
Problem/Motivation
Serialized data often contains identifiers, which can sometimes be used to retrieve more data from across the Web. However, different formats and profiles use different kinds of identifiers and different data structures to hold the identifiers.
Additionally, for some use cases a format/profile might use more than one identifier scheme. For example, a JSON-LD version of a node using a Drupal-specific profile might contain both a UUID and a URI.
When importing entity references, we need to be able to resolve external identifiers to the internal identifiers we use in the EntityReferenceItem. Additionally, we would like the architecture to make it possible to dereference entities that don't yet exist on the consuming site.
It would be best if code could be reused across different formats. For example, a URI dereference plugin should work the same across different XML and JSON formats.
Proposed resolution
Introduce an EntityResolverInterface with one method, resolve($normalizer, $data, $target_entity_type). Any module that wants to provide a new way to handle identifiers would create a resolver and register it with the container. For example, to resolve UUIDs, there would be a UuidResolver. When resolve is called, it would check whether entity_load_by_uuid returns anything, and if it does would return the internal ID. If the Resolver couldn't find a matching internal ID but knows how to dereference the entity, it could return a dereferencer object.
EntityReferenceNormalizers should have the main EntityResolver injected (using setter injection). The main EntityResolver would use a chain-of-command pattern to determine which of the registered Resolvers to use, running through each until something returned.
Each Resolver should define an interface which Normalizers can implement to indicate that they support that kind of resolution. For example, a JSON-LD Normalizer might only support the UriReferenceInterface, or it might also support the UuidReferenceInterface.
| Comment | File | Size | Author |
|---|---|---|---|
| #108 | 1880424-108-entity-reference-import.patch | 27.27 KB | effulgentsia |
| #108 | interdiff.txt | 712 bytes | effulgentsia |
| #106 | 1880424-106-entity-reference-import.patch | 27.35 KB | effulgentsia |
| #102 | 1880424-102-entity-reference-import.patch | 27.43 KB | effulgentsia |
| #102 | interdiff.txt | 5.48 KB | effulgentsia |









{kind=link}
Comments
Comment #1
Anonymous (not verified) CreditAttribution: Anonymous commentedForgot WSCCI tag
Comment #2
klausi@id should be deserialized to a usual entity reference field. REST module should just store that reference, it should not validate it nor should it retrieve the referenced entity.
I don't think we want to determine anything on the reference, the caller/client has to make sure that the referenced entity is already there. The entity validation API could determine If the referenced entity does not exist and throw an error in that case (see also #1696648: [META] Untie content entity validation from form validation).
Do we require UUIDs for entity references? I need to look up how entity references work in D8.
Comment #3
Anonymous (not verified) CreditAttribution: Anonymous commentedHow would @id deserialize into a usual entity reference field? Entity reference references by internal ID, and the importing system doesn't know which internal ID corresponds to the URI.
Comment #4
Crell CreditAttribution: Crell commentedWe discussed this on today's REST call. Here's the readers' digest:
In REST speak, URIs are the GUID. In Drupal speak, UUIDs should be the GUID. REST module should favor REST speak, so URIs. However, we also can provide UUIDs as an assist to allow processing code to convert to "SameAs", an RDF/JsonLD property that means "I have a different URI, but I'm really just a copy of X". (Think of it as the more abstracted rel="canonical".)
Client-initiated (pull) vs. Server-initiated (push) content replication: We need to allow for both, as both have valid use cases.
Any entity with an Entity Reference field on it needs to be addressed. That is all nodes (taxonomy and users), so this is a required feature to handle in at least some fashion. However, core doesn't have to provide the ideal solution, just a solution that can be enhanced via contrib in a sane way.
JSON-LD allows for inlining of referenced resources in place of their ID. We're... not sure how to deal with that yet. However, the only problem with every resource/entity being its own request, even when syndicating a large number of objects, is performance via lots of HTTP requests. For now, we don't deal with that.
Our proposed plan, therefore, is:
- Add a "REST Reference" field type (based on Link or ER or both). This field type references another entity by URI, not by UUID or entity ID. It probably looks like a stripped down Link field, and may subclass from either Link or ER. (While our use for this field type is internal only, I don't think there's any reason we shouldn't expose it to the user as a worthwhile field unto itself.)
- The Deserializer gives us an Entity object, but with REST Reference fields on it in place of anything with a URI reference, vis, all ER fields are replaced with REST Reference fields.
- We write a "Deferencer" service that, in core, replaces REST Reference fields with ERs if the target is known, and with an empty ER if not.
- REST module uses Dereferencer on PUT.
- The Dereferencer service is, however, entirely decoupled from the rest of REST module so it can be used by other client code (REST clients, syndication clients, Feeds module, Deploy, etc.) , too.
- Contrib can replace the Dereferencer with one that is more powerful/flexible/configurable/awesome.
- This fancier Contrib-based Dereferencer should use a pluggable strategy approach, so that fields can be configured per-instance how they should be translated. Likely options are: Discard if we don't already have a local copy of the referenced resource; fetch the referenced resource with another GET, save it, then reference it (this would be recursive); Replace a non-local URI with a default value (such as setting all users to some default import user when they're pulled in). There may be others. That's why it's pluggable/configurable.
The nested GET approach would replace Deploy module's current tree-building approach, which all happens sender-side, not client-side. Circular references would be handled by detecting a circular reference and bailing, as Deploy does now, because we don't want to deal with that. Alternatively, a really fancy dereferencer strategy could do a "save A, save B, save A again" approach if it felt like it. Again, yay pluggable.
Possible pitfalls:
- Will the "put on the wrong field and then replace it before saving" logic break Entity API?
- Will the client-side dependency recursion asplode?
Needs feedback from domain experts in the above areas.
Comment #5
Anonymous (not verified) CreditAttribution: Anonymous commentedSince our discussion, I'm starting to think that we can't use sameAs.
The use case I'm thinking is this: what if someone is creating a mashup page from multiple datasources? Let's say they have a page about California. They could pull some fields from the Geonames dataset and others from Wikidata. With the architecture we're talking about, this kind of mashup would be possible. The page would have two "sameAs" URIs, http://sws.geonames.org/5332921 and http://wikidata.org/wiki/Q99. It would map one field to a Geonames RDF property and another field to a Wikidata RDF property.
In this case it would be safe enough to use sameAs. However, naive site builders generally don't model things well, so they might be using the same functionality to add in fields about Michael Jackson or some other related thing. In this case, sameAs is not the proper relationship.
Do we want to explicitly disallow this mashup style functionality? If we want to allow it, we have to accomodate for multiple identifying URIs. We could mint our own property for this, e.g. importsFrom.
Comment #6
Anonymous (not verified) CreditAttribution: Anonymous commentedAlso, a more important issue:
In our discussion, we talked about embedding entity references to a variable depth (e.g. 3 levels).
It isn't clear to what extent JSON-LD's processing algorithm will support embedding referenced entities when using the advanced features that we plan to use (property generators & annotations). The processing algorithm still isn't complete and the implementations have bugs which make it very hard to determine. Also, it would be really easy to DoS a site by using deep embedding and property generation together.
Comment #7
Crell CreditAttribution: Crell commentedMitigating the complexity of variable depth, that's something we only need to support for GET requests, and therefore it's something that should be entirely cache-safe. So as long as you have a proper HTTP cache active you shouldn't be able to DDOS Drupal, just your cache. :-) (Even if your cache is in-PHP via HttpCache.) We can also set a system-wide maximum legal depth, which we probably want to do anyway.
Comment #8
Anonymous (not verified) CreditAttribution: Anonymous commentedThe DoS potential is when someone is POSTing or PUTing. For us, it will only be an issue if we switch to using a JSON-LD library to deserialize. Basically, if you expand JSON-LD from its compact form to its expanded form, and you're also using property generators to map multiple RDF properties to the same term, then everything in the subtree of that term will be copied once for each RDF property. We don't currently use a JSON-LD library to deserialize because none were even close to ready when we started committing. I'm not entirely convinced that we will want to switch to one in the future either.
I think this isn't an issue if we use graphs. I give an example of the "@graph" keyword at work in the property URI section of my intro to JSON-LD features. The problem with using @graph is that it's difficult to traverse. We could use it for the content deployment case, IMHO, since we have a defined use case and I would almost certainly be personally involved in development. However, if people outside this little circle try to develop with @graphs, I foresee a lot of wailing and gnashing of teeth. It would be a reasonable approach if JSON-LD consumer libraries provided accessor methods, but the possibility of that reaching REC isn't on the table anymore for JSON-LD 1.0.
As we talked about in IRC, we may want to consider not permitting embedded entity references in JSON-LD. If someone needs embedded entity references, perhaps they can just use JSON (and we can build embed support in there).
Comment #9
gddUltimately I think the Dereferencer plan sounds sane. I don't have a lot of insight into the implications for Entity API though. Will client-side dependency recursion asplode? Sure but that's the nature of the beast. I think that should be on the client to solve, not us.
I also had a discussion on IRC with crell about the option of inlining referenced entities. I personally am not a fan of this. If someone wants to inline data, they can plug in their own module to do it. When and how to choose to inline data is very very use-case specific, and I'd rather we just not deal with it at all than choose an arbitrary level of nesting with no specific reason in mind. Crell was saying its unlikely this is going to happen anwyays, I just wanted to encourage that train of thought :)
Comment #10
Crell CreditAttribution: Crell commentedWell the primary "client" is probably Feeds module, so we can't punt that question entirely... :-)
I don't think anyone suggested an arbitrary nesting level to always use. Rather, the consideration was to allow the client to specify a recursion level in the URL.
Comment #11
gddWell, you also suggested hardcoding a max which makes it arbitrary.
Comment #12
Crell CreditAttribution: Crell commentedAs a cap to keep someone from doing /node/5?depth=50000, sure. But for well-behaved clients whether they do ?depth=2 or ?depth=4 should be up to them.
Comment #13
Anonymous (not verified) CreditAttribution: Anonymous commentedI gathered from reading the backscroll of the IRC conversation yesterday that everyone is comfortable with leaving the inlining question to contrib (or another serialization). Is that correct?
Comment #14
effulgentsia CreditAttribution: effulgentsia commentedI'm ok with leaving inlining to contrib. Even if someone wants to make an argument for it being in core, I think it can be a follow up rather than bogging down the scope of this issue.
Comment #15
Crell CreditAttribution: Crell commentedWhat @effulgentsia said.
Comment #16
gddConcur
Comment #17
dixon_Sorry for coming in a bit late in the game here. I have been busy with other things lately™.
Anyhow, here's my ¢2:
The approach with a Dereference service sounds clean and good. Unfortunately I haven't been involved in the IRC discussions lately, but I assume there's still a lot of things to figure out with that service. One things I come to think about;
How we map between REST Reference fields and Entity Reference fields for the core implementation of that Dereference service? On import we need to know what ER fields we should put in-place of a particular REST reference field. The same goes for export I guess, just the other way around.
On the inline thing; I'm not a huge fan of that either.
Comment #18
fagoIf in-lining is out-of-scope for this issue, what is it's main scope then? Dealing with circular dependencies?
Entity-API does not suppport the concept of stub-entities any more. Either it's an entity or not, but of course you can come up with an entity-like data structure meanwhile.
hm, exchanging field types on the fly won't work. It's either an ER field or a REST reference field, but not both. Maybe, we could have an interim data structure which are not entities that look different and then in a second iteration make them real entities?
But, is it really necessary to have the REST reference field. Couldn't we just skipping the value and associate an interim REST reference object with it, which holds everything needed until the value can be set? We could just write to $entity->er_field->rest_data ?
Comment #19
Anonymous (not verified) CreditAttribution: Anonymous commentedThe main scope is to make it possible to import entity reference fields. The current suggestion is to make the handling of entity reference import swappable, so that a site can decide how it wants to handle entity reference import on a field by field basis.
We currently believe there would be three strategies that could be used to dereference:
Since in-lining is out of scope, the default would be to use GET on the @id to retrieve any more information. But we need to find a way to get the @id to REST module.
EDIT: sorry, early morning posting makes for poor comment writing. edited for clarity's sake :)
Comment #20
effulgentsia CreditAttribution: effulgentsia commented@fago: can you elaborate on this? With EntityNG/TypedData API, what's the proper way for rest.module to define an additional property on the EntityReferenceItem type? And to make sure this additional property isn't itself persisted to storage or serialized.
Comment #21
Anonymous (not verified) CreditAttribution: Anonymous commentedHere is an extremely crude attempt to do what fago suggests. It adds a rest_import_uri property to EntityReferenceItems (which will be changed to a more general rest_data if we go this route).
I would like to focus discussion on 1) whether I understood fago's suggestion correctly, and 2) what the right way to add properties to properties is (or will be) now that hook_entity_property_info_alter is gone. What I've done in the patch (hacking the EntityReferenceItem object) is pretty clearly not the right way.
Comment #23
fagoAs I understand it, the Rest-import URI is just needed during import.
Thus, what I was referring to is setting arbitrary, custom properties on the object without registering them at all. Such as we do set $entity->content - it's just interim state we throw on the object and remove once we are done.
Nope. Indeed introducing alter hooks at that level would be interesting.
Comment #24
Anonymous (not verified) CreditAttribution: Anonymous commentedIn thinking about this more, we might be able to remove this dependency on Entity Field API entirely.
I originally wanted to use the Entity Field API to pass information back to the REST module because I didn't think serializers should concern themselves with making requests, checking permissions, etc. Once Larry introduced the idea of the pluggable dereferencer service, it actually moved that work to the dereferencer. So the dereferencer would be in charge of running the request and determining access.
If all of this work happens in the dereferencer, we could simply use the dereferencer from inside JsonldEntityReferenceNormalizer::denormalize(), which would mean we don't have to worry about Entity Field API at all here. We would have to either pass in the appropriate dereferencer service to the normalizer, or we would have to pass in the field instance IDs so that it could determine which to use. This isn't possible with the Serializer we currently use, but might be possible with https://github.com/symfony/symfony/pull/6797 (which I still need to fully review).
The one problem here is that by dereferencing at this nested level, it potentially makes it more difficult to handle circular dependencies. It also would make it harder to handle data submitted as a @graph in JSON-LD (at least, if I'm thinking it through correctly), but I don't think we really planned to support that anyway.
Comment #25
Anonymous (not verified) CreditAttribution: Anonymous commentedJust the very basic start of adding a pluggable system, called "entity reference handler". I'm open to changing the name.
For now, I'm getting the entity reference handler from the container in JsonldEntityReferenceNormalizer::denormalize(). Instead, this would be passed in using the context. The JsonldEntityNormalizer would determine which handler to use based on the field and would add it to the context.
It also currently lives in the REST module. It may be it's own decoupled system eventually, but while we're just starting to build it up, I think it will make things a little easier to assume that REST is enabled.
Comment #27
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch includes #1894508: Update symfony/serializer.
The caller (in our case, REST module's RequestHandler::handle()) now passes in the entity reference handler plugin manager, which it obtains from the container.
Comment #28
klausiWell, we should only throw exceptions if we actually need the reference handler. If we do not encounter any entity reference fields then we don't need it.
And I'm not sure that $context is the right place to inject the reference handler. Can't we add the handler to the serializer service somehow? Or to the normalizers/denormalizer services?
Comment #29
Anonymous (not verified) CreditAttribution: Anonymous commentedWhat are our options for doing this? Here are the options I can see:
To me, option 1 seems the best option. Both 2 and 3 add complexity for developers who are creating new Normalizers.
Are any of these options preferable to having the caller pass in the manager?
Comment #30
Anonymous (not verified) CreditAttribution: Anonymous commentedHere's what it could look like if we extended Serializer.
If we go this route, we should introduce a serialization module. This would contain the entity reference handler plugin manager (which is currently in REST) and all of the things currently registered in CoreBundle.
Comment #32
Anonymous (not verified) CreditAttribution: Anonymous commentedHere's what it looks like with serialization as a module. I left the JSON and XML Normalizers and Encoders in the Drupal/Core path, I figure those should be moved as part of a separate issue since other issues are altering them. But eventually, those would also move to serialization module.
Comment #34
Anonymous (not verified) CreditAttribution: Anonymous commentedMerged in latest composer changes.
Comment #36
Anonymous (not verified) CreditAttribution: Anonymous commentedAh, I created a bug which appears when the service container is first being built. Fixed by moving some things from CoreBundle to SerializationBundle.
Comment #38
Anonymous (not verified) CreditAttribution: Anonymous commentedWe might not have to extend Serializer at all here.
If we are ok with using drupal_container() from inside a config entity, as EntityDisplay::getFormatter() does, then we can just retrieve the plugin manager from the container there.
Comment #39
Crell CreditAttribution: Crell commentedI am not OK with using drupal_container() inside a config entity. :-)
A config entity is a data object. It should not be doing anything other than being an object.
Comment #40
Anonymous (not verified) CreditAttribution: Anonymous commentedThat makes sense... anyways, here's what it would have looked like.
I have another idea that I'm going to try later tonight.
Comment #42
Anonymous (not verified) CreditAttribution: Anonymous commentedHere's what it looks like with setter injection, which feels much more like the right way to do this.
Comment #44
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch fixes the REST Create and Update tests to handle the entity reference.
Comment #46
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch puts in a temporary hack so that people can test it manually. It defaults the entity reference handler to 'configured_value' if none is set.
Comment #48
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch makes it possible to configure settings for the entity reference handler. For example, to specify which entity ID should be used for the configured_value handler.
Comment #49.0
(not verified) CreditAttribution: commentedUpdated proposed solution.
Comment #50
lanthaler CreditAttribution: lanthaler commentedI'm not sure I understand what you mean here but you can always add properties to a node object (
{ "@id": ...}). Neither property generators nor annotations prevent that.The algorithms are complete and at least my JSON-LD processor is up to date. Which bugs did you encounter?
Comment #51
Anonymous (not verified) CreditAttribution: Anonymous commentedI'm speaking specifically about whether round-tripping would be supported if you have deeply nested node definitions and were also using property generators. My uncertainty comes from the discussions in October, there was a lot of talk of flags and node references. Even if JSON-LD processors do round-trip in this case, I still don't know that we want to support it. By using both we exacerbate the data explosion problem that you pointed out early in the property generators discussion. It seems like (for Drupal) supporting deep embedding and property generators together makes it easy for naive devs to shoot themselves in the foot.
Either way, we have decided that we aren't supporting deep embedding in core anyway for other reasons, as outlined by heyrocker in #9, so we can defer the decision.
The algorithm wasn't complete when I posted that (for example, you updated the expansion algorithm a few days later). I emailed you about the "bug" I was referring to at that time... it turned out it wasn't a bug, it was the fact that you have to use the @id construct if you're using property generators, but not otherwise.
Comment #52
lanthaler CreditAttribution: lanthaler commentedYes, that's fully supported. We kept it as simple as possible and didn't introduce any flags. You can test everything in my JSON-LD playground.
That might be a problem, but if you need the data anyway, it doesn't really matter how you retrieve it. If you don't need it, don't include it or include just the relevant parts (e.g., just @id and the UUID).
Oh OK, I remember. Let me know if there are some missing features that would help you for your task - I would be happy to add them to my JSON-LD processor. As I understood it, you aren't using a JSON-LD but process the data directly, right?
Comment #53
Anonymous (not verified) CreditAttribution: Anonymous commentedThanks for the information about the algorithm, that will help inform the discussion if we decide to pursue embedding as an entity reference handler strategy in contrib.
Comment #54
Anonymous (not verified) CreditAttribution: Anonymous commentedJust a reminder to everyone that this still needs architectural review.
Comment #55
klausiI think this should use getInstance() instead of createInstance().
Why is this config entity needed?
Overall I cannot say much about the architecture. I think it is a good idea to start a serialization module, that separates the services better from the rest of core. They won't be needed on every Drupal site.
I just try to re-iterate what I see here: we need to de-reference entity references that come in as fields in the denormalizer. Usually we have references in an @id URI format, example: http://example.com/entity/node/554. We need to resolve that to nid 554. We think that references might look differently, e.g. a format could just contain UUIDs. Therefore we invent the entity dereference plugin system here, so that modules can provide their own strategy how to resolve references in their format.
I wonder if the dereference plugin system is really necessary. Why can't we assume that references always have to be represented as @id = http://example.com/entity/node/332 ? We could hard code that in our core implementation. If a contrib module wants to do it differently it simply creates its own denormalizer for references for its own format and be done with it?
Comment #56
Anonymous (not verified) CreditAttribution: Anonymous commentedThanks for the review and comments.
This pluggable system allows the user to choose how an entity reference field will be handled on an instance by instance basis.
For example, the user could configure the user_id field so that it never fetches data and simply sets the user_id to a preconfigured "Data import user". This wouldn't be possible with simple Normalizer manipulation... the Serializer caches which Normalizer to use based on the class and format passed in, e.g.
$this->normalizerCache['Drupal\Core\Entity\Field\Type\EntityReferenceItem']['jsonld']. Being able to only fetch the data for the fields that you really want to import will improve performance.It allows for code reuse across different formats. For example, if another RDF format (or even Microdata JSON) is implemented, that format could use the uri_dereference plugin.
It also moves the security considerations out of the Normalizer and into a separate system. For example, individual Normalizers wouldn't have to worry about whether account "foo" has content creation permissions for "Article" node types.
Comment #57
Anonymous (not verified) CreditAttribution: Anonymous commentedWe talked about this on the REST call today. Klaus said that he agreed with my reasoning from the last comment (except the security point), and Alex said that the code reuse seemed like a good reason to use a pluggable architecture. Alex plans to do an architecture review and Larry said he would review the use of plugins if he has time this week.
This should fix the tests.
Comment #59
effulgentsia CreditAttribution: effulgentsia commentedPer #57, I like the separation of dereferencer from normalizer, because I can definitely envision there being multiple formats/normalizers implemented throughout contrib that are all RESTful, and therefore work with URIs, and therefore require something to convert from URI to entity id. That something should be pluggable without requiring every individual normalizer to be overridden.
I also like the upgrade here of a $context array passed throughout the serialization pipeline, and injecting the dereferencer there.
However, I share klausi's concern that a plugin manager and config entity for configuring different dereferencers for different situations feels too heavy. Especially since a UI for configuring this should neither be a requirement for this issue, and potentially, shouldn't even be in core at all.
What if we go back to the suggestion in #4 to make the dereferencer just a simple service (no config entity, no plugins)? However, we make the getEntityId() method on that service take some parameters, like $referencing_entity (hopefully, there's a better name for this: what I mean by it is if we're deserializing $node, and it has a 'user_id' field, then this is the $node entity, not the $user entity), $format, and $field_name (or maybe more info about the field than just its name). That way, in core, we can ship with a simple service that just does one default implementation. However, contrib can swap this service out with something that can route to different plugins based on these arguments. That same contrib module could also provide a UI for managing those configurations. Or, if we decide such a plugin/config based system belongs in core, we can try to work it out in a separate issue from this one, using what's been done here already as a starting point.
Comment #60
Anonymous (not verified) CreditAttribution: Anonymous commentedIn the comment below, I use ER Handler where others use dereferencer. I think we want to allow for use cases (such as dropping the value or using a preconfigured value) which are not dereferencing.
If we don't have configuration for an ER Handler, then I believe we'd have to hardcode the ER handler to a format. For example, how would the URI dereferencer know that JSON-LD uses the @id key for the URI? We would either have to hardcode that, or the Normalizer would have to have knowledge that it might be passing data off to an ER Handler which requires a "uri" value. We could use a bridge pattern, but that seems more complicated than plugins with config to me.
Comment #61
Anonymous (not verified) CreditAttribution: Anonymous commented#57: 1880424-57-entity-reference-importer.patch queued for re-testing.
Comment #62
Anonymous (not verified) CreditAttribution: Anonymous commentedAlso, the idea of passing the full entity that we are dereferencing (the $referencing_entity Alex talks about) down into all the Normalizers concerns me. We may need to do it, but I would prefer to pass as little as possible in the $context.
Comment #64
effulgentsia CreditAttribution: effulgentsia commentedExcellent point. I missed where that fits into the architecture. Can the next patch include a test ER handler that uses @id?
From the issue summary:
First of all, I think targetEntityType is confusing, because in #1801304: Add Entity reference field, 'target' refers to the referenced entity, not the entity containing the ER field. I don't know if there's standard terminology for the "referencing entity". Perhaps here, though, simply 'entityType' would be sufficient.
Secondly, I'm concerned this organization is too granular. It means every ER field of every bundle requires explicit configuration (unless the global default is used), rather than, for example, having per-referencing-entity-type defaults, or per-target-entity-type defaults. Do we have some known, common use cases in mind, that we can use to evaluate the appropriate levels of granularity where defaults should be applied?
Meanwhile I also wonder if it's not granular enough. For a given entity type / bundle / format, do we need to support multiple mappings? For example, during deployment run 1, use node.article.drupal_jsonld.1.yml, and for deployment run 2, use node.article.drupal_jsonld.2.yml. Or, when syndicating from externalsite1.com, use a different configuration than when syndicating from externalsite2.com.
Comment #65
Anonymous (not verified) CreditAttribution: Anonymous commentedI'm attaching a first round implementation of URI dereference. It uses a 'uri_key' setting to determine what string it should use as the key for accessing data. This defaults to "uri", but in the serialization.entityreference settings file, it would be overriden to use "@id".
I'll address the granularity issue Alex brings up in my next comment, because I've had some of the same concerns.
Also, I just want to point out something now, though we don't have to discuss it yet:
We should not use this version of URI dereference. All it does is check UUID, it doesn't save data for any of the referenced entities. This is a worst case kind of implementation... it introduces the major deficiency of Linked Data approaches (latency) while not giving us any of the benefits. If we do not want to tackle the challenge of importing data from referenced entities in core, then I don't think that we should use dereferencing at all. Instead, we should just include UUIDs in the data and have a UUID entity reference handler. I would like to see us tackle URI dereference in core, but not if it is done in a way that negates its benefits.
Comment #66
Anonymous (not verified) CreditAttribution: Anonymous commentedAs far as the ER handler to choose, I think that the default should be based on format. For example, the default for JSON-LD might be URI dereference.
There is another kind of default which is tricker with this implementation. These are the format-specific settings for an ER handler. For example, when using JSON-LD and the URI dereferencer, the default for "uri_key" should be "@id". In the architecture that I'm talking about, "@id" could be set as the default uri_key when using JSON-LD ONLY if uri_dereference was the default ER handler. If the default ER handler for JSON-LD was UUID, then there would be no place for the uri_key default setting to be indicated.
This is a good point. I think this level of granularity should be addressed in contrib, but I think we'll want to have a plan for how core's implementation could be swapped out for a more granular one.
Comment #67
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch introduces a UUID entity reference handler and adds UUIDs to JSON-LD output.
Comment #69
Anonymous (not verified) CreditAttribution: Anonymous commentedI've created #1903784: Move serialization to own module so that the patch can focus on just the ER Handlers.
Comment #70
Anonymous (not verified) CreditAttribution: Anonymous commentedI added a test for the configured value entity reference handler, DenormalizeTest::testEntityReferenceDenormalize(). I'm hoping that this helps everyone understand how this currently works, since there has been very little review of the functionality.
This patch now depends on #1904508: Convert JSON-LD tests to DrupalUnitTestBase.
Comment #71
Anonymous (not verified) CreditAttribution: Anonymous commentedTo facilitate review, this patch excludes the code from #1903784 and #1904508.
Comment #73
klausi"null" should be all upper case.
Should start with a "\". Also elsewhere.
Doc block is missing.
This will throw a fatal error if the entity does not exist, because the load returns NULL. So we need some error handling here.
Same here.
Data types are missing.
But overall I guess this makes sense.
Comment #74
Anonymous (not verified) CreditAttribution: Anonymous commentedSorry if I wasn't clear, looking specifically for architectural review at this point. Its still wildly unclear whether we want to go down this path.
Comment #75
Anonymous (not verified) CreditAttribution: Anonymous commentedThe tests had to be updated based on changes the entity reference patch made to the entity reference API.
I also removed the URI dereference plugin from this and opened an issue, #1907732: Use URI dereference to import entity reference fields.
Comment #76
Anonymous (not verified) CreditAttribution: Anonymous commentedAdded the UUID test that we discussed on the call today. For now, it is in JSON-LD because we don't have denormalizers for the other formats yet. However, we should have one for JSON soon.
Comment #77
lanthaler CreditAttribution: lanthaler commentedI just watched your video Lin. A couple of question and some thoughts about how I would approach this problem.
The basic problem is that you have entities that can reference other entities. This implies that there must be a way to uniquely identify identities. In your case those identifiers are UUID or URLs I think. Since this stuff is being used for a Web API, entities (= resources) should be identified by URLs. You can map them to UUIDs internally (Drupal uses UUIDs internally, right?) but don't need and should not to expose the fact that you are using UUIDs - that's an implementation detail.
Given that you now have a mechanism to uniquely identify each entity, you need to able to serialize/deserialize that somehow. In JSON-LD you would use
@idfor this. In other formats you would probably use something else. The point is that it depends on the format so I don't think that needs to be configurable via those plugins you describe in your video. The only thing you'll need is a service which translates between the URLs used externally to the UUIDs used internally. Things like changing the author should be either be done as a preprocessing step (format-specific) or better as a postprocessing step. This has the advantage that it's very simple to implement also for other Drupal devs as you have your object structure with its well defined interfaces in place, you just need to traverse the object graph and replace all author references.I haven't read the whole discussion in this issue so maybe I'm missing something. What happens if you import the same data twice? Will it be duplicated? The reason I'm asking is because in the example actually also the articles itself are entity references. They just don't exist yet in your system (at the first run).
Hope this helps more than it confuses :-)
Comment #78
Anonymous (not verified) CreditAttribution: Anonymous commentedTo be clear, this isn't just about how JSON-LD will handle entity references. It is also about how custom JSON will handle entity references. For example, one API might serve "application/json" using an "href" key, while another might serve "application/json" using a "uri" key. Or there could be a Microdata JSON module which uses both "itemid" and particular properties such as Schema.org's "url" property to indicate URIs for resources. Since this is configured on a field instance basis, these use cases could be accommodated. This flexibility is something that Drupal devs are going to have to decide whether we want or not.
Comment #79
lanthaler CreditAttribution: lanthaler commentedRight, but that's a serialization issue and not a reference-handling issue. Whatever you do, you can't make the plugin's settings near flexible enough to accomodate the differences anyway (I'm takling about the uri_key setting in your video). Just imagine one day you decide to expose it in XML (attribute or value?) or a binary format (hmm.. an offset maybe?). Only the serializer will know how to extract the referenced entity's identifier and can then just pass it to the EntityReferenceResolver (or whatever you call it) to get the internal reference.
I don't understand this. I think the snippet above hasn't much to do with entity references. This is how internal properties are mapped to to external properties (schema.org, FOAF, etc.). That's, IMO, an entirely different problem and probably much easier to solve. Just let a developer supply a (number of) strings (URLs?) a property should expand to. If she doesn't supply any, just generate one using the property's UUID (or whatever you use internally). But, AFAICT, this has nothing to do with how a reference is serialized.
Comment #80
Anonymous (not verified) CreditAttribution: Anonymous commentedThis solution still works with XML. By the time processing reaches the Entity Reference Handler, we're already working with a decoded array. For XML, this means that the difference between handling attributes and values is already taken care of.
For example, let's look at the following two XML snippets and their decoded array equivalents:
I am focused on supporting the commonly used formats, with a primary focus on JSON/JSON-LD and secondary focus on XML and other formats. I am not prioritizing binary. Anyone who wants to support binary in contrib can structure their Normalizers in a different fashion.
In microdata itemid is not a property, so it shouldn't be mapped as if it were, IMHO.
Comment #81
effulgentsia CreditAttribution: effulgentsia commentedI started delving into the code some more to see where the separation both is currently and could otherwise be made. I continue to like the plugin part of the architecture, but am concerned about the configuration part, so I'm interested in ideas that reduce the configuration that's needed, like the ones by lanthaler. I'll post more here if/when I figure something out that's worth sharing. I welcome others to do the same and/or provide other feedback as well.
Comment #82
Anonymous (not verified) CreditAttribution: Anonymous commentedAs you know, I do share your concern about the amount of configuration required. As we're considering options, I just want to point out a few problems with tying entity reference handling to the format's serializer.
It also only accommodates APIs which define their own media type. For example, the Stormpath API uses an "href" key where JSON-LD uses "@id". However, it uses the media type "application/json". As I explained above, if we tie configuration to format, we can't support these APIs which have a less formal contract. I would wager that far more of the APIs that Drupal sites will use have an informal contract, rather than specify their own media type.
I am not opposed to having default settings for a format as we discussed on the call earlier this week, and I'm open to other ideas for reducing configuration. However, I think that tying entity reference handling to the format (and making it not configurable at all) is not going to work for our users. In an ideal world where everyone uses media types to define their contract, yes... in ours, no.
Comment #83
lanthaler CreditAttribution: lanthaler commentedSorry, I think I wasn't clear enough. When I said serializer in my posts above I always meant the combination of a concrete normalizer and encoder. The encoder will remain the same if two serializations use the same syntax (such as JSON-LD and JSON do e.g.). It's the normalizer which has to change based on flavor of the format. So, as you already did, there are two separate normalizers for JSON and JSON-LD.
Isn't that effectively a different format? Even though they don't label their responses accordingly? It's similar to the various XML-based formats (plain XML, Atom, XHTML, ...). What's the advantage of introducing another layer of abstraction in the form of plugins? [That's really a question and not a statement :-)] Isn't it easier for a dev to modify (subclass) an existing normalizer to accomodate the changes than to configure a plugin? How often does that really need to be done? I think only when another API which uses a different contract/format is being integrated.
Maybe the simplest thing would be to define a EntityNormalizerInterface that extends Symfony's NormalizerInterface by a number of methods to normalize/denormalize fields of certain types (e.g.
normalizeEntityReferenceField($field)). In most cases you would then only have to overwrite that method for a specific format.The configuration would then be as simple as choosing the format
json(which would be Drupal JSON),json-stormpath,json-ld, etc. Wouldn't that be much simpler and easier to understand (less magic involved)? I just don't think you can capture the differences of the various APIs in a small number of plugins.Edit: In the end, you could implement those interface methods also using the strategy pattern, so that you would end up having plugins. Nevertheless I think it would make sense to give such a concrete normalizer a name reflecting the "format". When I say format, please don't confuse that with the
$formatparameter in the Symfony serializer. It could as well be an option for a format (an entry in the$contextparameter).Comment #84
Anonymous (not verified) CreditAttribution: Anonymous commentedNo, we have no way of distinguishing between two "application/json" requests/responses within Serializer. I don't think we want to introduce informal-contract sniffing into our system, either.
We already have a separate Normalizer for the EntityReference field type, JsonldEntityReferenceNormalizer. We don't need to extend Symfony to do it.
TBH, overriding the $format with $context['format'] feels more like a hack to me, especially since Serializer relies on the $format key for caching which Normalizer to use. I'm also not sure how we would populate that $context['format'] parameter... informal-contract sniffing? Define it in the REST plugin metadata for the route?
These are just a few of the concerns. However, I do think there could be some usefulness in explicitly labeling informal contracts, like the json-stormpath one, and finding a way to use that.
Comment #85
lanthaler CreditAttribution: lanthaler commentedHow do you link the serializer to the the right plugins (instances)?
Btw. Is there a way to have a look at the code via some Web interface (not just patches)?
Comment #86
Anonymous (not verified) CreditAttribution: Anonymous commentedlanthaler's comments, particularly his suggestion to give names to informal contracts (e.g. json-stormpath), gave me an idea. We could create a separate Serializer per contract. We had discussed doing this per format before, but then klausi came up with a simpler solution for making the formats discoverable. With this solution we would have a serializer.json service, a serializer.json.stormpath service, etc. I filed an issue, #1913048: Support serialization with same media type, different contracts. This would have the downside of making it difficult to switch between formats within one deserialization request, but I think it is worth that tradeoff.
This patch provides an example of how this would work with the Uuid matching strategy. There is a UuidReferenceInterface which the JsonldEntityReferenceNormalizer implements. This lets the Uuid plugin know that the Normalizer supports matching based on UUID. If someone then wanted to allow entity resolution based on something like Twitter id, they could declare a TwitterReferenceInterface and any contracts which support it (e.g. serializer.json.twitter) would implement it in their EntityReferenceNormalizers.
In a call on Friday, effulgentsia suggested that configuration should be based on the field rather than the field instance, and I have also removed the plugin instance settings, so the configuration file is simplified. I still need to implement defaults, so the REST module tests will fail.
Comment #88
Anonymous (not verified) CreditAttribution: Anonymous commentedThe name of the EntityReferenceHandler needs to be changed. I created a different issue to discuss that so that we can focus on functionality here, #1915414: Change name of serialization's (proposed) EntityReferenceHandler
Comment #89
Anonymous (not verified) CreditAttribution: Anonymous commentedThis patch is a big shift.
In reflecting on the conversation in this issue and on calls, I decided to move away from the plugin-based way of handling this (which is a strategy pattern, as lanthaler pointed out) to one which is closer to the pattern Serializer itself uses to determine Encoders (basically chain-of-command).
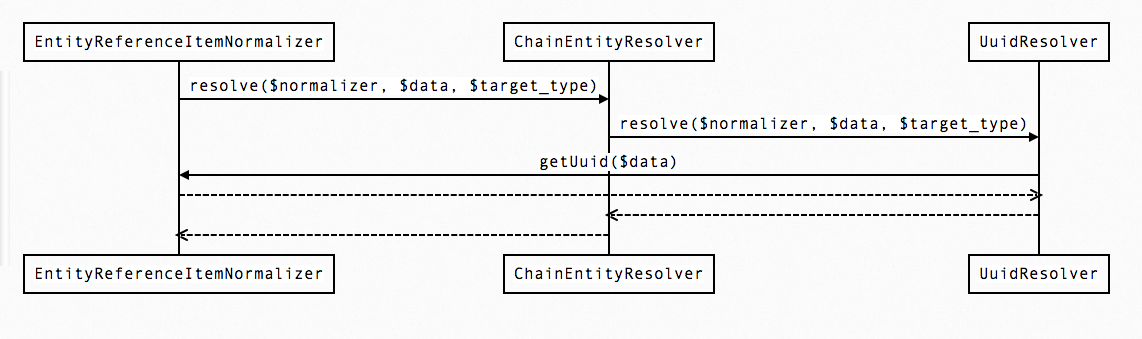
It introduces the concept of an EntityResolver. There is a ChainEntityResolver which contains the array of EntityResolvers which have been registered with the container. If an EntityReferenceNormalizer needs to resolve entities, the ChainEntityResolver should be injected using setter injection (for example, as it is in JsonldEntityReferenceNormalizer with setEntityResolver).
During deserialization, when the EntityReferenceNormalizer deserializes an individual reference, it calls
ChainEntityResolver::resolve($this, $data, $target_type). The ChainEntityResolver will then go through the chain until something returns an array. That array has two potential keys,target_id(the internal id) anddereferencer. For example, the UuidResolver would set the target_id if it found a corresponding entity for the UUID. If it didn't, then command would pass to the UriResolver which would see if there was a matching URI, and if not, would return a dereferencer that knows how to fetch and create an entity.This means that any EntityReferenceItem pointing to an entity that didn't already exist on the site but could be fetched would have a 'dereferencer' property. This property could then be used by REST module or any other module to handle entity import however they saw fit. We might want to create a service which could simply dereference and save the entire entity graph so that it doesn't have to be reimplemented across many modules.
This idea of returning either the ID or the dereferencer was inspired a bit by SAX EntityResolver. In that case, it's an InputSource rather than dereferencer.
A resolver (such as UuidResolver) would know whether it was supported for a particular format/contract based on whether the Normalizer implements its corresponding interface. For example, for UuidResolver, the corresponding interface is UuidReferenceInterface, which has the method getUuid.
We would still want to have some configuration, which I haven't included here. Mainly, we'd want to allow sites to turn off entity resolution on a field by field basis.
Comment #89.0
Anonymous (not verified) CreditAttribution: Anonymous commentedAdded example config.
Comment #90
moshe weitzman CreditAttribution: moshe weitzman commentedI watched the video and read #89but still don't have much to say about the proposed architecture. The proposed pattern is used in Serializer as mentioned and it resembles the Matcher/PartialMatcher pattern used during routing.
I also appreciate that this patch adds dereference for uuid fields. Very handy!
So, sounds good to me!
Comment #91
Anonymous (not verified) CreditAttribution: Anonymous commentedI switched this to using HAL instead of JSON-LD. I also moved the test to serialization module.
Comment #92
Anonymous (not verified) CreditAttribution: Anonymous commentedComment #93
moshe weitzman CreditAttribution: moshe weitzman commented#91: 1880424-91-entity-reference-import.patch queued for re-testing.
Comment #95
Anonymous (not verified) CreditAttribution: Anonymous commentedHere's a reroll.
However, I think we might want to simplify this. The current design is optimized for adding support for other identifiers. For example, you could add support for resolving based on Google+ ID or Twitter username quite easily. To do this, someone would just extend the EntityReferenceItemNormalizer, and implement a new TwitterResolverInterface to extract the right key from the data.
However, from REST team conversations, it sounds like we do not want to optimize for this use case. In addition, people seem to be having a hard time understanding the Serialization system in the first place, even without this added complexity.
Rather than using the ChainResolver that I introduced here, we might just want to have the calling code specify which resolvers it wants to use. For example, the Normalizer for entity reference items in HAL might call
resolve('uuid', 'uri')to indicate that it wants to try those two resolvers. This would mean that the ChainResolver becomes a simple manager for resolver services. It also means none of the Normalizers have to implement interfaces like UuidReferenceInterface.Comment #97
Anonymous (not verified) CreditAttribution: Anonymous commentedA constructor changed, just had to update it in the HAL tests.
Comment #98
effulgentsia CreditAttribution: effulgentsia commentedIf you want to post a simplified patch, go for it, but I have no concerns with the approach in #97. I think both ChainResolver and UuidReferenceInterface are sufficiently straightforward.
That's a lot of duplication with FieldItemNormalizer::denormalize(). Can we add a helper function to the base class in order to centralize this?
Why a while() instead of an if()? In either case, please add a comment.
1. We need PHPDoc for $data and $target_type.
2. The patch doesn't include either a test or any docs on how a dereferencer is expected to work.
Comment #99
Anonymous (not verified) CreditAttribution: Anonymous commentedThanks for the review, Alex. I changed all of these. To address the first one, I created a constructValue() method which can overridden by any Normalizer to create the value array that Entity API expects for that particular field item. Let me know if the docs or naming need any changes on that.
I also added this as a branch in the WSCCI sandbox and created a sequence diagram as we discussed.
The interdiff only includes the changes that resulted from the first and third of Alex's comments (I forgot to merge before starting to work), but this patch also contains the fix for the second and a reroll with changes in the way classes are registered.
Comment #101
effulgentsia CreditAttribution: effulgentsia commentedThis just moves the non-hal-specific services from hal.services.yml to serialization.services.yml to match the module they were in in #97.
Comment #102
effulgentsia CreditAttribution: effulgentsia commentedSome docs and variable name cleanup. Also changes the return value of EntityResolverInterface::resolve() from an array that can only contain one key, to just the value of that key. Once we add support from some other kind of return value (like a dereferencer), then we can change this interface to support that, but in the meantime, I think this is clearer.
Comment #103
effulgentsia CreditAttribution: effulgentsia commentedAlthough the interdiff in #102 includes a small code change, I'll be bold and call it minor enough to RTBC this anyway. If anyone objects to that, please set it back. Or, if anyone objects to that change post-commit, I'd be ok with that interdiff being reverted and discussed in a follow up.
Comment #104
webchick#102: 1880424-102-entity-reference-import.patch queued for re-testing.
Comment #106
effulgentsia CreditAttribution: effulgentsia commentedChasing HEAD.
Comment #108
effulgentsia CreditAttribution: effulgentsia commentedYay! No more database schema for field configuration! Back to RTBC.
Comment #109
moshe weitzman CreditAttribution: moshe weitzman commented#108: 1880424-108-entity-reference-import.patch queued for re-testing.
Comment #110
Dries CreditAttribution: Dries commentedCommitted to 8.x. Thanks!
Comment #111
webchickDon't think that got pushed, so trying again:
Committed and pushed to 8.x. Thanks!
Comment #112.0
(not verified) CreditAttribution: commentedUpdated problem and issue summary with chain-of-command approach.