
P.S.: https://www.drupal.org/project/hierarchical_select :)
Comment #76
berdirAgree with you two, but the one thing we do need to decide is filtered vs formatted vs rich. It is filtered right now, but @catch didn't like that and would be equally OK with either formatted or rich, so which one should it be?
I'm leaning towards formatted, for the reasons @catch wrote in #72. formatted is close to text formats, if you don't know the difference between plain and formatted, then searching for formatted should pretty quickly lead you to text formats. filtering is the technical process, but in the UI, we mostly talk about text formats.
Comment #77
Bojhan commentedWell, I gave my review. If improving the UI is not in scope, I don't want to spend my time discussing it. This will make the Field UI more difficult to use, its already crappy to use, so just more crap :) Please stop requesting usability reviews, of UI's that cant change anyway.
Fundamentally I disagree with the stance that this choice should be exposed at the top level of the UI. There is technically no reason, we can't do it on the second level (as I am reading here) other than a preference to expose everything upfront in one UI.
Comment #78
berdirOk, renamed everything that was changed in the context of this patch from filtered to formatted. I think that makes more sense. Also discussed with @swentel, who was OK with this.
@Bojhan: I really don't know what to say. We explained the technical reasons for this multiple times and yet you always repeat that there are no technical reasons. Yes, it's not great, but I don't think 5 instead of 3 text field types are such a huge problem, especially when they now a) are all grouped together and b) in a way that matches the existing list and number field type pattern.
This also does not conflict in anyway with improving field UI, it will not be any harder (nor easier) after this.
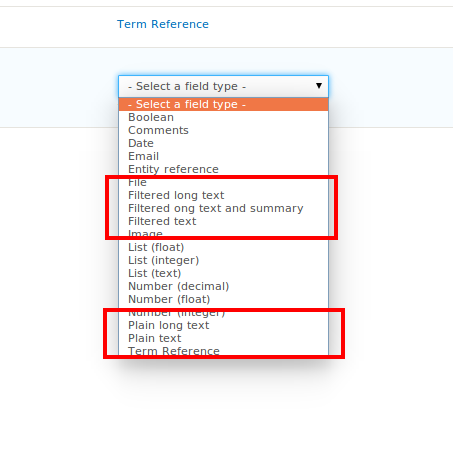
To repeat what we are changing, here are updated screenshots:
Before:

(Note that it is not just Text but also "Long text" and "Long text with summary". We're really just adding Text (plain) and Text (plain, long) to the list.
After:

Comment #79
berdirUpdated issue summary.
Comment #80
wim leersInterdiff looks great, all concerns have been addressed AFAICT, so back to RTBC!
Comment #81
Bojhan commented@Berdir From my understanding, it is a preference to have the raw/formatted decision up-front and not in the field setting wizzard step. This because the way Field UI is constructed, you make this fundamental decision upfront and it cannot be changed/made when configuring the field type. From my point of view, is this architectural decision plain wrong. Users should be able to choose the generic "type" upfront like Text, Image, Number etc. and specify specific data settings in the next step (field settings), after which the field is created and people go and configure the form element display/rules. This is the form builder UI model, which I think maps much more closely what site builders think - as Acquia verified in 2011 (usability testing of their form builder model). The decision here moves, another step away - from having a sensible UI in place.
My concerns have not been addressed, and I am pretty sure this will just go in as is :)
Comment #82
wim leers#81: It doesn't move us further away, it merely prevents a security problem and re-inforces the current model. I think it's rather trivial to still create the UI you're describing, possibly in Drupal 8.1.0: just add a "human_field_type" annotation to Field plugins, that will allow you to categorize all of the "textual" fields under "Text", which will allow you to choose a "human field type" (text, image, video and whatever other categories) as a first step and then in the second step only see those fields that are annotated with that human field type. Easy :)
Comment #83
alexpottI agree with @Bojhan there are UI concerns - but otoh we should all be concerned about the Field UI. Hopefully in 8.1 we can do something like what @Wim Leers suggests in #82 - anyone care to open an issue?
Committed 57926bf and pushed to 8.0.x. Thanks!
Comment #85
andypostFiled #2340305: add a "human_field_type" annotation to Field plugins
Comment #86
yched commentedRelated : #2344979: Rename field type list_text to list_string