Problem/Motivation
crell felt that performance testing was necessary to in order to evaluate the effects of adding the new Drupal kernel. XHProf has been used by numerous users to run performance testing, get stats and numbers on function calls, etc.
Early in the issue, the question arises "can we swallow a 6-12% performance regression cost on the expectation that macro-level improvements later plus the DX, flexibility, and testability benefits will be worth it?"
Since the kernel has been adopted, and introduced this performance regression, this issue finishes with a discussion on what can be done on the micro-level in related features to regain some lost performance.
Proposed resolution
Continue investigation and pursue micro-optimizations. The most mentioned candidates include the Event Dispatcher and Auto Loader. A new broader issue was opened regarding this and other performance regressions: #1744302: [meta] Resolve known performance regressions in Drupal 8.
Remaining tasks
It looks as though this issue was left open by catch for informational purposes (#45).
#1744302: [meta] Resolve known performance regressions in Drupal 8
#1759306: Many unecessary calls to t() for strings that are never shown anywhere
Original report by crell
Per catch's request, we should run some performance analysis of the kernel branch to make sure we're not shooting ourselves in the foot too badly. :-) Some performance regression is acceptable at this stage, provided that it's something we have a plan to address in future work. We should also see if there's any quick-wins we can get performance-wise before the patch goes in.
I would suggest looking at the basics:
/node (with a bunch of nodes)
node/1
/user
The changes in the kernel patch are primarily in the late bootstrap / page dispatch process, so I think they should be fairly consistent across different types of pages. Data can of course prove me wrong in that expectation.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
msonnabaum commentedI'll try to do this sometime this week.
Comment #2
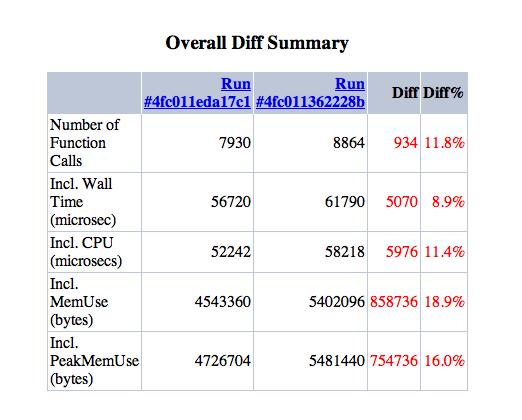
msonnabaum commentedI tested the latest 8.x and kernel branches with the standard profile, after creating 500 nodes and 500 users. The xhprof screenshot and attached files are from the default front page, viewed by anonymous user, page cache off, xdebug disabled.
I'm consistently seeing a 1400-1700 function call and 900k-1M memory usage increase with the kernel branch.
About 594 calls to strpos, 83 calls to substr, and 75 calls to str_replace can be attributed to the autoloader, which we can assume will go away either with the APC loader or some type of static loader.
It gets a bit complex after that since the code paths change so drastically. I'm posting the initial results here so that hopefully someone who knows the kernel branch better can take a look before I get the chance to dig further.
One thing that stood out to me was calls to SimpleXML::Construct, but only on the kernel branch. Most seem to come from config loading in Drupal\Core\Cache\DatabaseBackend::prepareItem and Drupal\Core\Cache\DatabaseBackend::garbageCollection. I have no idea why those calls are specific to kernel, so someone should probably look into that.
Comment #3
msonnabaum commentedHere's the same thing with a fresh site, no content at all.
Comment #4
msonnabaum commentedAlso, no xml config loading on either of those tests.
Comment #5
effulgentsia commentedFYI: I'm working on some additional benchmarks that I expect to post here later today.
Comment #6
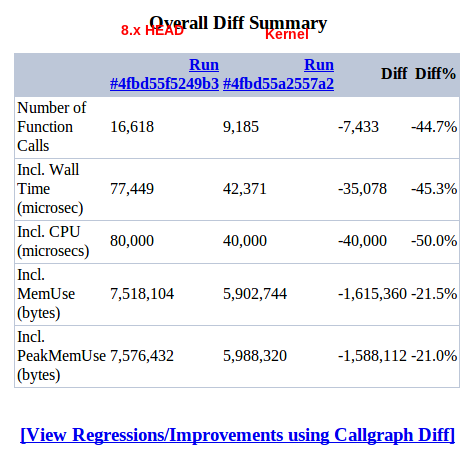
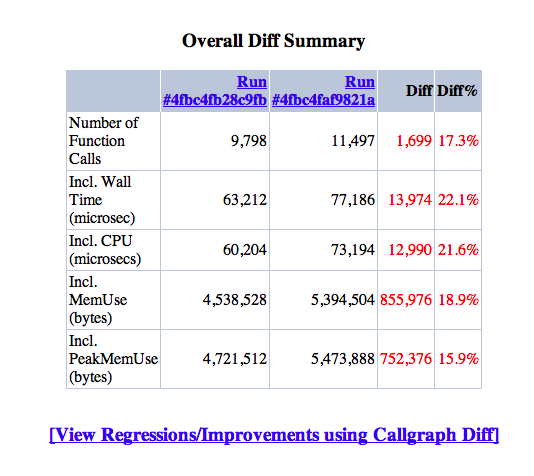
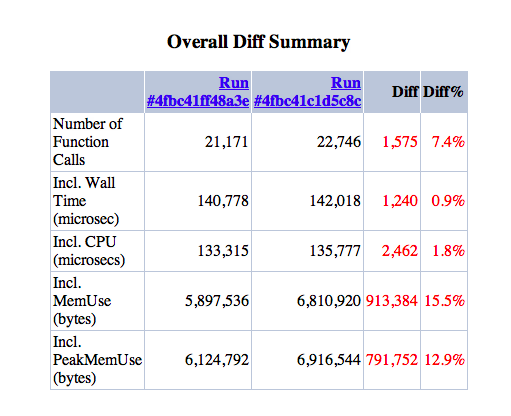
fgmHere is the result for a clean site after #1470824: XML encoder can only handle a small subset of PHP arrays, so switch to YAML got in, on anon home.
Comment #7
quicksketch@fgm: Could you include both before and after in your post? It's tough to compare without the difference.
Comment #8
fgmHere is the kernelized version on the same conditions: anon home page on just install site with standard profile.
Comment #9
fgmAnd here's the diff. I must say the result is quite unexpected, so it will be better to have other measurements.

Comment #10
msonnabaum commentedBe sure to reload a few times with each until the times are steady. It looks like you just had caches primed for kernel there. That gap is far too wide.
Comment #11
effulgentsia commentedIntro
I discussed this with msonnabaum, and there's basically 3 factors causing performance regression:
1) More code is loaded, because the kernel branch adds a lot of new code, but does not yet remove legacy Drupal code (like menu_execute_active_handler(), everything having to do with delivery callbacks, etc.). Specifically, 42 new classes (some Drupal, some Symfony) are loaded for every request. I haven't counted the total number of lines that those classes comprise. Will we be able to shave a comparable number of lines of legacy code? I don't know, but we certainly won't be able to shave a comparable number of files, and I don't know whether the time it takes for PHP to run a "require" scales with lines of code, or whether each file adds its own significant overhead. Presumably "require" statements are reasonably fast with APC enabled. More on that later.
2) The 42 classes above aren't just added via "require", but have to be found by the autoloader. The current autoloader is very inefficient in this regard, because there's an extra search location for every enabled module, so the autoloader runs a strpos() for every class * every module. Per #2, this accounts for some of the extra function calls seen in the XHProf profiles, and this can be solved with a static autoloader, or even simply with a more efficient iteration strategy.
3) Class loading aside,
$kernel->handle()simply results in a lot of function calls (which are much costlier in PHP than just about any other language) as compared to the highly optimized menu_execute_active_handler() it's replacing. That's partly the cost of a more robust and feature-rich architecture, and partly a result of Drupal having been around longer than Symfony2, and therefore, having benefited from more micro-optimization. It might not be possible to micro-optimize Symfony the way we're used to micro-optimizing Drupal, because increasingly, developers are solving performance and scalability issues with Varnish and ESI rather than with squeezing every drop out of PHP. Something to consider in evaluating the below numbers.Analysis
Ok, so what's the total kernel performance regression, and how much do each of the above contribute to it? To answer this, I posted 4 patches to #1486960-104: Testing testbot.
The first is just HEAD.
The second is HEAD plus loading the 42 class files without an autoloader (isolates factor 1).
The third is HEAD plus loading the 42 class files with the autoloader, but still running menu_execute_active_handler() rather than $kernel->handle() (isolates factor 2).
The fourth is the full kernel patch in #1463656-159: Add a Drupal kernel; leverage HttpFoundation and HttpKernel (the time difference between the previous patch and this one isolates factor 3).
I ran these 4 scenarios on a fresh D8 install, standard profile, no content, APC enabled, XDebug disabled, Drupal page cache off. I then ran "ab -c1 -n100" (Apache benchmark, no concurrency, averaging times over 100 requests) to measure the time of the default front page (which has a very fast page callback that just queries the {node} table, finds 0 nodes, and returns "No front page content has been created yet.") served to an anonymous user. I ran each batch of 100 3 times, discarding the first (as cache priming), and ensuring the second two agreed to within 0.1ms.
Here's the results:
HEAD: 34.6ms
HEAD + static class loading: 35.8ms (+3.5% relative to HEAD)
HEAD + class loading via autoloader: 36.8ms (+3% relative to static class loading)
Full kernel: 38.9ms (+6% relative to just loading class files but not instantiating or using the classes)
Total regression: 12.5%
Note the relatively large percentages are partially due to a small denominator, since we're testing a page with no primary content other than a message saying there's no content. However, even when I ran this on a front page showing 10 simple node teasers, the denominator only went up to 58.4ms, while the absolute differences stayed the same (as one would expect), pushing the total regression percentage down to 7.5%: better, but still fairly significant.
Since the performance regression was initially observed by slower testbot runs, I was curious if a comparable difference would show up in that, which is why I posted #1486960-104: Testing testbot, but the variance in unrelated conditions was too large to draw any conclusions.
Summary
We usually scrutinize pretty carefully any patch that introduces a >1% performance regression, and here, we have a >10% one, with some of that recoverable with autoloader optimization, some recoverable by removing legacy code made obsolete, but a pretty sizable chunk potentially impossible to recover. But, I think the cost is worth it if it leads to better ESI and block caching support, as well as its other non-performance benefits.
Comment #12
neclimdulI think the last sentence of Eff's summary is key, we've committed to this approach and the broader scaling options it gives us. We've also only taken the first step in this process and keeping backward compatibility and largely the same code paths means we're sort of running 2 routing systems in parallel which is sort of impressively light when you think about it. Hopefully we can scale down the performance hit as we phase out the routing parts of menu.inc and replace them with features more inline with symfony's approach and the WSSCI and SCOTCH needs in follow ups.
I'm curious if the same performance cost is seen on cached vs uncached or if the net cost is about the same. My guess would be yes since the Symfony code is just sort of a static framework atm, not really fully utilized or integrated.
This is a really great gut check on what WSCCI's at with regards to performance regressions and where to be looking especially eff's novel breakdown. Thanks a lot guys and keep up the good work!
Comment #13
Crell commentedExcellent analysis, Alex, thank you!
I overall agree with the conclusion. This is an architectural change, using a series of libraries that are not optimized for disk IO and stack count. Drupal traditionally has heavily optimized for those factors, often at the expense of DX, flexibility, testability, etc.
WSCCI, by contrast, is trying to emphasize architectural changes for flexibility, modularity, and testability (all things that the involved Symfony components are good at). It's not targeting micro-performance, but aims (in later work) to enable macro-level performance improvements. So micro-level performance regressions are to be expected.
So the question is whether the micro-level regressions here are too big to swallow temporarily while we work on the macro-level improvements. I would put that cost at 6%, not 12%, to exclude the class loading parts; those are costs that we are going to bear no matter what the kernel does, and improving that is an entirely separate but achievable issue: #1241190: Possible approaches to bootstrap/front loading of classes
So the question is, can we swallow a 6% micro-optimization cost on the expectation that macro-level improvements later plus the DX, flexibility, and testability benefits will be worth it?
I know we have done so in the past. (DBTNG's initial patch was about ~5%.) I am comfortable doing so here.
(Note: This presumes that none of that 6% is a bug where we're needlessly doing something 50 times when we only need 1; if anyone finds one of those, let's fix it on the spot, of course.)
Comment #14
sunI can swallow that if we make a full DI conversion, total bootstrap revamp, and lastly, total conversion of the current router system including all related/affected parts (being touched by the kernel patch) a hard requirement for Drupal 8.
What I mean is "feature freeze" to its full extent. And. Full extent means that the code freeze and release is deferred until all of the above has happened. Without sloppy exceptions.
That is, because I expect the negative impact to significantly decrease after a full conversion. Without full conversion, we'd only be introducing tons of new code and yet another half-baked thing in core. At the huge cost of slowing down everything.
That said, the commitment to do HttpKernel exists and IMO is signed off already (give or take some code glitches that will be fixed before or after the fact). However, given these stats, that commitment needs to be extended to incorporate a full conversion of all of core prior to release. Otherwise, this trend will continue and Drupal will soon and inherently be perceived as the slowest contender on the CMS market.
Comment #15
quicksketchI think the question really is, are there really any macro-level improvements to be had at all for the 80% users. We all understand that ESI can make sites faster if you've got Akamai or Varnish, but ultimately are we going to be able to deliver faster performance for the vast majority of our users? Saying the Drupal is going to become a "RESTful service provider" is going to be impossible if Drupal is slower than it is today. Already 9/10 times I wouldn't use Drupal for REST services anyway, at least in a dynamic fashion with lots of customized content (though I might use Symfony without Drupal, hahah).
Comment #16
quicksketchI dare say it already is. :P
We need a performance trade off of some kind, I'm tired of the newest latest and greatest abstraction layer slowing it down again.
Comment #17
Crell commentedsun: Agreed, we need to not be half-assed about things. I consider the elimination of the old router to be a hard requirement for not saying that WSCCI was unsuccessful. I also would love a full-on DI revamp, bootstrap gutting, etc. I've been pushing for that for a while. :-) It's certainly what I am driving toward now. Whether we hit all of it by 1 December is primarily a resourcing question at this point, which is, as always, impossible to predict.
quicksketch: One of the advantages of HttpKernel is that it includes a PHP-space reverse proxy, which means that (if all goes according to plan) 100% of users will be doing partial page caching for authenticated users. There's tons of details to work out there yet, but yes, this is not something that should benefit only the "1%". :-)
Comment #18
cosmicdreams commentedIf someone could itemize the steps it would take to complete a full-on DI revamp, I will set out to complete each and every step.
Comment #19
sunIt would be beneficial to redo those benchmarks/profiling to see the actual picture.
With this in settings.php:
For that to work, you need to additionally apply attached patch.
(see #1597888: Cache NullBackend is entirely broken, does not implement CacheBackendInterface for core)
Comment #20
quicksketchYeah I read up on that, which means that PHP itself is doing subrequests via ESI? Does that mean multiple bootstraps? Even if the page were partially cached, doing even 2 bootstraps (1 cached and 1 dynamic) could be slower than 1 bootstrap entirely uncached. It seems to me that PHP-based ESI really just makes for a useful development tool locally, while you put the "real" reverse proxy (Varnish/Akamai) in place on your production server.
Comment #21
neclimdulYes/No, the idea would be to use the DI Container for more bootstrap functionality and pass it through. Things that could be shared between requests(like a db connection) would not be rebuilt and things that rebuilt on the request scope would be dynamically bootstrapped as needed.
The real reverse proxy would obviously perform better much like varnish is better at page caching then our database layer but the cost will hopefully be limited. It could also have cool side effects like maybe Pressflow engineering a PHP ESI layer that runs in parallel. I know David has always wanted to render blocks in parallel. :)
Comment #22
effulgentsia commentedNot as I understand it (which admittedly, might be incorrect). It would all be happening in 1 PHP request, so things like loading include files and classes would only need to happen once, regardless of how many subrequests. Same for other initialization code that's platform-dependent rather than request-dependent. However, request-dependent initialization (basically any "service object" added to the DI container that's flagged as having "request" scope), would need to be rerun for each subrequest. I don't think we know yet how much overhead this will entail in practice. But, if the 6% overhead of
$kernel->handle()itself needs to be incurred for every subrequest, that could present a problem: I don't know yet how much of that overhead can be reduced for subrequests.Comment #23
Crell commentedCorrect, the PHP HttpCache is single-process. How much of that overhead would be repeated for every subrequest I have no idea; there's lots of variables there. Ideally with caching of each subrequest (that's the point) we would bypass most of it, but how much I don't know. Also, I believe we should make it possible to call a sub-controller directly, not through a full routing, for cases where we don't want to bother caching it separately. (Eg, it seems silly to make 15 subrequests for 15 field blocks on a single page, but there may be cause to do a subrequest for ONE of them.)
It would actually be Varnish that has multiple bootstraps, since it has to issue multiple calls back to the server on separate URLs. :-) That's where the nominally separate work to reduce bootstrap weight through DI, PSR-0, etc. should be beneficial.
Comment #24
effulgentsia commentedI did that, and get basically the same 4ms difference between HEAD and full kernel branch, but over a higher denominator (89ms -> 93ms instead of 35ms -> 39ms), pushing the percentage down from 12.5% to 4.5%. But I don't know what that really tells us, since no prod site will run with Cache\NullBackend. Perhaps it paints a closer picture to a highly dynamic or very low traffic website where there's a lot more {cache} misses.
Comment #25
effulgentsia commentedAlso, since a lot of Drupal sites run on shared hosts without APC, here's the no-APC results:
Without
$conf['cache_classes']['cache'] = 'Drupal\Core\Cache\NullBackend';:HEAD: 135ms
HEAD + static class loading: 146ms
HEAD + class loading via autoloader: 147ms
Full kernel: 149ms
In other words, same absolute 1ms difference for autoloader search overhead, and 2ms difference for $kernel->handle() overhead excluding class loading. But a smaller percentage given the larger denominator. However, an 11ms (8%) addition just for loading the 42 classes (an unknown amount of this will be recovered when we delete the legacy code made obsolete by all this new code).
With
$conf['cache_classes']['cache'] = 'Drupal\Core\Cache\NullBackend';:Same 11+1+2ms differences, but with a baseline of 205ms instead of 135ms.
Note: all of my benchmarks are on a MacBook Pro. If anyone wants to run these benchmarks on Linux and/or server-grade hardware, please do.
Comment #26
catchShame this is in the sandbox issue queue, I've only just seen this issue after Crell mentioned via e-mail there was "an issue linked from the kernel patch", which it turns out was a one-line reference by webchick four days ago. This is the kind of review that does no harm in the issue itelf.
So this is a much bigger regression than I noticed in my 10 minutes of profiling, although I did pick up the autoloader is a mess at the moment at least, thanks Alex and Mark for properly taking a look at this!
Given the findings:
- I don't mind the patch being committed with a regression at this point, especially given most of it is "loading extra classes" which we've already committed to a long time ago regardless of specifics.
- once it's committed, let's move this issue to the core queue, and mark it at least major, to continue investigation and see if there's PHP optimizations we can make up-stream or in how the autoloader is wired up, and it will be useful as background when converting more things too.
- I'm absolutely not prepared for Drupal 8 to be released and be even more of a performance suck than Drupal 7 was, so I think we should have an extra, critical task, to ensure that the regressions we're knowingly introducing here are balanced out prior to release - whether that's via PHP optimizations down the line from removing legacy code (which frankly I doubt is going to make it up at all, although there's some documented regressions in Drupal 7 we could yet fix that might), or much, much better authenticated HTML caching).
@Alex in #24, I think it means there's a consistent performance degradation that's only in the bootstrap code, and does not affect code that's run on cache misses (which is generally rebuilding various info hook registries, variables etc. so that makes sense).
Comment #27
msonnabaum commentedWe really shouldnt focus on the autoloader. There are many options to reduce the overhead there, and it's really unrelated to this issue as we're only noticing it because we have more classes. Here's a new diff using the APC autoloader which helps isolate the regression a bit more.
A lot of the remaining function call increase is coming from the ParameterBag stuff, but it's not that expensive overall. They are using array_key_exists() instead of isset(), but who knows, maybe array_key_exists() doesn't suck in php 5.4.
The real overhead that's added looks like it's in the EventDispatcher. We've got multiple subscribers to the kernel request event. I'm not sure if it's a mistake that they are both called (LegacyRequestSubscriber and ViewSubscriber), but that's adding some time. Here's a breakdown of the code path that I think illustrates the difference:
before:
menu_execute_active_handler | 34.23ms
drupal_deliver_page | 28.82ms
drupal_deliver_html_page | 28.77ms
after:
Symfony\Component\HttpKernel\HttpKernel::handle | 38.74ms
Symfony\Component\HttpKernel\HttpKernel::handleRaw | 38.73ms
Symfony\Component\EventDispatcher\EventDispatcher::dispatch | 34.46ms
Symfony\Component\EventDispatcher\EventDispatcher::doDispatch | 34.25ms
Drupal\Core\EventSubscriber\ViewSubscriber::onView | 27.34ms
Drupal\Core\EventSubscriber\ViewSubscriber::onHtml | 27.01ms
I'm with catch in wanting to take a more critical look at this later on. There might be a couple areas we could fix up now, but it'd be a premature optimization. I'd rather get this in and revisit it once it's matured a bit.
Comment #28
Crell commentedI'm fine with moving this to the core queue post-merge. I also agree that we shouldn't sweat specific micro-optimizations right now, since so much of the architecture is still changing. Things we optimize now may end up being no biggie later on and vice versa. Still, it's good to know where the likely optimization points are going to be (autoloader and event dispatcher being the two obvious targets here).
fabpot already indicated in #1509164-59: Use Symfony EventDispatcher for hook system that he's very open to optimizations to the EventDispatcher library, and I'm all in favor of us spending time to make that faster. It can only help all involved.
Comment #29
pounardJust want to put a small parenthesis:
Both of these are different, isset() will test both the key existence and value not being null, while array_key_exists() just test the key existence. array_key_exists() is not being used instead of isset() but is used because it's the right function to use in this case.
This is not revelant to the issue, but I don't like to let live this kind of false statement that could mess up people mind and lead them to write wrong code.
Comment #30
pounard@msonnabaum Good catch with EventDispatcher, and I guess more listeners will come in the future once the API will be pushed and stable, this is something we may want to use wisely.
@Crell About the LegacyRequestSubscriber, is it going to disappear once the kernel will be in core and new menu routing will be figured out?
EDIT: @msonnabaum Is the EventDispatcher which is being slow, or what the listener actually do in there?Oh the ViewSubscriber seems to be vilain here?Comment #31
Crell commentedYes, any Legacy* class is intended as a BC shiv that will go away eventually. I believe in this case it's stuff from the bootstrap process that we needed to move later than the kernel got started, and that was the simplest way to do so for now.
I don't think ViewSubscriber is a villain per se. It's only one more function call than what we do now, I think. Rather, the EventDispatcher process is slower than the current delivery callback lookup mechanism. That's something we can/should/will address upstream in Symfony.
Comment #32
pounardThe event EventDispatcher bringing a 10% regression does not really seem probable to me, except if there is a real bug in it. I'd like to ask msonnabaum on what page(s) did it made his figures? Because I'm quite sure those 10-15% would be a lot less on complex pages.
Comment #33
msonnabaum commentedI hesitate to respond to this, but yeah, I know. I wasn't making a false statement. I know what both those functions do and I assumed the Symfony folks are using array_key_exists because it doesn't check the value, since isset is usually faster.
Let's just assume that we're all smart people and that nitpicking this stuff in issues is not necessary.
Comment #34
pounardSorry if you took it wrong, I did not meant to question your knowledge, I just think that this kind of statement may confuse people that don't know PHP this well, that is all. Sorry again if it was interpreted otherwise.
Comment #35
catchIf the value is usually set, then isset() || array_key_exists() should end up faster, since you can still correctly check for NULL values, but you can avoid the function call altogether in the majority of cases.
Whether it actually is or not depends on usage though, since you could also end up checking both isset() and array_key_exists() every time, which would be slower than just an array_key_exists(). So it's entirely valid to bring the relative performance of each up, since while they do different things, they can also be used in tandem if the specific code in question is well understood.
Comment #36
catchComment #37
sunComment #38
berdirOk, not sure if this is the right issue, but here are a few things that I noticed:
- t() is called a lot. That is nothing new. What's new is that t() now calls language() all the time which then gets the language mapper, which then gets the actual language, which is quite a bit slower than global $language was before. language() does have static caching, but it looks like it's only used when the language manager does not exist.
- In overall, the calls to the DIC really sum up, see the attached callgraph.
- The autoloader is a big hit, but from what I understand, that can be improved using APC specific code and hardcoded mappings as it's pluggable, right?
Comment #39
pounardYou're right for the autoloader APC tied with a stat=0 option and a map-based autoloader in front of all others will give us great performances. it's not something we should worry about. The more we will put stuff into the DIC, the less we will access them because they will be lazy loaded. In the end, by switching everything to OOP and DIC/Kernel we probably end up with more classes, but less loaded during one single hit (I guessing here, but it seems logical).
And there is way to many t() calls in Drupal everywhere, those should be reduced everywhere (most of them never end up being displayed).
Comment #40
Crell commentedBerdir, the attached callgraph is not attached. :-)
Comment #41
berdirThe attached callgraph is now attached :)
Comment #42
chx commentedthis will change quite a lot the moment we compile the DIC
Comment #43
effulgentsia commentedCan you open a separate issue with some examples, and link to it from here? Thanks.
Comment #44
berdirHere we go: #1759306: Many unecessary calls to t() for strings that are never shown anywhere. Not sure what exactly the purpose of that issue is and how to title/classify it.
Comment #45
catchBumping this down to major since we have #1744302: [meta] Resolve known performance regressions in Drupal 8 as a meta issue. But there's some good data in here so shame to close it.
Comment #46
yesct commentedthis could use an update to the issue summary, and an outline of next steps to move this forward. (it's a major so effecting thresholds)
Comment #46.0
dan_rogersAdded issue summary, drupalcon PDX code sprint.
Comment #47
ZenDoodles commentedI pinged Catch on irc, and he agreed it would be okay to close this issue. We aren't using this ticket to track profiling anymore, and the broader issue is being addressed in the meta now. All this interesting data will still be available even when the issue is closed. For lack of a better state, I'm calling it a duplicate (of #1744302: [meta] Resolve known performance regressions in Drupal 8)