On this page
Indexing RDF data and providing a SPARQL endpoint
While Drupal and RDF Extensions can export each individual entities as RDF, they don't offer a facility to collect the RDF data of all entities in one place. For example, the RDF output of a node might reference other nodes or users of the site, but there is no data about these resources in the RDF of the first node. Having all the RDF data available in one place enables querying of graph data, possibly combined with third party data from the LOD cloud.
Triple stores are the best candidates for indexing this data since they are optimized for storing and querying large amounts of RDF data (they are also called RDF stores). Many different RDF stores exist, each with their own pros/cons, some are open source, some are optimized for large datasets, some support clustering. Wikipedia has a good list of Triple stores. Note that Drupal only support ARC2 for now, but it is possible to write plugins to support other stores (contact me if you are interested).
Triplestore setup
You first have to make sure you have a triple store ready to receive RDF data. Drupal currently only supports the ARC2 store which can run in the same database as the Drupal site. It is handy for prototyping and lightweight datasets and does not require to set up a separate server.
- Install the ARC2 store module which requires the ARC2 library.
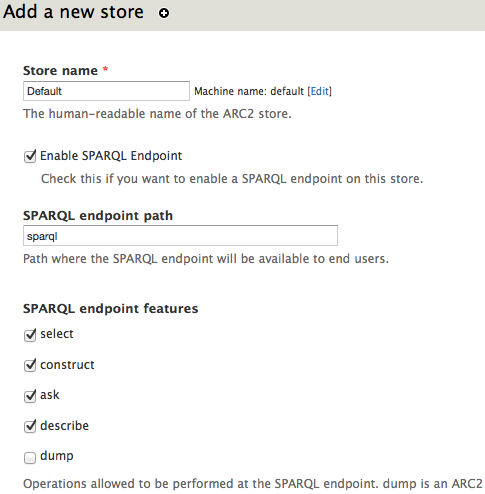
- Browse to Configuration > Web Services > ARC2 store settings and click on "Add".
- Fill in a name for your store (for example 'default') and specify the URI at which you want a SPARQL endpoint to be published, typically 'sparql'. Most of the other settings are fine to leave as default.
Indexing RDF data
Once you have your triplestore ready to receive RDF data, you need to set up Drupal to send its RDF data to your store. The RDF Indexer module for developed to manage the indexing of Drupal entities into any triplestore, and relies on the popular Search API module to set up each indexer.
- Install RDF Indexer and Search API
- Browse to Configuration » Search and metadata » Search API and click on "Add server"
- Enter a name for your server (e.g. RDF indexing server) and choose the "RDF Indexer service" as service class.
- A list of available store should appear below, choose the store you just created above, and click save.
- Go back to the Search API page, and this time click on create an index. In Search API, indexes are in charge of tracking a set of entities and keep them indexed in the particular server they are connected to.
- Give a name to the new index (e.g. "Node RDF index") and choose the entity type this index will take care of. Select also the server you just created above.
- On the fields page, just hit the save button. Fields are not used by the RDF Indexer module, so they can be left unselected.
- The workflow page allows you to fine tune your index:
- Bundle filter allows you to choose which content types (or bundles) you want to index. This is useful for example if you only want to index nodes of a particular type.
- Public entities is useful if your site contains private nodes that you don't want to be indexed in your RDF store. Only the nodes accessible to the public (anonymous user) will be indexed
Once your RDF indexer server and index are ready, you can start indexing content by going to the "Status" tab of your index, and click "Index now". The indexing will also happen on cron run, so make sure you have Cron running often enough (every 5 or 10mins). This will make sure that as entities get created or updated, your RDF index will be kept up to date.
Help improve this page
You can:
- Log in, click Edit, and edit this page
- Log in, click Discuss, update the Page status value, and suggest an improvement
- Log in and create a Documentation issue with your suggestion
