
Updated: Comment #N
Problem/Motivation
The NodeSearch plugin for the Search module (Core search's ability to search nodes) allows admins to decide how to rank search results, using one or more scoring algorithms. These are provided by hook_ranking(), and the scores are supposed to be values between 0 and 1 for each node.
The ranking algorithm that ranks most recent content first is not providing values that cover this range well. This breaks the ability for admins to choose to rank more recent code higher in search results.
Proposed resolution
Fix the recency ranking implementation so that the node rankings for most recently updated content work better.
Remaining tasks
Viable patch with tests.
User interface changes
None, except search results will match ranking set-ups better.
API changes
None.
Original report by @BlakeLucchesi
During my Summer of Code project I noticed that the algorithm used to normalize and adjust the score given to nodes based on their recency was not producing values spread across the range of [0,1]. Using the devel module after completing a search I copy and pasted the query used to gather the results to see how the scores of the results were being distributed. I found that most often times the score attributed to a recent node was so small that it was essentially meaningless when compared to the score of other ranking modifiers.
Using this new algorithm nodes with recent timestamps receive scores that approach the maximum (the score given to it in the search admin screen) while previously this was not the case. I have attached a screen shot of the score results for a search done on a set of nodes created with a few weeks of the search. Additionally I have attached another screen shot of the same search using the old ranking algorithm. I'd love to get some more feedback on this.
Additional discussion:
| Comment | File | Size | Author |
|---|---|---|---|
| #61 | 303574-search-ranking-61.patch | 12.65 KB | jhodgdon |
| #32 | 303574-d8-test-only-FAIL.patch | 6.9 KB | jhodgdon |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
BlakeLucchesi CreditAttribution: BlakeLucchesi commentedOk sorry, for some reason my patch and screen shots didn't get posted. Here they are:
Comment #3
BlakeLucchesi CreditAttribution: BlakeLucchesi commentedFixed typo sorry.
Comment #5
BlakeLucchesi CreditAttribution: BlakeLucchesi commentedOk working patch for real this time. I used textmate's cvs bundle the last few times and it did the diff with respect to the specific file not Drupal root directory.
Comment #6
douggreen CreditAttribution: douggreen commentedBlake, could you give a little more detail of what this new algorithm is doing, and possibly add a comment to the code that explains it (for example, the old comment said "Exponential decay with half-life of 6 months, starting at last indexed node"). I know that 2.718 is e, what's the -5 for?
Remembering that these values must be normalized between 0 and 1, I looked at the two algorithms. The low end of both algorithms is 0, but the high end of the current algorithm does not appear to be one. Is it possible that the only problem with the current algorithm is that the decay isn't working right? Should the multiplication by 6.43e-8 (which is 1 / (60 * 60 * 24 * 365.25 / 2) which I think is a normalization factor, be inside the POW()?
I'm changing to CNR, so that we can discuss and write some simpletests. I think that a test that looped through times from a certain date forward, and showed that the algorithm produced the expected results would be helpful. For example, with the current implementation, we should have a test that starts 6 months ago, and shows that newer items are weighted twice as high as the next newer item, and so on.
Comment #7
douggreen CreditAttribution: douggreen commentedIf this is a problem, we should try to fix. Re-rolling to current HEAD.
Comment #9
douggreen CreditAttribution: douggreen commentedAttached patch includes a few improvements:
Comment #10
jhodgdonLooks good to me. Unless the test bot objects...
Comment #11
Dave ReidShould be max() instead of MAX since its in PHP. And needs tests possibly? Or test chunk isn't included in the patch?
Powered by Dreditor.
Comment #12
webchickHrm. If the tests aren't breaking now and this bug exists, it seems like we need extra test coverage for this..?
Comment #13
jhodgdon- MAX is not in PHP, really, it's a fragment of a query.
- I'm not sure about a test for this. The old algorithm was bad in that it wasn't giving a reasonable distribution of relevancy rankings. We think the new one is better. The current tests for rankings just test the ordering, not the actual numbers, and the ordering hasn't changed...
Comment #14
jhodgdonDuh. Scratch that about MAX, you are right it is in PHP.
Comment #15
webchickYeah, I guess what I'm saying is it seems like the old tests were insufficient for catching this bug. So it seems like we need expanded test coverage for also checking the relevancy rankings distribution, in addition to the ordering. Unless I misunderstand.
Comment #16
jhodgdonI hear you. But I don't know if not having tests for relevancy distributions should block fixing this really broken one. Can we make it a separate issue, because not having these tests applies to all the other rankings too, and I also think that while writing them is important, it might not be quite as high priority as some other search issues?
Comment #17
douggreen CreditAttribution: douggreen commentedI've written a test, but it found bugs, so I'm fixing the bugs.
Comment #18
douggreen CreditAttribution: douggreen commentedAttached patch adds a test, changed
MAXtomax, and fixes a problem we had with our current tests related to changed times not set properly.Comment #19
douggreen CreditAttribution: douggreen commentedRemoving "needs tests" tag now that there's a test...
Comment #20
jhodgdonAssuming that the test bot agrees, I think this is ready to go.
Comment #22
douggreen CreditAttribution: douggreen commentedUgh, removing debugging...
Comment #23
douggreen CreditAttribution: douggreen commentedOne more note, this patch fixes the range of the recent node ranking to be from the oldest changed node to the newest changed node, rather than from the oldest changed node to the current time. This way, if nothing has changed in the last N days, the newest node still has the highest recency of 1.0.
Comment #24
chx CreditAttribution: chx commentedGood to go. Although using EXP() instead of POW would be a slightly better but we are not bound by anything, it's totally arbitrary.
Comment #26
douggreen CreditAttribution: douggreen commentedI'll change it to use EXP(). Plus the new test uncovered a bug that I'm working on the fix for.
Comment #27
douggreen CreditAttribution: douggreen commentedI need to test this on postgres, and break out some of the changes into a separate patch, but attaching here so we don't lose it.
Comment #28
jhodgdonWe should be working on this in 8.x now.
Comment #29
jhodgdonThis look like something we should revive. I'm going to look into it. The latest patch is D7 and also has a bunch of other unrelated stuff in it, but it looks like a good start if we can distill out the relevant pieces and put them into 8.x.
Comment #30
jhodgdonI did some analysis of all the existing rankings (gotta put all that math background I have to use sometimes!).
There are 3 hook_ranking() implementations in Core:
- comment_ranking() - Nodes with more comments are ranked higher.
- statistics_ranking() - Nodes with more views are ranked higher
- node_ranking() - provides 4 ranking algorithms:
- Keyword relevance (this is the standard ranking provided actually by the SearchQuery class)
- Sticky
- Promoted to front page
- Recent - Nodes more recently posted are ranked higher
Analysis:
a) The "Sticky" and "Promoted" rankings are fine - nodes with those bits set get a 1, and nodes without it get a 0.
b) Comment and Statistics rankings both use an equation like this:

2.0 - 2.0 / (1.0 + count * scale)
where count is the # of comments or # of views for the node, and scale is calculated during cron to be 1 / (max count). This seems to be OK. I analyzed what it would do for nodes with a count of 1 to 30 (assuming the max in the database was 30), and the values ranged from 0.06 to 1. Here's a graph:
c) Recently updated (the subject of this issue) - This is currently in 8.x using an equation that looks like this:
2^ (updated time - scale) [2^ means "2 to the power of"]
where scale is set to the updated time of the latest indexed node.
Two problems with this:
- The latest indexed node may or may not really be the node with the latest updated time that exists.
- As reported originally in this issue, even for a node 2 hours older than the most recent node, since the times are in seconds, this drops way way too quickly down to essentially zero. [So, I confirmed this report.]
The proposal is instead to use

e^(-5 * (1 - (updated - oldest)/(newest - oldest))))
Here's a graph with hours old on the x-axis (ranging from a just-updated node to a year old):
This seems reasonable. Content that is a day old is ranked pretty close to 1. Content that is a week old gets a .91 ranking. Content that is a month old gets 0.66. Comment that is 3 months old gets 0.29. Year-old gets 0.0067. In any case, it's way better than what is there now.
But... the EXP function seems to be available in most variants of SQL. However, it looks like neither POW nor EXP is available in SQLite. I wonder if that is OK? We could instead use something more like what the comment and statistics rankings are using, such as:
2.0 - 2.0 / (1.0 + (updated - oldest)/(newest-oldest))
But this doesn't really fall off fast enough. If you have content that ranges from current to 1 year old, the 6-month-old content would still have a ranking of 0.67, and all the stuff from the first month would be above .95. So I think we probably do want it to be exponential. Using exp() is probably not any worse than using pow(), which is what the existing code does, and exp() seems to be supported in most other databases (unlike pow() which is power() in some databases anyway).
So I think we should stick with exp().
d) Keyword relevance
This is using an equation that looks like (scale * score * count) for each node, where scale = 1 / max(sum(score * count)). So this is just linear in the "score * count" value, and it is weighted with the most relevant node having value 1. I think we can assume this is working OK.
So, I've reconfirmed this issue, and validated that the proposed ranking should be much better than what we have now. I just need to take the patch and port it to D8. What it needs to do:
a) Each cron run, calculate the oldest and newest update times for nodes, and store them in the state system.
b) Use the equation above for the ranking instead of what is there.
I've updated the issue summary and I'm working on a patch.
Comment #31
jhodgdonHm. In looking at this code vs. what is there, I also noticed that the current code is based on the created time, and the proposal here is based on the updated time. The ranking is called "recently posted" in the UI. So I think we should actually use the created time and not the updated time in this search ranking, which would be more compatible with what was intended in the original code.
Also I have noticed that it is impossible to test vs. the updated time, because Node::preSave() always sets the updated time to the REQUEST_TIME, which is constant in tests, and there is no way to override this.
#2213411: WebTestBase::drupalCreateNode() shouldn't imply you can set 'changed' time.
Comment #32
jhodgdonOK, here's my first go at a patch for this in Drupal 8. Tests work locally -- and they fail where you'd expect without the patch, so I think they are good tests. Let's see what the bot thinks.
I added some tests, and combined some test methods together. There was a test method called testDoubleRankings() but it was kind of lame (it basically just turned on two rankings and verified you could still search, to test #771596: Turning on multiple search weights causes PDO exception during search). So I removed this, and instead added this functionality test to the testRankings() method, which had nodes for all the ranking options, so that I could actually test that if you prioritized one ranking over another, the ordering was correct. Seemed much better.
Comment #34
jhodgdonThe test that failed was supposed to fail in exactly the way it did, to illustrate the problem of this issue. So, we just need a review.
Comment #36
jhodgdonHuh, wonder why the patch in #27 suddenly got retested?!?
Comment #37
jhodgdon32: 303574-d8-with-test.patch queued for re-testing.
Comment #39
jhodgdonEasy reroll.
Comment #40
dawehnerIs there any way to use entity query instead? It does support aggregation to a certain limit.
Should we store the information in one state to not require two queries, potentially.
Comment #41
jhodgdonRE #40...
1. No, I don't think entity query would work. At least, the docs for the execute method say that it returns either an int (if it's a count query) or a list of node IDs (if it's not a count query). Neither is what we want for this query. Besides which, it seems like it would be a huge amount of overhead for a simple query like this.
2. Yes, we could store the result as one state variable. I thought it was clearer code this way, partly because I couldn't think of a good name for a combined state variable and these two names, I thought, were clear... I also don't think, in practice, that two state->get() calls right after each other like that will ever require two different queries?
Comment #42
jhodgdondawehner and I discussed this in IRC, and dawehner supplied code in a pastebin that uses entity aggregate query, which I incorporated.
Also, as suggested, the state is now using one variable instead of two.
Here's a new patch. (No changes to the test part of the patch, so I didn't upload another "test-only" patch.)
dawehner credit!!
Comment #43
jhodgdon42: 303574-d8-with-test-42.patch queued for re-testing.
Comment #45
jhodgdonStraight reroll. Some other patch took care of the hunk in Drupal.php.
Comment #46
jhodgdonComment #47
jhodgdon45: 303574-d8-with-test-45.patch queued for re-testing.
Comment #48
jhodgdonReroll for PSR-4
Comment #50
dawehnerThis patch feels quite good
Comment #51
catchCould someone run an EXPLAIN on the generated query, feels like it should be fine since there's a dedicated index for the created column, but just in case.
Comment #52
jhodgdoncatch: I can do that, but ... is that the relevant query? That query is in the hook_cron(), so even if it is slightly slow, I don't think it matters a whole lot.
The more relevant query is probably the one that is done during search execute (implied by the hook_ranking() implementation).
Anyway, I'll see what I can do about an explain for both of them.
Comment #53
jhodgdonI forgot about this...
OK, so there are a couple of queries here.
The first one is during node_cron():
This results in a query like this:
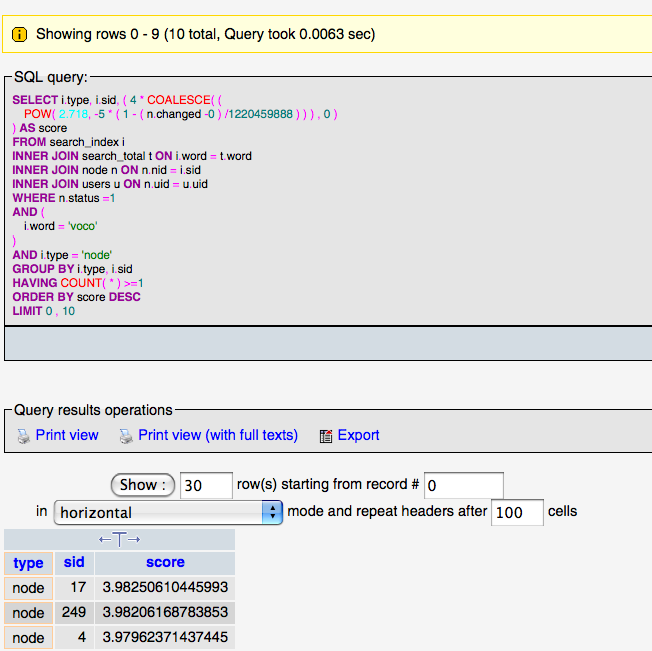
Here's a screen shot of explain output in phpmyadmin:

I'll look at the other one in the next comment... I really don't know much about explain queries... not sure if this is good or bad, but this particular query is only happening once per cron run, so I am not sure why we even care too much?
Comment #54
jhodgdonb) The second query happens during searches, and is in the node_ranking() code.
Without this patch, we have:
And with this patch, we have:
These are both added into the search query. So, to turn this on:
- Add a node.
- Go to the Search settings page, edit the NodeSearch page, and set the influence on Recent to 10 (default is 0 meaning "ignore this factor").
Then do a search. This results in a query like this with the patch:
[Note: EDIT - with and without patches were reversed in this section!]
And without the patch:
Ugh. I have to go and those placeholders... do you need an explain on this one?
Comment #55
jhodgdonThese two queries are essentially the same. The difference is that with the patch, the calculation of the score goes from
to
(so only created is used instead of changed, and a different mathematical function).
And there is a new join between node_field_data and search_index, on nfd.nid = i.sid
When I run an explain on a query that does this join, it says it is using PRIMARY for that, so I think it is OK. There is not any difference between the two queries in the WHERE, ORDER BY, or GROUP BY, or HAVING, except the score is the ORDER BY, so the ordering will be different. But if anything, the score is involving fewer database fields in the new query.
I'm provisionally going to set this back to RTBC...
Comment #56
alexpottWe're not using the
node.cron_laststate anymore there we can should remove all sets and deletes of it - NodeSearch::indexNode() and node_uninstall() need fixing.Comment #57
jhodgdonAh, good idea.
Here's a new patch. This removes everything having to do with the state variable 'node.cron_last', and in addition, NodeSearch doesn't require State any more.
Comment #61
jhodgdonStraight reroll. This is probably RTBC...
Comment #62
alexpottWe need a CR to outline the change and removal of node.cron_last
Comment #63
jhodgdonGood idea. https://www.drupal.org/node/2337437 is the change record.
Comment #64
alexpottCommitted 829c436 and pushed to 8.0.x. Thanks!
Comment #66
jhodgdonThanks alexpott!