Now that we have a decent (and growing) pile of tests for update module, I wanted to turn my attention to a few really tricky things that are going to require a fair bit of code refactoring:
#238950: Meta: update.module RAM consumption
#361563: Update Notifications causes SQL Server to go away
Basically, how it works now is we generate a list of all modules and themes on the site, and group them by project. In a tight loop, we generate the URL to fetch update data for each project, try to fetch the XML, and append it to a growing array of XML strings. Then, as soon as that loop is over, we iterate over our (now potentially gigantic) array of XML strings, parse them, and generate another giant array of parsed data about releases for each project. Then, we serialize the whole thing, write it to the DB, and return the array. Fun, huh? ;)
Aside from being performance problems, or bugs that just cause fatal errors (if you have a sufficiently large # of enabled modules and overflow the max packet size MySQL can handle when passing around these giant serialized arrays), the refactoring we'd do to fix those two issues will allow us to write some more sane tests which are actually unit tests, not just functional tests of the entire stack.
While I was looking into the code that would need to change, I had a flash of inspiration: we should just use the Queue API for this. Here's a rough outline of how it would all work:
- Fetching available update data for each project should be a separate task in the queue.
- Each queue task involves attempting to fetch the available update data, parsing it, throwing out all the irrelevant data (e.g. releases older than what we currently have installed), and stashing only the data we care about for a single project into its own cache entry in the {cache_update} table.
- The "Check manually" link would invalidate the cache, add new tasks to fetch data for all projects to the queue, and perhaps send you to a BatchAPI progress bar page while it drains the queue.
- When cron thinks it's time to fetch new data, it'll also queue up new fetch tasks for each project, and then try to drain the queue.
We could even record in {cache_update} that we've got a pending fetch task to regenerate the data for a project. So, when you view the available updates report, it could even show you which projects are current, and which ones we're still trying to refresh the data for. In other words, we wouldn't always have to flush the existing data, we could just mark it as stale, and show that.
In general, the available update data for a given project has no bearing on the update status of other projects. The only exception is #456088: Sub-themes not notified of security updates for base themes. So, that's the one case where we'd have to be slightly careful. Otherwise, the order in which we fetch data is completely irrelevant, and really everything would be better if we were handling each project as a totally separate, stand-alone entity, instead of trying to do everything at once all the time.
Not only is this another perfect use for the Queue API, it would solve a lot of the performance and resource problems people continue to report with update status. Plus, it'd give us a sane way to throttle how often we attempt to fetch data (since it all wouldn't be rolled into a single, monolithic "fetch stuff" function).
I'm going to try to get confirmation from Dries and/or webchick on this proposal before I start coding it, since if it's going to be rejected for D7, I've got other more urgent work to do. But, if this would be accepted for D7, I think it'll solve a *lot* of our problems.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
dave reidOMG yes. Perfect application for the new Queue API, but we'll see if we can get an exception for D7.
Comment #2
catchThis is a critical performance bug and any API changes will only affect a couple of things (plugin.php, probably upgrade_status) - which are all going to suffer from the issue anyway, so changing status accordingly.
Comment #3
dwwI haven't been able to get an answer from the core committers about this approach, but time's running short, so I might as well give this a go. I'll be working on this today, time permitting...
Comment #4
dwwSummary of the patch
- The available update data for each project is now a separate entry in {cache_update}, with the cid "available_releases::[project_shortname]". If that cache entry is missing for a project, or stale (meaning either the .info file is newer than when we fetched the data, or our configured interval has elapsed), we create a new fetch task for this project.
- We use the Queue API to manage all the fetch tasks. However, we also keep a record in {cache_update} about the pending tasks, so that we don't queue up multiple requests to fetch the same project while we're waiting to drain the queue. These use a cid of the form "fetch_task::[project_shortname]".
- The "Check manually" link invalidates all the available release data, queues new fetch tasks for every project, and initiates a Batch API progress bar to drain the queue.
- Cron invalidates all the available release data and directly drains the queue if the interval has elapsed. Otherwise, it just sees if any individual projects are stale and tries to drain any pending projects.
- There's a configurable max time ('update_max_fetch_time', no UI, defaults to 5 seconds) to try to fetch data if we're not on the batch progress bar page.
- All of the code and available update report can now handle it just fine if we have partial data.
- We now cache data about which URLs we failed to fetch data from for up to 5 minutes. So, if a given server is down, and we've tried to fetch from it over 'update_max_fetch_attempts' times, we just ignore that server for the next 5 minutes and all fetch tasks immediately fail. This functionality already existed from #243253: Update status module can cause white screen if the check for updates takes too long, but it currently just saves this info in a static array, so it's lost on each page load (which obviously won't work with Queue API and Batch API). And, I figured a 5 minute "cooling off period" was a good idea, anyway. I could trivially make this another non-UI setting if desired.
- update_parse_xml() now just takes a single XML string, parses it, and returns that data. Previously, it assumed an array of XML strings, and returning an array of parsed data.
- Since we're now dealing with a couple of project_shortname-based cache IDs in {cache_update}, and sometimes we need to grab all of them at once, added _update_get_cache_multiple(). Similarly, added $wildcard support to _update_cache_clear().
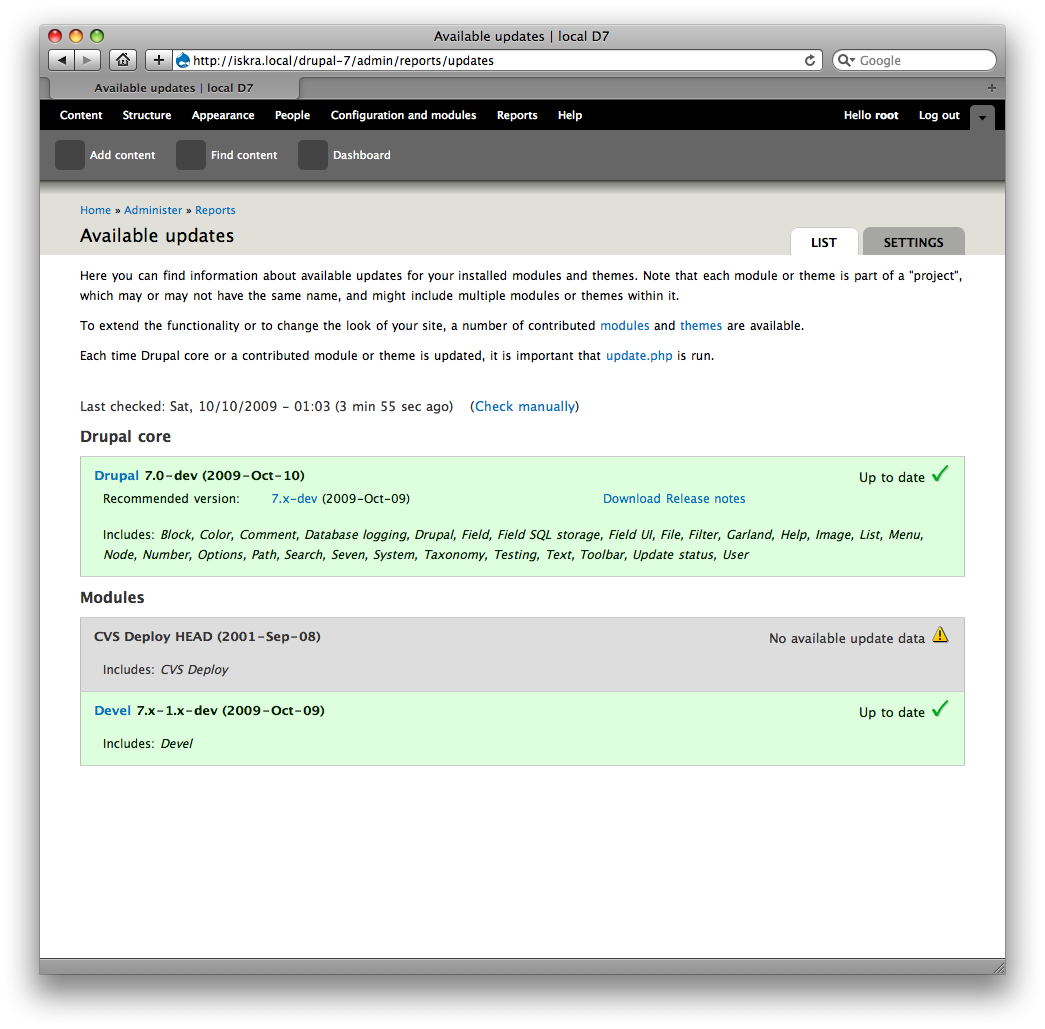
- On the available update report itself, we treat "waiting to re-fetch data" visually the same as "failed to fetch" or "couldn't find any releases" -- the row is grey, the icon is "warning", but the text label is clear this is a different case.
TODO
A) I just left a @todo comment in the code at the right place to purge a bunch of the available release data we don't actually need to store that points to #238950: Meta: update.module RAM consumption. I'd rather handle that part in a followup patch, to prevent this monster from growing any larger than necessary. That's not even going to change any APIs or anything, it's just going to reduce the size of the arrays we're trying to store in {cache_update}, so that can basically happen anytime before the 7.0 release.
B) To completely solve #361563: Update Notifications causes SQL Server to go away (and significantly help #238950: Meta: update.module RAM consumption) we should also revisit the fact that we stash the available release data directly into the array of project data which we cache. This is evil and wrong, but I don't want to completely untangle that in this issue, either.
C) All the existing tests pass, but there aren't new tests for some of the edge cases that are touched in here. There are still large swaths of update status that don't have tests, but I'm a little worried about adding a bunch more, since these are expensive tests as currently written. :(
D) Currently, the batch callback only does a single fetch task per batch step. We could probably do N fetch tasks per batch step. I'm not sure what N should be, if it should be a non-UI setting, etc.
I don't think any of these are inherently blockers for committing this, but I wanted to enumerate them anyway.
Explanation of the screenshots
Thanks,
-Derek
p.s. Tagging for the D7 API clean-up...
Comment #5
berdirMinor thing, arrays with more than one entry should be on a separate line, like
I know, it's an edge case if you have only two (and even short) entries, but that's the CS....
Will look at the patch later...
Beer-o-mania starts in -39 days! Don't drink and patch.
Comment #6
dwwFixed Berdir's concern. ;)
Comment #7
dwwRe: the batch page using the wrong theme, see #539022-20: Batch API should use the current theme to run the batches.
Bojhan reviewed the screenies in IRC, and decided he didn't like the word "fetch". It's already in the UI in a few places, but this patch touches basically all of them, so we might as well change it here. Generally, "check" is fine. However, I didn't like using "Failed to check available update data...", since we succeeded in checking, we just failed to get an answer. ;) So, in failure cases, we're now using "Failed to get available update data...".
New patch with these UI changes, and new screenies to demonstrate.
Comment #8
Bojhan commentedI think this is a good change, it made the whole interface language more consistent and we where able to make more user friendly.
Comment #9
dwwA few more minor improvements to the code:
- Added a big comment explaining why we need to set $context['finished'] to 1 if the queue is empty. (See #600836: Batch API never terminates if you set $context['finished'] > 1 for more).
- In update_get_available(), if we're missing any release data for a given project, generate a fetch task for that, too. Previously, we only marked it that it needed to fetch if there was no data for the project at all, or if the data was stale. In this case, there's a little data, but no release data. This happens, for example, to projects that failed to contact their release history server.
Comment #10
dwwThis "fixes" TODO #4.D: we now do a little loop and try to drain upto 5 fetch tasks in each batch step.
Here's an utterly non-scientific benchmark, but some datapoints nonetheless... ;) I added another basic update status test with all 5 contrib projects enabled, just to try to slow things down a little more... With that test included, on my laptop, running all the update tests took:
No patch: 51 seconds
Patch #9: 50 seconds
Patch #10: 48 seconds
So, it seems on the surface that this is an improvement. Better benchmarks would be welcome, especially on a real site connecting to d.o (not the local filesystem) and as many contribs as possible.
Comment #11
sunThis looks very nice.
This block could use short comment that gives a quick clue about what/when triggers it.
Inject spaces before and after = and < here, please.
Why is this unconditionally deleting items? The batch processor does, too, but only in case of success.
As a non-native speaker, I have issues to understand what exactly "drain" means there... process, clean, flush, or perhaps empty?
Seems like this only runs once for initialization. A short comment would help to grok that and what is actually being retrieved from cache here.
Usually we do subject_verb(), so _update_queue_initialize(). I see that most other functions in here are equally reversed, but it's never too late to start adhering to common patterns. :)
Since you touch these lines anyway, it would be nice to squeeze one or more short comments in here that give some clues about what's happening (or supposed to be happening) - because, this code looks kinda funky ;)
It would be nice if there was a short comment before each if statement that does not necessarily repeat the conditions in human-readable words, but provides some reasoning.
Two of them seem to have such comments, but inside of the condition.
This review is powered by Dreditor.
Comment #12
chx commentedYou should create your queue in .install. Cron run createqueue all the time because it deals with dynamically named queues (and it does not have an install anyways). Now the whole function becomes unnecessary. What I do not get is why you do not use the cron queues mechanism here? Yeah, the batch API needs to do its own stuff but this looks like a nice opportunity to use the new API. To make the batch API reuse the cron code, factor the main loop starting with
$function = $info['worker callback'];out to a separate function in common.inc and just call that (drupal_queue_run or somesuch). If it bears some resemblance to the suggested _update_fetch_data then do not be surprised :)Re sun, Attempt to drain looks ok to me.
Comment #13
dwwThanks for the reviews, folks! This fixes most of sun's concerns.
This block could use short comment that gives a quick clue about what/when triggers it.
Done.
Inject spaces before and after = and < here, please.
Done.
Why is this unconditionally deleting items? The batch processor does, too, but only in case of success.
The batch processor also unconditionally deletes. Because once we tried to fetch, even if it failed, the queue task is now complete. If we didn't delete it, we'd just keep getting the same task over and over again when we try calling claimItem(). The only reason we fail is if we couldn't get XML, or the XML is invalid. Either way, we should mark the task of attempting to fetch over and move on. We'll create new fetch tasks later when needed.
As a non-native speaker, I have issues to understand what exactly "drain" means there... process, clean, flush, or perhaps empty?
That's life in the world of queue processing. "Draining a queue" is nearly universal terminology in that wing of computer science. If we have a Queue API, you're just going to have to live with comments that use queue-esque phrases. ;) chx seems to agree...
A short comment would help to grok that and what is actually being retrieved from cache here.
Done.
Usually we do subject_verb(), so _update_queue_initialize().
Didn't touch it yet, pending discussion with chx about using the cron queue for this, and if not, creating the queue at install time.
Since you touch these lines anyway, it would be nice to squeeze one or more short comments...
No thanks. ;)
require_once('kittens.inc')Feel free to open a new minor task for this, and I'll work on it post 10/15 (hell, post 11/15 for that matter).It would be nice if there was a short comment before each if statement that does not necessarily repeat the conditions in human-readable words, but provides some reasoning.
Done. While I was at it, I reorganized the code a bit to be I hope more clear and remove a wee bit of duplication.
I'll try to track down chx in IRC right now about comment #12, stay tuned.
Comment #14
dww_update_initialize_queue() is now gone, and I'm just creating/destroying the queue at install/upgrade time, which is really the intention of how Queue API should work. Not exactly sure what I was thinking in the middle of last night when I wrote that. ;)
However, I'm not so keen on trying to use the cron queue API for this for a few reasons:
- This isn't always about cron. Yes, we want to try to drain the queue via cron, but it's also about interactive stuff. I think it's cleaner to just have a stand-alone queue for this, and various paths to drain that queue (including, but not limited to, cron).
- As it stands, this patch is only about 30 minutes away from a D6 backport. We're already keeping track of our own fetch queue items in {cache_update} -- we could actually just use that as our own DB-driven queue in D6. If we port all this over to the cron queue API, it makes it even harder to backport to D6.
So, I think this is a fully viable D7 patch at this point...
Comment #16
dwwTee hee, except that. ;)
Comment #17
dww... and now with a test to ensure that the case demonstrated by http://drupal.org/files/issues/597484-7.update_queue_api.failed-to-get.png actually happens as we expect. We have core and 3 contribs, one of them with a bogus fetch URL: we assert the message that we failed to fetch for a project, assert the message that it checked the status for 3 projects, that nothing is actually marked as missing an update, etc.
While I was at it, I realized that the other tests cases were needlessly re-fetching admin/reports/updates. refreshUpdateStatus() was already fetching admin/reports/updates/check with redirects you to admin/reports/updates, anyway, and I ensured that $this->content was ending up with the final page content, not the intermediary content. This will also let us add assertions about the messages generated when checking manually, if we want.
Comment #18
dwwWhoops, the refactoring of update_get_available() wasn't so good, and it broke something about our admin/* warning messages from hook_requirements(), leading to weird messages at admin/config/modules when you save that page and have no available update data. This patch fixes the bug, stay tuned for tests for this case...
Comment #19
dwwNow with 3 new test cases to ensure that the update status messages at admin/config/module are sane in the 3 different cases of core (up to date, missing regular update, missing security update).
Comment #20
dwwDave Reid pointed out (and I can confirm locally) that the DB update was failing. Looks like we need to manually include system.queue.inc in there. New patch.
Comment #21
sunThis is great. The new comments made me understand what's going on, and more importantly, why.
Comment #22
dave reidThis isn't quite working as it should. I have admin_menu, devel, and coder checked out from their HEAD (7.x branches) and using update.module with cvs_deploy it tells me that they are up to date and all good. When I apply the patch, it says those versions are unsupported and in red. So this isn't the fault of cvs_deploy and something regressed here. It also tells me that I have an update available for admin_menu when I am using the latest checkout from that CVS as well.
Everything else is working awesome. Using batch and queue api for this application is perfect and should really help with processing a project at a time and keeping memory usage lower. I'd love to be able to do some informational benchmarks to see if that is in fact true.
Comment #23
dwwDave Reid: this patch breaks cvs_deploy. I have it patched locally. ;). Try without cvs_deploy for now. We can open a seperate issue for cvs_deploy and i'll upload the patch later when I get home. ;). Back to RTBC.
Comment #24
dave reiddww: Yeah it's working fine without cvs_deploy. *whew!* Everything looks very well put together and dww has done a terrific job with this. I'm buying him a beer at next DrupalCon.
Comment #25
dries commentedHave we validated that this patch meets the initial goal (e.g. reduce memory consumption)? Given that the queue system tries to execute as many queued tasks as possible in one pass, we might not be saving a ton of memory usage.
I might be wrong, but it looks like the queue system helps with problems that are CPU-bound and that might otherwise timeout, but that it might not be that helpful for problems that are memory bound ...
Comment #26
webchickThis still needs review. Please post with before/after benchmarks regarding memory usage.
Comment #27
dww- Fetching update data is network bound, which obviously might timeout. We've had lots of reports of people having problems with this, especially when d.o is down.
- I expect some minor RAM savings, but not massive with this patch. I explained all this in comment #4, points (A) and (B) in the "TODO" section. Please (re)read those -- no sense re-typing them, here.
- If you'd *really* prefer, I can roll this into an even more massive patch that also tries to do all possible changes to solve #238950 and #361563, but I'd rather get this done in more manageable, smaller pieces. Think of the kittens. I was hoping for an initial patch that makes life better and lays the basis to fix the bugs in the other issue in smaller, more sane patches. Not in the distant future, like Monday and Tuesday, but if this is stalled, that strategy isn't going to work.
- It's hard to provide convincing benchmarks for this issue since there aren't D7 projects with tons of releases yet to test with. The memory differences are going to look tiny if you've got a relatively small # of projects, each with a small # of releases. If you want, I can add some enormous release history files to the updates/tests directory, but that seems like a shame to bloat every core download from d.o just for testing this. :(
So, now what? ;) I see webchick in IRC right now, maybe I can get a quick agreement on a strategy here...
Comment #28
webchickI would say make a massive .xml file, post benchmarks before/after using it, but with the understanding that it's for benchmarking only, not for committing to core. Seems like this could be a handy thing to have around as we continue to optimize update.module.
Comment #29
dwwI have no idea if this testing methodology is at all accurate. :( devel module's performance logging stuff is currently fubar in D7, and I don't have a good profiling setup on my laptop. :/ I really need to change that...
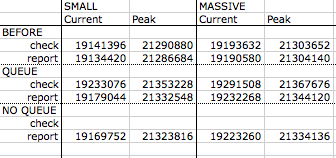
Here's a patch (I'm hiding it via .txt so the bot doesn't try to mess with this monster) that adds a bunch of new projects and release XML files for a UpdateTestContribMassiveCase. I grabbed real XML data from a few of the projects on d.o that have the most D6 releases and perl'ed them as if they were D7, instead. I also copied them with dummy names to get more projects (e.g. photos vs. photoz). It also adds a UpdateTestCoreSmallCase test case. Both call the following after trying to fetch available updates data:
debug(memory_get_usage());
debug(memory_get_peak_usage());
So, we have 2 different test cases (massive vs. small), which memory value (current vs. peak), and before/after. All these numbers also include all of simpletest, so who knows how much that's effecting the outcome. Unsurprisingly, the patch (with the plugable Queue API, Batch API, etc) is a little worse than without the patch. So, I quickly rewrote the code to not use Queue API at all, but just use our records in {cache_update} to track the fetch tasks as our queue (like I'm planning to do for the D6 backport, if that's going to fly), so, there's also a "NO QUEUE" set of numbers.
Finally, to attempt to isolate Batch API from the rest of this, I ran everything twice, once with the test fetching data by directly visiting the report (which triggers a fetch for up to 5 seconds) vs. having the test fetch via the check manually page. The no Queue API hack doesn't have numbers for the Batch API option, since I didn't finish hacking that code yet, and I don't want to spend any more time on this until I have a clearer sense of what should happen next...
Attached are a patch for the test, the hacked version of #20 that doesn't actually use Queue API that I used for the "NO QUEUE" numbers, and a .png of the spreadsheet where I was recording all this as I ran it...
Here are the numbers (selected the region in the spreadsheet and pasted here) as poorly formatted text, too... ;)
Comment #30
dww@Dries, re: "Given that the queue system tries to execute as many queued tasks as possible in one pass, we might not be saving a ton of memory usage."
That's not how the Queue API works. There's no "tries to execute as many queued tasks as possible in one pass" in Queue API. It's up to you when/how to drain the queue. The current implementation in this patch is that we try to drain as much as possible in 5 seconds, or we drain up to 5 tasks per batch if you're doing the interactive progress bar thingy. However, we could tweak any of these values to tune it in various ways to optimize for various desired outcomes.
BTW, re: the "massive" test. It's still relatively tiny (only 10 contribs). We should really get up to at least 75 projects, each with dozens of releases, to see how this is going to need to behave in the real world once D7 is in real use... Maybe I should write a script to generate these test cases. :/
Comment #31
chx commentedI do not really get what's the problem with the patch. It does clean up a lot of ugly code, it lays groundwork for the memory problem we are long struggling with and could not solve. It's good to go in.
Derek gave a lot of good followups in the issue very clearly describing what's done and why. Please read before not committing this again. Thanks.
Comment #32
dwwFYI: Fixing cvs_deploy once this lands is at #601310: Make compatible with the Queue-based Update module (#597484). There's a patch there now if anyone wants/needs to test this patch using cvs_deploy.
Comment #33
dries commented@chx, what was the point of "Please read before not committing this again"? We asked for benchmarks to make sure the patch achieves the outlined goals, specifically #238950: Meta: update.module RAM consumption. dww provided benchmark results (thanks!) and everything looks good. I don't see why that should make you grumpy. Did _you_ read the issue? :P
I'll try to give this another review today!
Comment #34
dww@Dries: just to be clear, this patch does not achieve the goal of reducing RAM resource consumption. It enables doing so over at #238950: Meta: update.module RAM consumption, which is the point I'm trying to make in comment #4, the detailed summary of the patch, as per http://webchick.net/patch-reviewers-are-not-clairvoyant. The title of this issue remains "Use Queue API to fetch available update data", which is a good idea in its own right for UX reasons (e.g. actually having a progress bar when you check manually, instead of a blank page that can hang for many seconds), and will make it possible to fix the other bugs without 100K patches.
Thanks,
-Derek
p.s. This issue isn't itself fixing a bug, it's an API cleanup + UX task, but it's blocking progress on fixing other bugs. I appreciate the concern expressed by catch in #3, but I think it's more accurate to move this issue back to a 'task' as I originally posted it.
Comment #35
dries commentedAlright, spent another 45 minutes with this patch and decided to commit it to CVS HEAD. I think it is the right thing to do for UX.