 Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.
Come together with the global Drupal community in Rotterdam, 28 Sept – 1 Oct 2026. Sessions, contribution, connection, and Early Bird savings until 8 June.XC WordNet
The XC WordNet module integrates the Wordnet linguistic database into XC Drupal Toolkit.
The module has two parts. The first is to import Wordnet database into Apache Solr, and the second is the Drupal part.
Part 1: setting up the Solr index
We provided a a Java class (inside the XC module: xc_wordnet/resources/WordnetSyns2Solr.java), which transforms the Wordnet's Prolog files into an Apache Solr consumable XML file. This class is a rewriten version of Syns2Syms class available at https://gist.github.com/562776, and authored by Christopher Bradford (https://github.com/bradfordcp).
It converts the prolog files wn_s.pl, wn_sk.pl, and wn_g.pl, from the WordNet prolog download into an XML file which consumable with Apache Solr.
This has been tested with WordNet 3.0.
The structure of the resulted Solr documents is the following:
<doc>
<field name="id">100001740</field>
<field name="gloss_t">that which is perceived or known or inferred to have its own distinct existence (living or nonliving)</field>
<field name="lexfile_s">03</field>
<field name="lexdict_s">noun.Tops</field>
<field name="word_t">entity</field>
<field name="word_s">entity</field>
</doc>
The fields:
-
id: the synset identifier
gloss_t: the glossary (the meaning of the word group)
lexfile_s: the number of lexfile
lexdict: the machine name of the lexfile
word_t: the word(s) belonging to this group indexable as text
word_s: the word(s) belonging to this group indexable as phrase
Usage:
- compile the Java class:
javac WordnetSyns2Solr.javaThis step requires Java JDK.
- download WordNet prolog from http://wordnetcode.princeton.edu/3.0/WNprolog-3.0.tar.gz:
wget http://wordnetcode.princeton.edu/3.0/WNprolog-3.0.tar.gz - extract it:
tar -xvzf WNprolog-3.0.tar.gz - convert prolog to XML with:
java WordnetSyns2Solr [prolog directory] [output file]for example:
java WordnetSyns2Solr prolog wordnet.xml - update it to Solr. Be careful, that you do not put the WordNet index to any existing Apache Solr index. You can use a multicore Solr setup, or run multiple Solr instances on different ports.
curl [Solr URL] --data-binary @[output file] -H "Content-type: application/xml"for example
curl http://localhost:8983/solr/wordnet/update --data-binary @wordnet.xml -H "Content-type: application/xml" - commit:
curl http://localhost:8983/solr/wordnet/update --data-binary '<commit/>' -H "Content-type: application/xml" - optimize:
curl http://localhost:8983/solr/wordnet/update --data-binary '<optimize/>' -H "Content-type: application/xml" - http://drupal.org/files/issues/wordnet-color.png
- http://drupal.org/files/issues/wordnet-color-all.png
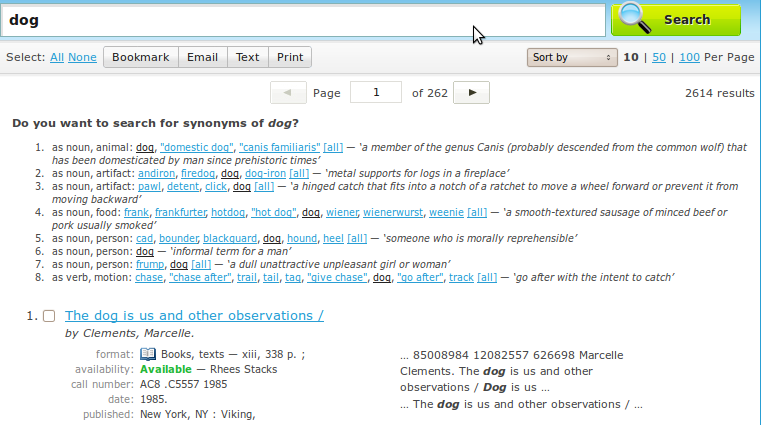
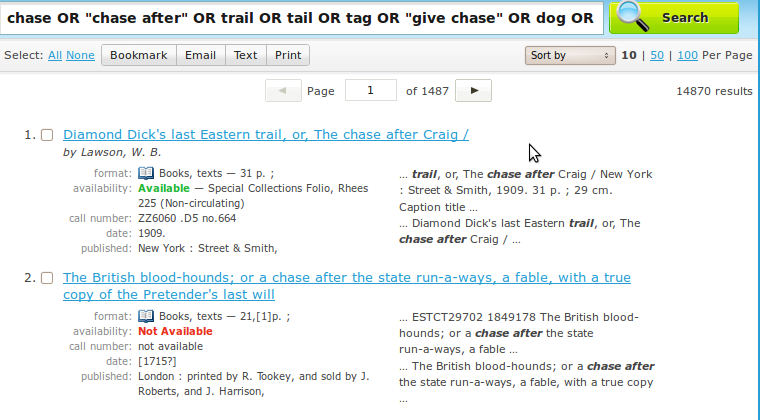
- http://drupal.org/files/issues/wordnet-dog.png
- http://drupal.org/files/issues/wordnet-dog-applied.png
Part 2: setting Drupal and using
You have to redister the Solr instance for the Wordnet index. Go to Administer > eXtensible Catalog (XC) > Wordnet integration > Database Settings (admin/xc/wordnet/settings)
You will see a page like this screenshot: http://drupal.org/files/issues/wordnet-admin.png.
Here are some screenshot from the working of the module:
References:
Help improve this page
You can:
- Log in, click Edit, and edit this page
- Log in, click Discuss, update the Page status value, and suggest an improvement
- Log in and create a Documentation issue with your suggestion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}