
Update: read the summary in comment #51 at http://drupal.org/node/532512#comment-5679184).
Original report
... and the translation interface has no way to determine if they are plural, so it treats them as singular.
That's a severe issue, as it breaks all languages that do not follow English plural conventions (and most of them don't...).
There are two issues:
- locale() and format_plural() are independent from each other. format_plural() calls t() (and thus locale()) with a single, singular or plural form.
- the plural information is part of the {locales_target} table, where as it is really a property of the {locales_source} table.
To solve this issue, I suggest we store both the singular and the plural form in the *same* row of the {locales_*} table, in a serialized form. format_plural() would call t() with the full, (serialized) array($singular, $plural), and gets in return a (serialized) array of plural forms.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Comments
Comment #1
Damien Tournoud CreditAttribution: Damien Tournoud commentedComment #2
andypostGood idea and this approach could simplify logic and memory in _locale_rebuild_js()
Comment #3
andypostlocalization server stores strings in one TEXT field separated with "\0". But there's an issue #690746: Text column type doesn't reliably hold serialized variables
This is a approach of gettext mo files http://www.gnu.org/software/hello/manual/gettext/MO-Files.html
This makes easy to search them. If we serialize them then additional data from serialization will break searches :(
I think we should unify core and l10n_server
Comment #4
andypostIf it's possible to include this in D7 I could roll a patch. Upgrade path could be hard but I think that sane translation is need!
Schema from l10n_server
Current core
I cant understand a reason to make an index on 30 chars of blob also mysql_type should be removed
Suppose we could follow l10n_server approach to join singular & plural in one field. This lead to removing a plid and plural fields from {locales_target} also simplifies a code and makes translation system a bit usable.
Comment #5
andypostHistory search:
- index source(30) is outdated #42463: locale.module: adding an index on the source field improves speeds
- mysql blob used for case sensitive search #93506: locale_* tables need %b
Comment #6
andypostBecause of nature of http://api.drupal.org/api/function/format_plural/7 I see no visible benefit of joining singular and plural.
Because in request mostly only one of them used. But I think we could add relation between them which could help to improve edit-strings form.
Functions that affected by plural column
http://api.drupal.org/api/function/locale_translate_export_po_form_submit/7
And import strings
Comment #7
andypostThere's another issue with format_plural() - no ability to differentiate a singular and plural form of string. Attached module shows this (with russian language) - If string used in both t() and format_plural() so only one is stored.
Steps to reproduce:
1) Enable locale module
2) Add some language with plurals >= 2 (for example russian); a list of plurals could be found at http://www.gnu.org/software/gettext/manual/gettext.html#Plural-forms
3) Enable attached "Loc" module (russian translation should be auto-imported)
4) Visit /loc-test
t('1 line') translates as "@count строка"
If you manually import loc-ru.po file (with mode = "Strings in the uploaded file replace existing ones, new ones are added. The plural format is updated.")
You'll see different translation of first and last lines
This all because
potx exports both
Comment #8
andypostHere the patch to illustrate bug
532512-locale-tests-d7.patch - Just improved tests (adds form-id to detect export type)
532512-locale-tests-plural-broken-d7.patch - Shows that no plurals are exported if no translation avaliable
EDIT: interdiff
Comment #9
andypostSuppose we should know n-plurals for every language supported by core to build a correct form to translate plural strings.
Comment #11
Dmitriy.trt CreditAttribution: Dmitriy.trt commentedformat_plural() should not use t() and we should add different table for plural forms, or should use t() in different way (one call for singular and plural form imploded with \n or other special symbol).
Drupal core MUST provide methods for correct translation of plural forms to languages with non-English behavior of plural forms. Please, read also this chapter of gettext manual about plural forms: http://www.gnu.org/software/gettext/manual/gettext.html#Translating-plur...
Localization support is not full without it!
Comment #12
andypostI stacked with edit forms... I see no ability to build a forms for translation without knowing a number of plural forms for language!
This is required for locale_translate_edit_form()
Possible solutions:
1) for each language core should store a number of plural form... seems hard to find them all
2) This form should assume nplurals=2 for languages that have {languages}.plurals = 0
From this point I think we need review one of locale mainteiners
Comment #13
plachsubscribe
Comment #14
andypost#8 still applies with offset, Suppose we need to commit this quick fix and move this issue into D8
Comment #15
podaroksubscribe
Comment #16
andypostSeems this issue is about re-factoring so my summary
#545518: Move Locale module specific code out of module.inc and system.module
#851362: Add hash column to {locales_source} to query faster locale strings
#746240: Race condition in locale() - duplicates in {locales_source}
#811158: We should not index on (source, context)
Comment #17
andypost#8: 532512-locale-tests-d7.patch queued for re-testing.
Comment #18
Gábor HojtsyTag for Drupal 8 Multilingual Initiative.
Comment #19
Gábor HojtsyNo patch suggested to fix the issue, so marking as needs work.
I think the easiest solution would be to merge the singular/plural values in one string like l10n_server does (it concatenates them with \0). That is not exceptionally nice, BUT the singular+plural string is a unique identifier in .po files (that is what you see when you export the data and the same string appears in both the standalone singular form and the singular/plural form).
That would require format_plural() to do the same concatenation when looking up the strings, but the whole database storage system would be simplified a great deal. There would always be a one to one relationship from source strings to translation strings in the database, because the plural/singular differences would be encoded inside the string. (Also makes it much easier to produce an editing UI with all of them at once) Because we don't need to look up strings individually out of context we don't loose much.
Comment #20
Gábor Hojtsy@andypost: would you be interested in helping with introducing a "serialized" plural storage just like in l10n_server?
Comment #21
andypost@Gábor Hojtsy I'm going to invest some time this weekend to d8mi. I'll take a storage from l10n_server 7.x branch
Comment #22
andypostroadmap
EDIT postponed til this #361597: CRUD API for locale source and locale target strings
Having \0 as delimeter will cause a trouble with postgresql and sqlite #690746: Text column type doesn't reliably hold serialized variables
Comment #23
andypostafter some testing and investigation I propose to use "\03" Control_character which means End-of-text_character
There's a small module for D8 which I used to test searchability of text inside text field after delimeter
"\0" does not works:
So I start work with "\03"
It could be great if someone will test this module under mssql and oracle, see attachment
You could use it under D7 just change to
core=7.xin .info file- install the module
- navigate to /tdemo
- press "Generate"
- enter any part of strings in "Database" table and press "Search"
- results for searching "@count новых коментария" should return 1 line in result
Comment #24
podarok#23
can we provide an option for selecting proper character depend on database type? via configuration option possibly with provided array of successfull selectors
Comment #25
Gábor Hojtsy@podarok: that would make dumping and import/export pretty hard, right? If serialization does not work out, we can store the values in their own column. Ie. a plural field in the source table and plural1, plural2, etc fields in the translation table up to as many number of plurals as needed. It would be slower to search in (i.e. from the admin search screen we would need to look up based on possible matches in all columns), and we'd need to be able to define the max number of possible plurals.
Comment #26
podaroknot if we will provide CRUDi API for that
right?
such table will not be huge, but very nice for indexing... possibly we can store it in one or few documents in NoSQL databases
also we will store multiple NULL data 8))
Comment #27
andypostI think denormalization in this case will bring more troubles than advantages.
Most of time core make queries by
sourcefield and refactoring of format_plural() to query imploded string should be the same as quering ine string as it works for now. Also we could use hash column to query faster #851362: Add hash column to {locales_source} to query faster locale stringsright now I bit stacked with refactoring of format_plural() D8 stores number of plurals and formula in variable since #1323176: Decouple UI translation language information from language list schema
also this could cause more race conditions #746240: Race condition in locale() - duplicates in {locales_source}
Comment #28
Gábor HojtsyYes, Drupal 8 will however does not offer the variable_* API anymore, it will use a new API introduced by the CMI (Config Management Initiative), so I think we should return to possible race conditions at that point. It is hard to predict now what kind of race conditions solutions that would provide (it depends on the storage it is going to use for the values and/or how we use that storage).
Comment #29
Gábor Hojtsy@andypost: also, I think that postponing this on #361597: CRUD API for locale source and locale target strings is the wrong solution. By making plural storage simpler, the issue at #361597: CRUD API for locale source and locale target strings is made much simpler also. So solving the more complex problem there first and then coming back to simplify it does not seem like a good way forward. I think it would be great to fix this first.
Comment #30
andypostThe conclusion I came up now for format_plural() is
t(implode(LOCALE_DELIMETER, array($singular, $plural)))and then explode the result and use the result.I'm still working on schema upgrade path
Comment #31
Gábor Hojtsy@andypost: that seems to reflect the gettext storage model for the string well, where it is stored using the singular and plural form both comprising the ID together.
Comment #32
andypost@Gábor Hojtsy yes, but schema upgrade seems should be done in batch because a huge data amount stored in tables. But bootstrap require fixed storage so chicken-egg should be resolved in early install/update/fix requirements phase
Comment #33
Gábor Hojtsy@andypost: can we somehow pick out the plural source/translation strings only. That should be a pretty small number of strings on a regular Drupal site and would not require a batch. That is if we identify those strings with a simple and quick query.
Comment #34
podarokdifferent storage for plurals?
exelent idea!
Comment #35
Gábor Hojtsy@andypost: any progress?
Adding the sprint tag to keep a closer tab on this.
Comment #36
Gábor HojtsyAdding UI language translation tag.
Comment #37
Gábor HojtsyHope this new title is better for the realized new scope of this issue. I'm not sure we need to solve all the issues here. Let me know if I can help you with anything.
Comment #38
andypostPatch introduces:
1) Changed a format_plural.
2) Plural strings are stored merged with LOCALE_PLURAL_DELIMITER in locales_source.source and translation locales_target.translation probably we could drop
plidandpluralfrom locales_target table not sure that update function possible that could find broken strings (different issue)3) Import and export are updated to use this storage. _locale_export_remove_plural() could be removed now we have no need in @count[n] strings.
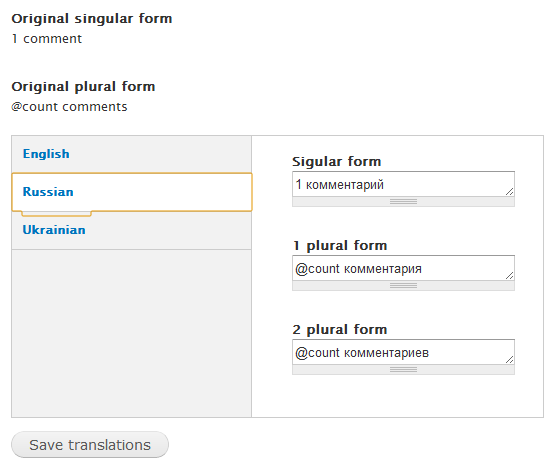
4) admin UI changed to allow translate plural strings. For plurals strings I choose a vertical tabs with languages as tabs. For none-plural strings interface is a same. Form is changed so some tests could fail. The problem here that if there's no plural formula so no ability to determine a number of controls so fallback to singular and plural. This form needs usability review
5) translation search screen is not touched but need some love because merged strings could confuse

Let's see what testing could say...
Here's goes some background
Currently we have no plural formula and number of plurals for language added within admin interface this causes that we cant use plurals for newly added languages and can't build a edit forms because we don't know a number of fields needed for a language
This information stored in
variable 'locale_translation_plurals' = array('langcode if not en' => array('plurals' => N, 'formula' => '(n > 1)'))We have exception for English language to not store it's plural information in this variable and fixed troubles caused in #1221276: locale_get_plural() only works for a single language within a request and does not work for English
and small fix already in #655048: Plural formula information blanked when importing a poorly-formed .po file
So I see 2 solutions for solving unknown number of plurals for language
1) Add to standards.inc a predefined list of plural formulas and numbers to copy them into variable after adding a language. That way we allow some contrib module to edit this information if needed and override on import .po file
2) assume that each language has 1 plural formula by default (there's a some languages see Plural forms) and build edit forms with this assumption. I found that Vietnamese has no plural formula because this language has only 1 normal form as the most Asian languages
Modify storage:
1) remove plid and plural from locales_target table because they are not used by core and store all translations imploded by LOCALE_PLURAL_DELIMITER
2) add a bit-flag is_plural to locales_source table indication that string is a plural or just explode loaded string with LOCALE_PLURAL_DELIMITER on load to determine is a string has plurals
We are already going to modify translation table in #1445004: Implement customized translation bit on translations
Comment #40
Gábor HojtsySuperb, great stuff. Looked at the patch and the changes seem to be very good. Some comments:
I think we'll need to somehow resolve the upgrade path in this issue? Do you intend to move that to a new issue? (Or just handling incorrect data from before the update?)
I'm not a usability expert, but that the form looks totally differently for only-singular and singular/plural strings is a bit puzzling. Why not make it work the same way for both? (I think we'll want to move towards an l10n_server (localize.drupal.org-resembling) UI for Drupal 8 if we have the time for it, so I'd not delve into this UI much, but in case we don't have the time for that, we should at least have something consistent IMHO).
Yes, this is a long known limitation of Drupal. The overall plan for Drupal 8 is that integration with files downloaded from localize.drupal.org will be built-in (think we'd build in l10n_update in core essentially), so theoretically the window inbetween adding a language and getting a useful plural formula for it would be reduced to seconds if using that feature. Which means practically, languages would not exists for any reasonable time without a useful plural formula.
If we do want to add some default for plural formulas, we have a good directory of formulas available / setup on localize.drupal.org. We can export from that data, but given the above I'm not sure its worth the effort. We can default the formula to the most common one (nplurals=2; plural=(n!=1);), but then overwriting it would only be possible if you import .po files in overwrite mode, which you usually don't want.
Also, plural formulas look very much black magic to an everyday user. I built http://drupal.org/project/l10n_pconfig about two years ago to expose the setting for sites like localize.drupal.org where it is important to be editable. Yes, it is just a textfield but it is very-very techy and people should usually not touch it at all. (The module also has a built-in list of plural formulas that is not really synced (yet?) to localize.drupal.org's latest data with all the new languages added there).
So all-in-all I think leaving the initialization to the first .po file imported is fine, and the l10n_update integration should bring that much sooner. I think its ok to not let people enter translations for plurals until the formula is initialized (l10n_server does the same). So I'd throw an error on the translation page if there was no formula to build the translation UI on.
Yes.
I think this could be useful for quick filtering purposes and was suggested for l10n_server before.
I don't think we should worry about that, whichever gets in first will dictate that the other one needs to adapt to the first. These are two very separate features, so IMHO we should keep them separate.
All-in-all looks good, keep it up! Thanks!
Comment #41
andypostFiled issue about UI #1452188: New UI for string translation
Going to fix some tests and proceed with VT implementation for UI in this patch because we definitely need a UI to continue work and allow core to translate plural strings
Comment #42
andypostseems tests should be fixed
Comment #43
andypostUnified screen for editing - always using VT
Comment #44
andypostlast patch displays a language name as label for text area so fixed sceenshot
Comment #45
Gábor Hojtsy@andypost: great, I think this looks good. Needs upgrade path and tests for the upgrade path. I don't think this needs usability review in light of #1452188: New UI for string translation.
Comment #46
andypostI think we already have enough tests so just need to extend a current test-set to new storage, Tests for UI already fixed and needs to check new controls. Tests for import|export needs to be extended to detect plurals and their order.
The only possible upgrade path is to find a strings by their translations with plid or plural <> 0
OTOH no upgrade path needed because on D7->D8 upgrade to much strings are changed and translation needs re-roll. Also if strings are been translated with core's interface so there's no relation for plurals and upgrade gives nothing...
Comment #47
Gábor HojtsyAll right, first of all, very good patch. Very good! This is long overdue and it even follows Damien's thinking from mid-2009. Yeah! Once again I don't think we should fuss much about the UI here, since we have #1452188: New UI for string translation to turn the whole thing upside down anyway.
However, while I do agree that upgrades will need to re-import translations, there still can be translations for custom modules, etc., so if we can make an upgrade on a best effort basis to upgrade the plural translations (where it was stored in its ideal form), that would be superb. We'll not upgrade broken stuff, but we'll still go a great way. Tests for that would be great too. Let me know if you need help with any of that, I'm happy to help or find someone else to help! It would be basically about (1) adding an update function to migrate the data (2) add plural source strings and translations in core/modules/simpletest/tests/upgrade/drupal-7.language.database.php, (3) add tests in core/modules/simpletest/tests/upgrade/upgrade.language.test to check that the plural translations were upgraded to their new form properly in the DB.
Apart from that, only minor notes:
Would be good to document why \03 is the best choice? l10n_server uses \0 and above I think you uncovered msgfmt also uses that for .mo files, but in real testing above, you stated sqlite and PostgreSQL did not work with \0. So that would be good to document. In effect (a) what is \03 and (b) why is it a good choice.
I don't see a reason why this would not work with single plural formula languages. I think this @todo would need to be removed before the patch can land, right? :)
// Sort plural variants by their form index.
// Serialize plural variants in one string by LOCALE_PLURAL_DELIMITER.
I don't think there is a point in naming $english and $translation at this point, we can just pass them on to the function as-is?
(The larger import API will be reworked, so don't worry about long lines here or anything like that).
Why is that we don't need the target table anymore?
// Remember number of plural variants to optimize the export.
// Remember we did not have a plural number for the export.
Break the FAPI element to multiple lines please. The comment looks like was intended above the plural key? Maybe make it more specific:
// Add original text value and mark as non-plural.
submission
Break into multiple lines.
// Add a textarea for each plural variant.
Maybe make it a bit more friendly:
format_plural($i, 'First plural form', '@count. plural form')
// Serialize plural variants in one string by LOCALE_PLURAL_DELIMITER.
Update the code comment too above? It was inaccurate before too :)
Comment #48
Gábor HojtsySince you seem to have dropped the ball on this patch and are active on other issues, here is a fix with my suggestions from above. The attached patch solves my suggestions, but it does not add or change any functionality (interdiff also included).
The only place I had a question above on why we don't need the target table joined anymore I figured out myself. Basically, we stored the plural index info in target before, so we needed it joined, but now there is no reason to join it if we only need the source strings. Attached test passes the .po patches on my machine, should hopefully pass core tests.
I did look into the locale tests to see how much coverage there is for plurals, and the results are pretty said. They are imported in several .po files but then never checked for success (or attempted to be edited). So we need testing added there. That is coming up next.
Comment #49
Gábor HojtsyComment #50
Gábor HojtsyAdded plenty of test coverage for the plural functionality (since there was *none* before that actually checked it imported stuff or exported properly - not surprisingly since the export did not work unless you imported the sources).
The first test method does the following:
- import a French and Croatian translation file with plural translations
- check that the right translations are returned by format_plural() for proper counts (reworked/extended the plural index test)
The second one is back to back import/edit/add/export testing:
- import the same two .po files
- test that on export, the plurals retain their expected structure
- test that the plural shows up on the editing overview
- test that the plural has an editing screen with discrete input fields
- test modifying some of the translations
- add a new plural source string with format_plural() - this was not in the imported .po so this is the point where data/structure loss would have been happening up to before this patch
- save a complete set of translations for this new string
- export the whole thing again for both languages and check the edited and newly added strings are both in the structure expected
I think this is as full a test suite for import/add/edit/export/use-in-api for plurals as can be.
However, there is still no upgrade path or test for the upgrade path. That is still to do. @andypost, do you want to take it from here, or should I?
Comment #51
Gábor HojtsyFor reference, here is the data representation for correct and for broken storage.
Data stored properly
Files imported (Hungarian, Croatian):
Imported results (source and target table):
The source table maps count with additional numbers from 2 and up for the plural indexes. The target table maps translations to the source lid and the whole plural index/ordering system is maintained in the translation table (the main trigger for this issue). The parent lid's are stored in plid and the plural index counter is in plural. Singular values which do have plurals cannot be identified because they have the same characteristics as regular single translatable strings. So a singular string can only be identified by looking up if its lid is one of the plids.
Data stored broken
When the plural is not imported but just saved with format_plural() this information never ends up in the translation table (in part because only source strings are saved, in part because format_plural() will look strings up individually before the patch and will not send over plural information). So what we end up with is a broken state (if the above files are not imported, but we leave to format_plural() to fill in the source strings):
The same source strings are found per the plural formulas, but when translations are added on the UI, there is no plural information assigned, so:
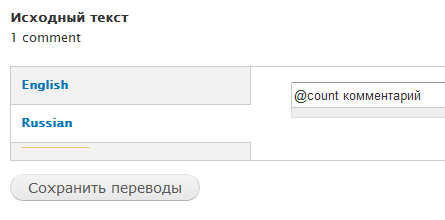
All strings look like simple standalone strings. The @count[2] gives away there was likely some plural stuff there and @count bajta is likely the parent (but not necessarily, there can be a standalone string with the same text, gettext supports that).
Edit: so when we want to export this, we get (for Croatian):
Yes, all strings become individual and [2] will not be removed from the last count because it is only removed when Drupal knows it was a plural and that Drupal added that in there. This is visibly very far from what we want to have to work.
Solution proposed in this patch
The suggested patch reorganized these as the following:
Note that (1) we identify the source string with its full identifier as per gettext (msgid and msgid_plural combined), (2) we store the translations related to that compound base string (3) we don't need to hack the translations with @count[2] and such, (4) we don't need to use any clunky chained storage (and can loose the extra columns used for that). The compound storage is good because we want to look them up together more often than not, we need to let people edit them together (something we never provided, but is provided by this patch) and we need to import/export them together. Using \03 allows for the least interference for text search/lookups.
Upgrade path
For the upgrade path, we'll not be able to upgrade previously improperly stored plurals (middle scenario), but we should be able to update properly stored values (first scenario). We can safely drop the plural and plid columns because they had no useful value to debug this problem at the first place.
Comment #52
Gábor HojtsyHere is some Croatian sample data for writing an upgrade path / test. Feel free to replace with a different but similarly complex language if you want to :) The existing languages we had in the dump did not seem to be good targets for this testing this complexity (they did not have enough plural forms). I'll really leave this alone for now, so feel free to pick up again :)
Comment #53
Gábor HojtsyMeh, wrong table name in dump :) This one should work :)
Comment #54
Gábor HojtsyAll right, given no other response, extended the patch with test coverage for the upgrade as well (additionally to the test coverage above to editing / data storage). Changes:
- Added sample translation for Catalan too (I pasted that in from localize.drupal.org, yes, it looks exactly like the English text, ask the Catalan people :)
- Added an upgrade function that enumerates all plurals, combines them and saved them according to the new storage; it also drops indexes and columns and recreates index where needed.
- Added tests in the upgrade path, so that it checks if the source and translations were all converted proper (we have a 2 variant and a 3 variant language, so nice variance for testing).
The upgrade tests pass locally. I think this is complete in terms of what we want to achieve, so let's get it reviewed, fixed if needed and then land :)
Comment #56
Gábor Hojtsy#1272840: Add upgrade path for language domains and validation landed in the meantime and used up our update function name. Rerolled :) (Even though #1222106: Unify language negotiation APIs, declutter terminology is likely going to land before this and we'll need to roll this again for another update function, but for now, we can prove it passes and works :).
Comment #58
Gábor HojtsyAnd #1222106: Unify language negotiation APIs, declutter terminology landed too. I did not expect this to be happening so soon :) Should have waited more :) There are no immediate locale updates on the horizon, so it looks safe to reroll this now and let it be reviewed :) Passes for me locally for the upgrades at least.
Comment #59
Gábor HojtsyAlso should have all the tests needed.
Comment #60
andypostAwesome!
@Gábor, thanx a lot! Now I know how to write upgrade tests!
Suppose we should remove and fetch DB faster
, s.context, s.locationComment #61
Gábor HojtsyLets rtbc only if the tests came back green at minimum :) your suggestion for the query also looks good. Will add that in.
Comment #63
Sutharsan CreditAttribution: Sutharsan commentedI experience no problem applying the patch. I do however fail to import a po file.
PDOException: SQLSTATE[42S22]: Column not found: 1054 Unknown column 'plid' in 'field list': INSERT INTO {locales_target} (lid, language, translation, plid, plural) VALUES (:db_insert_placeholder_0, ... ...) in _locale_import_one_string_db() (line 498 of /Users/erik/www/drupal8/core/includes/gettext.inc).'plid' and 'plural' are still used in code.
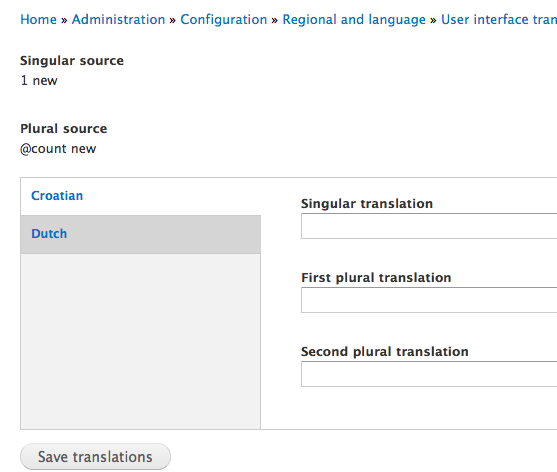
I would suggest different interface text on the plural translation page. See attachment. But we could postpone this till #1452188: New UI for string translation.
Comment #64
Gábor Hojtsy@Sutharsan: thanks for testing. Indeed I left over some plid/plural code in the DB import part. I did not run the plural tests locally, only the upgrade tests. Heh. Now removed those, ran both the plural and upgrade tests, and both ran fine for me, so it should be fine for .po imports definitely (the plural tests added with the patch are very extensive in that direction).
Also rolled against latest D8 checkout.
Please review/test/try again :)
Comment #65
Sutharsan CreditAttribution: Sutharsan commentedImport and export tested Ok with Dutch and Croatian. Now, waiting for the bot...
Comment #66
Gábor HojtsyPer @andypost's suggestion above, also removed the s.context and s.location columns from the query in the update as we don't need those pieces of information in the update at all.
Comment #67
Gábor HojtsyAny other concern, issue, feedback?
Comment #68
Gábor Hojtsy#66: 532512-plural-storage-66.patch queued for re-testing.
Comment #69
Gábor HojtsyWith added changelog entry. Please test/review and help move this forward unless you have any further issues with it. Don't leave it lingering around! :) Thank you!
Comment #70
andypostThis should be changed to <> see #1226796: Simplify not equal operator '!=' is not supported by all databases, must be '<>'
Suppose
plural >= 1is better, everything other is RTBCComment #71
Gábor HojtsyChanged != to <>. It is not possible for plural to be less than 0, so <> 0 and >= 1 should mean the same thing. However, <> 0 is what expresses that we are looking for items which have some plural denomination. This is explained in in the summary referenced from the update functions phpdoc.
Comment #72
andypostNow it's good to go!!!
Comment #73
kalman.hosszu CreditAttribution: kalman.hosszu commentedI tested the patch, and I think it's OK!
Comment #74
kalman.hosszu CreditAttribution: kalman.hosszu commentedSorry, just change the status to RTBC
Comment #75
xjmYAY we are finally supporting grammatical Russian plurals?
Over 80 chars.
Wraps a bit early.
I'll reroll to fix these because this patch is awesome.
20 days to next Drupal core point release.
Comment #76
xjmCouple other things so I don't forget:
Oops, a capitalization fix is needed here and in subsequent comments (so that we don't wonder why locale is goin' around putting lids on everything).
Typo here.
Comment #77
no_commit_credit CreditAttribution: no_commit_credit commentedThe use of the word "remembers" in the comments is also a bit anthropomorphic, but I left it because I couldn't think of a nice way to fix it without rewriting half the comments. ;)
Comment #78
Dries CreditAttribution: Dries commentedSpent a good 30 minutes looking at this patch and it looks good. Committed to 8.x.
Comment #79
Gábor HojtsyThanks! Added changelog entry at http://drupal.org/node/1478334 - off the sprint with this :) And now onto lots of interesting things this made possible:
- #1189184: OOP & PSR-0-ify gettext .po file parsing and generation
- #1445004: Implement customized translation bit on translations and
- #1452188: New UI for string translation
Help if welcome there!
Comment #80
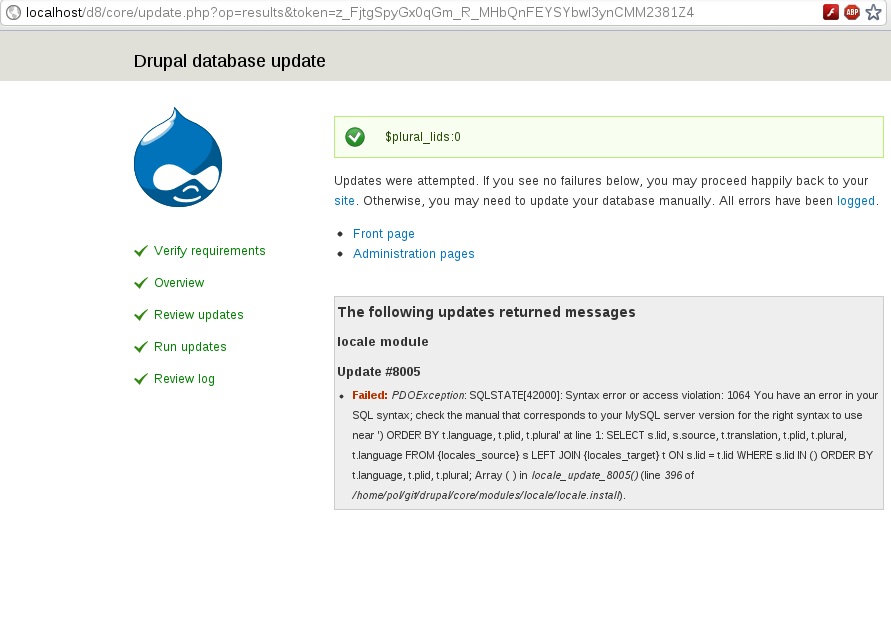
PolHi,
I've updated my Drupal 8 install and get an error (see screenshot). It happends when
$plural_lidsis empty.The patch add a test and checks if the array is not empty before continuing:
Comment #81
Gábor HojtsyGood catch! I'd use empty() though and remember we'd still need to make the database schema changes, so we cannot just drop out of the update function at that point just yet.
Comment #82
PolOk I'll work on it now.
Comment #83
PolHere's the updated version. I hope it's the good way to do it.
Comment #84
Gábor HojtsyLooks good on review. Lets run the tests too.
Comment #85
Gábor HojtsyI think this looks good. @andypost what do you think?
Comment #86
plachFixed trailing whitespace, otherwise unchanged.
16 days to next Drupal core point release.
Comment #87
andypostSuppose it's good patch looks big but it's purpose to skip string update if no plurals
Comment #88
Gábor HojtsyYes, it is just a huge block of indentation change really to wrap in that condition.
Comment #89
catchIf the existing upgrade tests didn't catch this, can we add some extra data so that they will? Looks like it would be necessary to have locale module enabled, but no plurals in the db unless I'm missing something.
Also bumping to critical since the ugprade path is broken.
Comment #90
catchComment #91
andypost@catch Are you sure we need tests for code in hook_update? This is just bug - missed if() in code-flow
Comment #92
catchYes, we need tests for updates, at least as much as most other places we have tests for.
While it's a missed if in this case, it means there's two code paths the upgrade can take and one isn't tested - we might find other bugs later on with the same update, or need to migrate the same data differently in a later update, so it's better to add the data now then it will cover any further changes as well.
Comment #93
Gábor HojtsyI agree with @catch. I think this would be easy to test also, we can add another test method that drops the translations before updating or just remove the plural translations. Then we'd get the empty set and fail before the patch and pass after.
Comment #94
Sutharsan CreditAttribution: Sutharsan commentedTest added as Gábor proposed.
The first patch only contains the test and must fail.
Comment #95
Sutharsan CreditAttribution: Sutharsan commentedSecond patch contains both the test and #86 and must pass.
Comment #96
Sutharsan CreditAttribution: Sutharsan commentedAnother try with the first patch.
Comment #98
Sutharsan CreditAttribution: Sutharsan commented#96 (test only) failed the test #95 (test + fix) passed the test. Both as expected. Status back to needs review.
Comment #99
Gábor HojtsyIn the interest of making this test future compatible, I'd use the same condition as the update, "WHERE plural <> 0", so if we add any more plural translations for testing other things lets say, then this would still accurately test the condition of no plurals (although it would not fail, since we fix the issue in the meantime).
Comment #100
Gábor HojtsyComment #101
Sutharsan CreditAttribution: Sutharsan commentedCondition changed. Comment touch-ups.
First patch must fail. Second patch must pass.
Comment #102
Gábor HojtsyLooks good. Note for reviewers: most of this patch is indenting lots of lines by two more spaces basically.
Comment #103
Sutharsan CreditAttribution: Sutharsan commentedWhich is easy to see using the git-diff -b option.
Comment #104
catchThanks for the test addition.
I've committed/pushed this to 8.x (adding parentheses to locale_update_8005() in the comment before commit in case anyone spots that after this goes in).
Comment #105
klonosThis issue was originally filed against 7.x (got pushed to D8 about a year ago). Is there anything that we can/should do that will benefit D7? Did we introduce API changes?
Comment #106
catchHmm, there'll be a change for translators (the addition of the plural string delimiter), and there's also a schema change. These probably need a change notification - at least the delimiter could use one, it's not really an API change but it's something we could document as part of the upgrade path.
I'm not sure how doable a backport is or not, so re-opening only for the change notification for now, if people think this is doable though, feel free to move it back to 7.x for that.
Comment #107
Gábor HojtsyThere was/is a change notification submitted as linked from the issue above. http://drupal.org/node/1478334 Please reopen if it does not look right. Since we needed to change storage models to support this, it is impossible to backport to D7 and be compatible with existing modules like l10n_update.
Comment #108
catchI missed the change notification, that looks great though.
Agreed this looks to intrusive to backport but worth checking :)
Comment #109.0
(not verified) CreditAttribution: commentedLink summary from below.
Comment #110
andypostFiled follow-up #2139467: format_plural() does not handle D7 translations with a plural form after @count
Comment #112
andypostLooks we need split l10n_server storage for "before d8" #2833830-11: Translation for third plural form